菜鸟学IT之python网页爬取多页爬取
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3002
0.从新闻url获取点击次数,并整理成函数
- newsUrl
- newsId(re.search())
- clickUrl(str.format())
- requests.get(clickUrl)
- re.search()/.split()
- str.lstrip(),str.rstrip()
- int
- 整理成函数
- 获取新闻发布时间及类型转换也整理成函数
import re
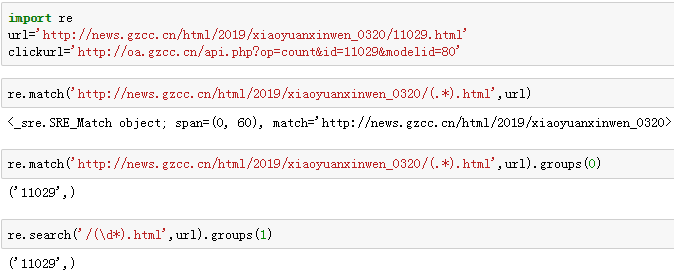
url='http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
clickurl='http://oa.gzcc.cn/api.php?op=count&id=11029&modelid=80'
re.match('http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/(.*).html',url)
re.match('http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/(.*).html',url).groups(0)
re.search('/(\d*).html',url).groups(1)
re.findall('(\d+)',url)
结果如下:
1.从新闻url获取新闻详情: 字典,anews
import requests
from bs4 import BeautifulSoup
from datetime import datetime
import re def click(url):
id=re.findall('(\d{1,5})',url)[-1]
clickUrl = 'http://oa.gzcc.cn/api.php?op=count&id=11029&modelid=80'.format(id)
resClick = requests.get(clickUrl)
newsClick = int(resClick.text.split('.html')[-1].lstrip("('").rstrip("');"))
return newsClick def newsdt(showinfo):
newsDate = showinfo.split()[0].split(':')[1]
newsTime = showinfo.split()[1]
newsDT = newsDate+' '+newsTime
dt = datetime.strptime(newsDT, '%Y-%m-%d %H:%M:%S') return dt def anews(url):
newsDetail = {}
res = requests.get(url)
res.encoding ='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
newsDetail['nenewsTitle'] =soup.select('.show-title')[0].text
showinfo = soup.select('.show-info')[0].text
newsDetail['newsDT']=newsdt(showinfo)
newsDetail['newsClick'] =click(newsUrl)
return newsDetail newsUrl='http://news.gzcc.cn/html/2005/xiaoyuanxinwen_0710/4.html'
anews(newsUrl)
结果:

2.从列表页的url获取新闻url:列表append(字典) alist
- 获取列表数据
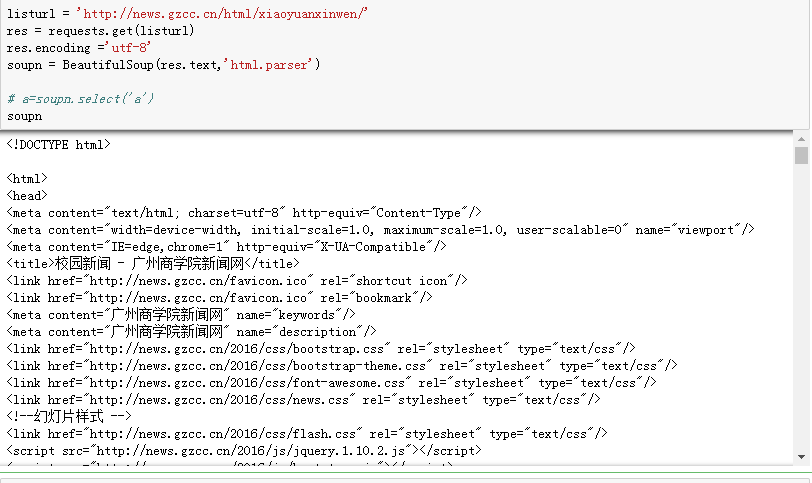
listurl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
res = requests.get(listurl)
res.encoding ='utf-8'
soupn = BeautifulSoup(res.text,'html.parser') # a=soupn.select('a')
soupn
2.过滤过滤数据,只获取列表的新闻信息
for news in soupn.select('li'):
if news.select('.news-list-title'):
print(news)
newsUrl = news.a['href']
print(news.a['href'])

3.获取整页信息
def alist(listUrl):
res = requests.get(listurl)
res.encoding ='utf-8'
soup = BeautifulSoup(res.text,'html.parser')
newsList =[]
for news in soupn.select('li'):
if len(news.select('.news-list-title'))>0:
newsUrl = news.select('a')[0]['href']
newsDesc = news.select('.news-list-description')[0].text
newsDict = anews(newsUrl)
newsDict['newsUrl'] = newsUrl
newsDict['description'] = newsDesc
newsList.append(newsDict)
return newsList listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
alist(listUrl)

3.生成所页列表页的url并获取全部新闻 :列表extend(列表) allnews
*每个同学爬学号尾数开始的10个列表页
- 获取多页信息
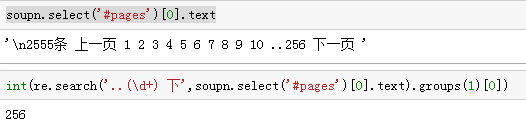
- 截取以学号尾数开始的10个列表页
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
allnews = alist(listUrl) for i in range(7,17): #学号为7,截取10页
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
allnews.extend(alist(listUrl)) len(allnews)

4.设置合理的爬取间隔
import time
import random
time.sleep(random.random()*3)
import time
import random
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
allnews = alist(listUrl) for i in range(1,170): #学号为7,截取10页
listUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
allnews.extend(alist(listUrl))
time.sleep(random.random()*3) #设置每3秒爬取一次
print(alist(listUrl)) len(allnews)
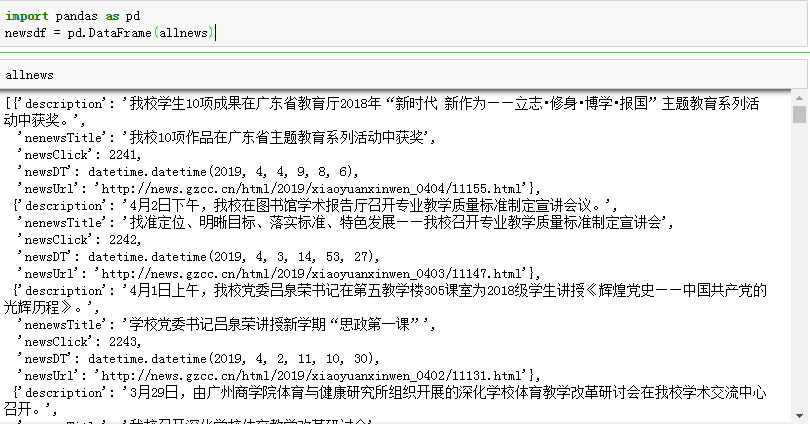
5.用pandas做简单的数据处理并保存
保存到csv或excel文件
newsdf.to_csv(r'F:\duym\爬虫\gzccnews.csv')
- 使用pandas函数整理爬取的数据
- 列表的形式打印数据
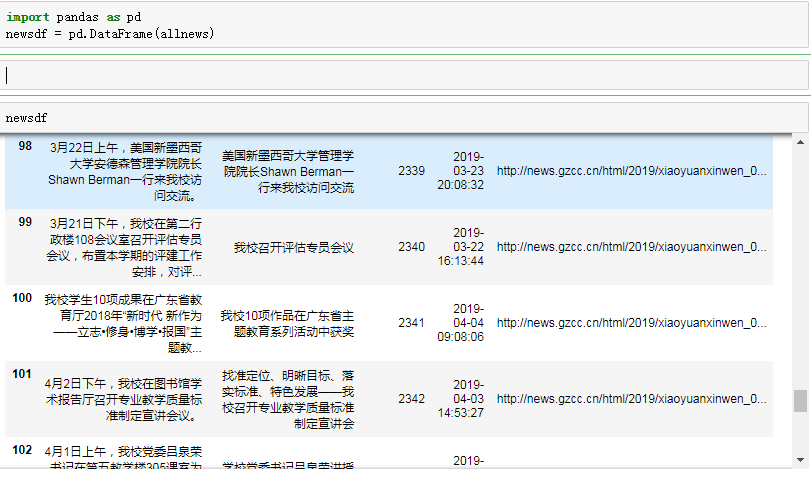
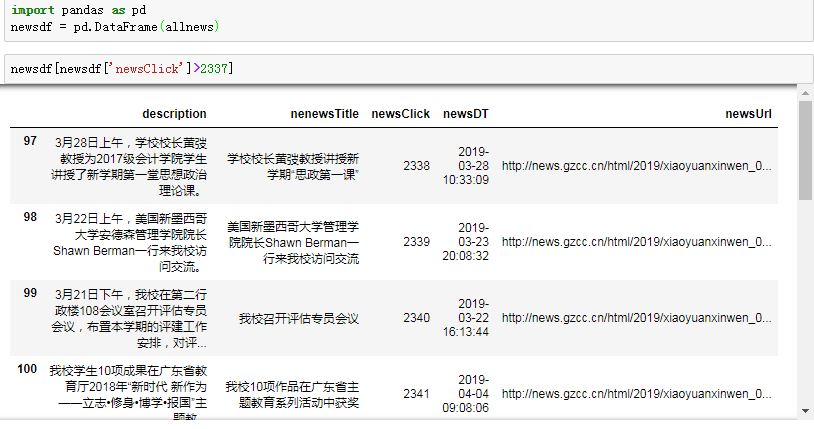
- 显示 “newsClick” 游览次数大于2337的新闻
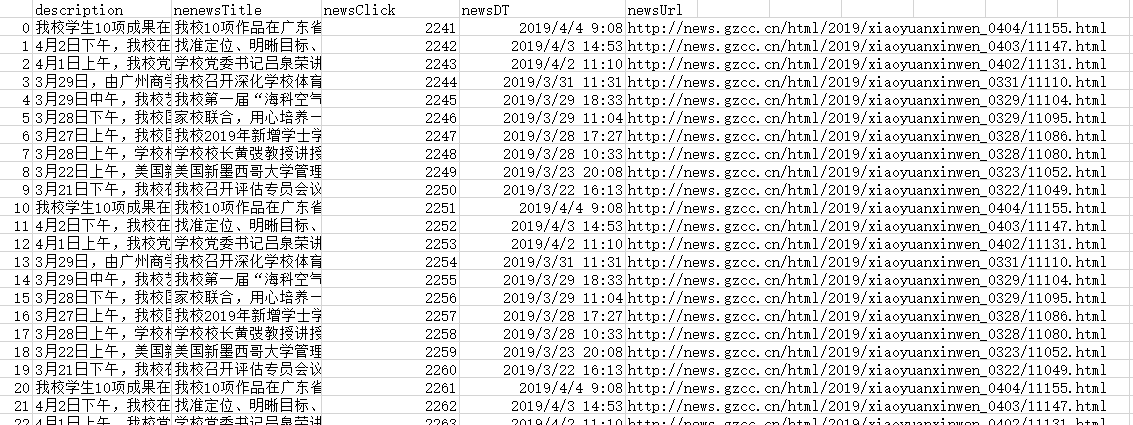
- 生成csv文件
newsdf.to_csv(r'E:\gzcc.csv')
菜鸟学IT之python网页爬取多页爬取的更多相关文章
- 菜鸟学IT之python网页爬取初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881 1. 简单说明爬虫原理 爬虫简单来说就是通过程序模拟浏览器放松请求站 ...
- python实现一个栏目的分页抓取列表页抓取
python实现一个栏目的分页抓取列表页抓取 #!/usr/bin/env python # coding=utf-8 import requests from bs4 import Beautifu ...
- 菜鸟学IT之python词云初体验
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822 1. 下载一长篇中文小说. 2. 从文件读取待分析文本. txt = ...
- python网页爬虫开发之五-反爬
1.头信息检查是否频繁相同 随机产生一个headers, #user_agent 集合 user_agent_list = [ 'Mozilla/5.0 (Windows NT 6.1; WOW64 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 初识python 之 爬虫:使用正则表达式爬取“古诗文”网页数据
通过requests.re(正则表达式) 爬取"古诗文"网页数据. 详细代码如下: #!/user/bin env python # author:Simple-Sir # tim ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- python使用requests库爬取网页的小实例:爬取京东网页
爬取京东网页的全代码: #爬取京东页面的全代码 import requests url="https://item.jd.com/2967929.html" try: r=requ ...
随机推荐
- 和逛微博、刷朋友圈一样玩转 GitHub
自打毕业之后,可以说每天打开 Github 或Email 看有没有 watch 项目的消息或者自己项目的 issue,然后在Explore 看看社区内项目的走势,紧接着开始写代码搬砖的工作,偶尔也会关 ...
- 【Spark篇】---SparkStreaming中算子中OutPutOperator类算子
一.前述 SparkStreaming中的算子分为两类,一类是Transformation类算子,一类是OutPutOperator类算子. Transformation类算子updateStateB ...
- DotNetCore跨平台~在appsettings.json里自定义配置项
回到目录 DotNetCore里一切都是依赖注入的,对于appsettings这个可扩展的配置对象也不例外,它位于项目根目录,一般在startup里去注册它,在类中通过构造方法注入来获取当前的对象,以 ...
- C++ 编程技巧笔记记录(持续更新)
C++是博大精深的语言,特性复杂得跟北京二环一样,继承乱得跟乱伦似的. 不过它仍然是我最熟悉且必须用在游戏开发上的语言,这篇文章用于挑选出一些个人觉得重要的条款/经验/技巧进行记录总结. 文章最后列出 ...
- SQL优化 MySQL版 -分析explain SQL执行计划与Extra
Extra 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 注:此文章必须有一定的Mysql基础,或观看执行计划入门篇传送门: https:.html 终于总结到哦SQK执行计划的最 ...
- 补习系列(17)-springboot mongodb 内嵌数据库
目录 简介 一.使用 flapdoodle.embed.mongo A. 引入依赖 B. 准备测试类 C. 完善配置 D. 启动测试 细节 二.使用Fongo A. 引入框架 B. 准备测试类 C.业 ...
- Java基础系列-equals方法和hashCode方法
原创文章,转载请标注出处:<Java基础系列-equals方法和hashCode方法> 概述 equals方法和hashCode方法都是有Object类定义的. publi ...
- C# 委托链(多播委托)
委托既可以封装一个方法,又可以对同一类型的方法进行封装,它就是多播委托 using System; using System.Collections.Generic; using System.Lin ...
- 学习day02
day021.结构标记 ***** 做布局 1.<header>元素 <header></header> ==> <div id="heade ...
- adb 查看 android手机的CPU架构
adb shell cat /proc/cpuinfo 当然要下载adb并配置好环境变量