solr6.6 配置拼音分词
1、下载拼音分析包
下载地址:pinyin.zip
解压后放在core下面的lib文件夹下面:
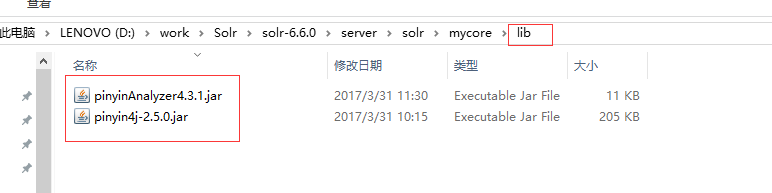
2、修改managed-schema配置文件
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
<filter class="com.shentong.search.analyzers.PinyinTransformTokenFilterFactory" minTermLenght="2" />
<filter class="com.shentong.search.analyzers.PinyinNGramTokenFilterFactory" minGram="1" maxGram="20" />
</analyzer>
</fieldType>
<field name="text" type="text_smartcn" termVectors="true" indexed="true" stored="true"/>
3、修改solrconfig.xml配置文件
增加如下:
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex="lucene-analyzers-smartcn-6.6.0.jar" />
<lib dir="./lib" regex=".*\.jar"/>

4、测试分析


solr6.6 配置拼音分词的更多相关文章
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程: Solr Admin中,选择Analysis,在FieldType中,选择text_en 左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词. ...
- docker环境下solr6.0配置(中文分词+拼音)
前言:这篇文章是基于之前的“linux环境下配置solr5.3详细步骤”(http://www.cnblogs.com/zhangyuan0532/p/4826740.html)进行扩展的.本篇的步骤 ...
- solr-6.4.2安装+分词器配置
一.solr安装 solr下载地址:http://archive.apache.org/dist/lucene/solr/6.4.2/ 1.解压solr软件包:tar xf solr-6.4.2.tg ...
- solr6.6初探之分词篇
关于solr6.6搭建与配置可以参考 solr6.6初探之配置篇 在这里我们探讨一下分词的配置 一.关于分词 1.分词是指将一个中文词语拆成若干个词,提供搜索引擎进行查找,比如说:北京大学 是一个词那 ...
- Elasticsearch拼音分词和IK分词的安装及使用
一.Es插件配置及下载 1.IK分词器的下载安装 关于IK分词器的介绍不再多少,一言以蔽之,IK分词是目前使用非常广泛分词效果比较好的中文分词器.做ES开发的,中文分词十有八九使用的都是IK分词器. ...
随机推荐
- 如何利用好chrome控制台这个神器好好调试javascript代码
上面的文章已经大致介绍了一下console对象具体有哪些方面以及基本的应用,下面简单介绍一下如何利用好chrome控制台这个神器好好调试javascript代码(这个才是我们真正能用到实处的地方) 1 ...
- Codeforces #107 DIV2 ABCD
A #include <map> #include <set> #include <list> #include <cmath> #include &l ...
- springboot整合jsp模板
springboot整合jsp模板 在使用springboot框架里使用jsp的时候,页面模板使用jsp在pom.xnl中需要引入相关的依赖,否则在controller中无法返回到指定页面 〇.搭建s ...
- 【 总结 】linux中test命令详解
test命令在bash shell脚本中经常以中括号([])的形式出现,而且在脚本中使用字母来表示比符号表示更专业,出错率更低. 测试标志 代表意义 文件名.文件类型 -e 该文件名是否存在 -f 该 ...
- 经常用到的Eclipse快捷键(更新中....)
alt+shift+s:弹出Source选项,用于生成get,set等方法. Ctrl+E:快速显示当前Editer的下拉列表 alt+shift+r:重命名 Ctrl+Shift+→/Ctrl+Sh ...
- poj 3230(初始化。。动态规划)
Travel Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 4353 Accepted: 1817 Descriptio ...
- nodejs 服务器重新启动
在 我们开发node 应用的时候,一但你的应用已经启动了,这个时候如果你修改了服务端的文件,那么要是这个修改起作用,你必须手动停止服务然后再重新启动,这在开发过程中无 疑是很烦人的一件事,最好是有一个 ...
- 「转」基于Jmeter和Jenkins搭建性能测试框架
搭建这个性能测试框架是希望能够让每个人(开发人员.测试人员)都能快速的进行性能测试,而不需要关注性能测试环境搭建过程.因为,往往配置一个性能环境可能需要很长的时间. 1.性能测试流程 该性能测试框架工 ...
- 洛谷——P1405 苦恼的小明
P1405 苦恼的小明 题目描述 黄小明和他的合伙人想要创办一所英语培训机构,注册的时候要填一张个人情况的表格,在身高一栏小明犯了愁. 身高要求精确到厘米,但小明实在太高了,无法在纸上填下这么长的数字 ...
- SQL*Loader-605: Non-data dependent ORACLE error occurred — load discontinued
It seems the tablespace is full.