MySQL学习(5)
三 触发器
对某个表进行某种操作(如:增删改查),希望触发某个动作,可以使用触发器。
1.创建触发器
create trigger trigger1_before_insert_tb1 before insert on tb1 for each row
begin
...
end before可以换成after, insert可以换成delete,update.

在想tb1插入数据后,tb2结果:
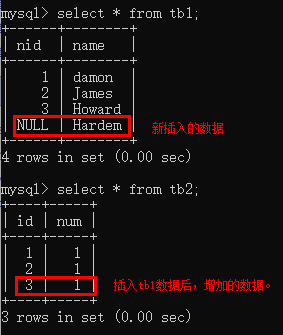
触发器获得用户提交的数据:
create trigger tri_after_insert_tb1 after insert on tb1 for each row
begin
NEW.nid (为用户新提交过来的 tb1.nid的值)
NEW.name(为用户新提交过来的tb1.name的值) insert into tb2(num) values(NEW.nid);
end create trigger tri_after_delete_tb1 after delete on tb1 for each row
begin
OLD.nid (为删除的tb1.nid的值)
OLD.name(为删除的tb1.name的值) insert into tb2(num) values(OLD.nid);
end create trigger tri_after_update_tb1 after update on tb1 for each row
begin
NEW.nid (为用户新提交过来的 tb1.nid的值)
NEW.name(为用户新提交过来的tb1.name的值)
OLD.nid (为删除的tb1.nid的值)
OLD.name(为删除的tb1.name的值) insert into tb2(num) values(OLD.nid),(New.nid);
end
2. 删除触发器
drop trigger tri_after_insert_tb1;
3. 使用触发器:调用触发条件即可。
四 事务
事务多用于原子性操作,一旦某个操作引起了错误或者警告,可以回滚到原来的状态,保持数据库的完整性。
delimiter //
create procudureprocudure1(
OUT return varchar(20)
)
begin
declare exit handler for sqlexception --发生错误会执行的程序代码块
begin
-- ERROR
set return = "Error";
rollback;
end; declare exit handler for sqlwarning --发生警告会执行的程序代码块
begin
-- WARNING
set return = "Warn";
rollback;
end; start transaction;
delete from table1;
insert into table2(name) values('damon'); --如果这条命令和上条命令出现错误或警告,会执行上面错误代码块或警告代码块
commit; -- SUCCESS
set return = "Success "; --如果ransaction代码块中没有错误发生,就会执行到这条命令 END//
delimiter ;
四 函数
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。 LOWER(str)
变小写 UPPER(str)
变大写 LTRIM(str)
返回字符串 str ,其引导空格字符被删除。
RTRIM(str)
返回字符串 str ,结尾空格字符被删去。
SUBSTRING(str,pos,len)
获取字符串子序列 LOCATE(substr,str,pos)
获取子序列索引位置 REPEAT(str,count)
返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。
若 count <= 0,则返回一个空字符串。
若str 或 count 为 NULL,则返回 NULL 。
REPLACE(str,from_str,to_str)
返回字符串str 以及所有被字符串to_str替代的字符串from_str 。
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
RIGHT(str,len)
从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N)
返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str)
返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar ');
-> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx' 部分内置函数
内置函数
参考博客:https://www.cnblogs.com/wupeiqi/articles/5713323.html 十分感谢!
自建函数 delimiter //
create function f1(arg1 int, arg2 int)
returns int
begin
declare num int;
set nuim = arg1 + arg2;
return (num);
end//
delimiter ; 在创建函数的时候报错: This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
需要 调用命令: set global log_bin_trust_function_creators=TRUE;就可以了。

函数与存储过程的不同点:
1.函数里不能返写SQL语句,存储过程可以。
但函数中可以这样使用:
set id = 0;
select nid into id form student where name = 'damon';
2.函数通过return返回返回值,存储过程通过参数返回返回值。
删除函数:
drop fucntion f1;
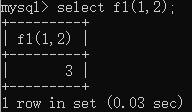
调用函数;
select f1(1, 2);
五 索引(重要程度 *******)
索引是数据库中专门用于快速查找数据的一种数据结构,其内部使用红黑查找树,所以可以快速查找到数据。功能:建立索引加快寻找;约束;
种类:
普通索引:加速查找;
唯一索引:加速查找,约束列数据不能重复,可以为null;
主键索引:加速查找,约束列数据不能重复,不可以为Null;
组合索引:多列组合创建一个索引文件;
1. 普通索引
create table tb1(
nid int not null auto_increment primary key,
name varchar(20) not null,
index ix_name(name)
} --创建表时,将name列作为索引
创建表+索引
create index ix_name on tb1(name)
创建索引
drop ix_name on tb1
删除索引
show index from tb1
查看索引
注意:如果创建索引是BLOB或者TEXT类型时,需要指定长度。
2. 唯一索引
create table tb2(
nid int null auto_increment primary key,
name varchar(20) not null,
unique ix_name(name)
)
创建表+唯一索引
create unique index ix_name on tb2(name)
创建唯一索引
drop unique index ix_name on tb2
删除唯一索引
3. 主键索引
创建主键索引就是创建主键;
4. 组合索引
在创建索引的时候,选择两个列名。规则:最左匹配,根据创建索引时,最左侧的列名为根据,判断是否走索引。
a. 普通组合索引: 无约束。
b. 联合位移组合索引:有约束,两列数据同时不相同,才能插入。
5. 执行计划
相对比较准确表达当前SQL运行状况。
explain SQL语句;
type = ALL 全数据表扫描;效率低。
type = index 全索引表扫描;效率低。
在SQL语句后加 limit 会提高效率。
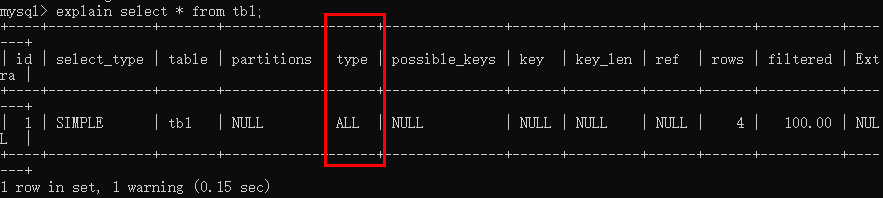
type 是 ALL 或者Index时,都是有优化的余地。
6. 如何命中索引
(1) like '%xx': select * from tb where name like '%om' 不走索引 like 'da%'走索引
(2) 使用函数:select * from tb where reverse(name) = 'damon'
(3) 使用or :select* from tb where nid = 1 or name = 'damon'; nid和name都是索引就不走索引
(4) 类型不一致:select * from tb where name = 1;
(5) 使用!=: select * from tb where name != 'damon';当name不是主键时,不会走索引,反之,走索引;
(6) 使用 >:select * from tb where name > 'alex'; 如果主键是索引还是整数类型,则还是会走索引。
(7) 使用order by:select email from tb order by email,name;当根据索引排序时,如果映射不是索引,则不会走索引。如果对主键排序,则还是走索引;
(8) 注意事项
a. 避免使用select * ;
b. 尽量使用char代替varchar;
c. 表的字段顺序固定长度的字段优先;
d. 当时用多个条件查询时,多使用组合索引代替单个索引;
e. 尽量使用短索引;
f. 使用连接(JOIN)代替子查询(Sub-Queries);
g. 连表时注意条件类型须一致;
h. 索引散列(重复少), 不适合建索引。例:性别;
六 分页
如果数据量比较大时,越到后面使用limit分页的效率越低,解决方案:
where nid > 1000000 limit x, m 直接跳过前1000000数据,往下扫描。
七 慢日志查询
1. 内存中配置MySQL自动记录慢日志。
2. 写一个配置文件*.ini, 在配置文件中修改,然后重启。
指定配置文件: mysqld --default files = D:/mysql/default.ini;
3. 在修改时,建议两种方式都修改。
slow_query_log = ON 开启慢日志记录
long_query_time = 0.5 超过此时间,则记录
slow_query_log_file = D:/usr/slow.log 日志文件路径
log_queries_not_using_indexes = ON 为使用索引的搜索是否记录
4.查看慢日志
mysqldumpslow -s at -a /usr/slow.log
MySQL学习(5)的更多相关文章
- 我的MYSQL学习心得(一) 简单语法
我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(二) 数据类型宽度
我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(三) 查看字段长度
我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(四) 数据类型
我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(五) 运算符
我的MYSQL学习心得(五) 运算符 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- 我的MYSQL学习心得(六) 函数
我的MYSQL学习心得(六) 函数 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(七) 查询
我的MYSQL学习心得(七) 查询 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(八) 插入 更新 删除
我的MYSQL学习心得(八) 插入 更新 删除 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得( ...
- 我的MYSQL学习心得(九) 索引
我的MYSQL学习心得(九) 索引 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(十) 自定义存储过程和函数
我的MYSQL学习心得(十) 自定义存储过程和函数 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心 ...
随机推荐
- Python---7函数(调用&定义函数)
函数 Python内置了很多有用的函数,我们可以直接调用. 要调用一个函数,需要知道函数的名称和参数,比如求绝对值的函数abs(),只有一个参数.可以直接从Python的官方网站查看文档: http: ...
- hexo博客的学习笔记
这篇文章主要的作用是作为 .md文件打开,内部的格式为一个初学者对hexo以及markdown语法运用的笔记 1.Hexo的写文格式 最开始为文章的属性部分,以三横杠-开始,-结束.里面记录了文章的标 ...
- 不同浏览器Cookie大小
一.浏览器允许每个域名所包含的 cookie 数:Microsoft 指出 Internet Explorer 8 增加 cookie 限制为每个域名 50 个,但 IE7 似乎也允许每个域名 50 ...
- 【转载】Java DecimalFormat 用法
转载只供个人学习参考,以下查看请前往原出处:http://blog.csdn.net/wangchangshuai0010/article/details/8577982 我们经常要将数字进行格式化, ...
- ODI学习资料
ODI12.2.1.4入门指南:https://docs.oracle.com/en/middleware/fusion-middleware/data-integrator/12.2.1.4/ind ...
- 初识Arduino
Arduino是一款便捷灵活.方便上手的开源电子原型平台.包含硬件(各种型号的Arduino板)和软件(Arduino IDE).由一个欧洲开发团队于2005年冬季开发.其成员包括Massimo Ba ...
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
- 『配置』服务器搭建 Office Online Server2016 实现文档预览 番外 错误篇
安装一个或多个角色.角色服务或功能失败.找不到源文件.请再次尝试在新的“添加角色和功能”向导会话中安装角色.角色服务或功能,然后在向导的“确认”页中单击“指定备用源路径”以指定安装所需的源文件的有效位 ...
- 负载均衡框架 ribbon 二
Ribbon 负载均衡机制 官方文档地址:https://github.com/Netflix/ribbon/wiki/Working-with-load-balancers 1. Ribbon 内置 ...
- 开源字体不香吗?五款 GitHub 上的爆红字体任君选
作者:HelloGitHub-ChungZH 在编程时,用一个你喜欢的字体可以大大提高效率,越看越舒服.这篇文章就推荐 5 个在 GitHub 上优秀的字体供大家选择吧! 1. Iosevka 网站: ...