sqluldr2 学习心得
前言
最近正在做一个项目,需要导出数据库中的表,单数数据库中有很多带有虚拟列的表,而且表中的数据非常的庞大,有些表中的数据上亿条,项目经理让我研究如何快速导出这些数据。
下面是我研究的一些经历:
(1)、我先使用plsql developer导出dmp(实际上是通过emp导出),但是不能导出带有虚拟列的表,导出的速度有点慢;
(2)、使用plsql developer自带的导出功能,如图所示:

该方法可以导出虚拟列,但是导出的速度很慢,比dmp还慢,大约是方法(1)的2倍时间。
(3)、使用数据泵 DataPump导出,该方法可以导出虚拟列,而且速度还可以,但是如果导出远程库数据的时候,需要用dblink,而且需要很高的权限(相当于dba的权限),所以该方法也被排除。
山重水复疑无路,柳暗花明又一村,我发现了sqluldr2这个神器,又能导出虚拟列,而且导入导出的速度非常快,下面我们就进入正题。
sqluldr2下载与安装
1、软件下载地址:最新软件下载地址:http://www.anysql.net/software/sqluldr.zip
下载完后并解压会生成4个文件
sqluldr2.exe 用于32位windows平台;
sqluldr2_linux32_10204.bin 适用于linux32位操作系统;
sqluldr2_linux64_10204.bin 适用于linux64位操作系统;
sqluldr264.exe 用于64位windows平台。
2、直接在cmd上运行(我的sqluldr文件放在H盘里,我电脑是64位,所以使用sqluldr264)
首先,你必须安装oracle,没有安装oracle,sqluldr2不能运行,运行完后出现如下的界面,这样就证明可以成功运行。
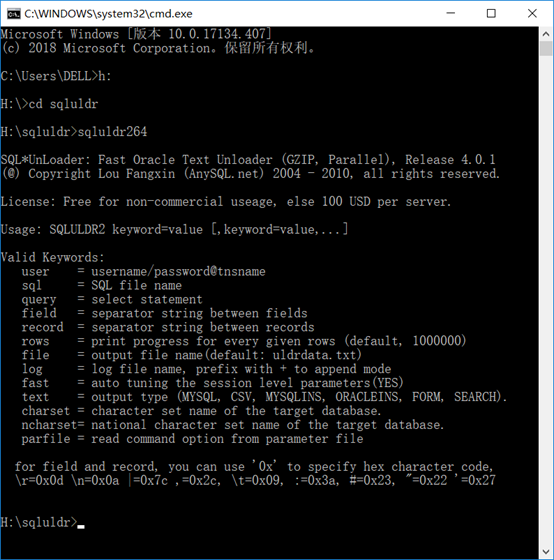
sqluldr2 导出
1、导出命令的主要参数
user=用户名/密码@ip地址:1521/服务 ,如果是本地库,可以只写 用户名和密码:eg:user=用户名/密码
query=”sql查询语句”
head=yes|no 是否导出表头
file=文件存放路径(该文件可以写很多后缀: .txt .csv .dmp 等等,我发现,导出.dmp文件速度快)
table=查询的表名 有这句话,sqluldr2会自动生成一个.ctl文件,导入的时候会用到();
Field:分隔符,指定字段分隔符,默认为逗号; 比如:field=# 在选择分隔符时,一定不能选择会在字段值中出现的字符组合,如常见的单词等,很多次导入时报错,回过头来找原因时,都发现是因为分隔符出现在字段值中了。
record:分隔符,指定记录分隔符,默认为回车换行,Windows下的换行;
quote:引号符,指定非数字字段前后的引号符;
charset:字符集,执行导出时的字符集,一般有UTF8、GBK等;
2、常规的命令
sqluldr264 user=zxx/zxx123@127.0.0.1:1521/orcl query="select * from mv_xlsymx1 where ysyddm='00001H'" head=yes file=h:\mx.csv log=+h:\tem.log
3、可以使用sql参数
可以使用sql参数代替query
sqluldr264 user=zxx/zxx sql=h:\test.sql head=yes file=h:\mx.csv
test.sql是提前维护好的一个文件,文件的内容为sql语句。
4、带有table参数的导出
sqluldr264 user=zxx/zxx query="select * from mv_xlsymx1 where ysyddm='00001H'" table=mv_xlsymx1 head=yes file=h:\mx.csv
它会生成一个.ctl文件(mv_xlsymx1_sqlldr.ctl,默认生成在sqluldr文件下,我的就生成在h:\sqluldr\ mv_xlsymx1_sqlldr.ctl)
5、指定.ctl文件生成的位置
sqluldr264 user=zxx/zxx query="select * from mv_xlsymx1 where ysyddm='00001H'" table=mv_xlsymx1 control=h:\mx.ctl head=yes file=h:\mx.csv
6、带有日志log参数
当集成sqluldr2在脚本中时,就希望屏蔽上不输出这些信息,但又希望这些信息能保留,这时可以用“LOG”选项来指定日志文件名。
sqluldr264 user=zxx/zxx query="select * from mv_xlsymx1 where ysyddm='00001H'" head=yes file=h:\mx.csv log=+h:\tmp.log
注意:这里的log路径要写上“+”
sqlldr 导入
1、我们先查看sqlldr的帮助文档

2、导入之前,我们需要先熟悉一下.ctl文件
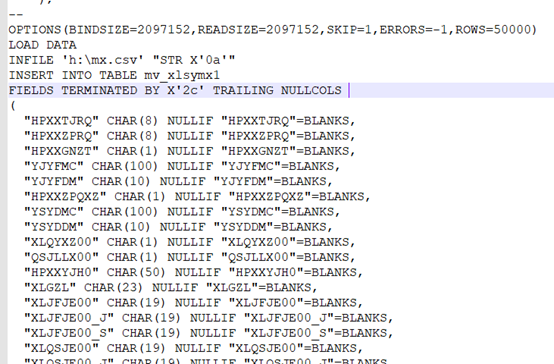
characterset :字符集, 一般使用字符集 AL32UTF8,如果出现中文字符集乱码时,改成 ZHS16GBK。
fields terminated by 'string':文本列分隔符。当为tab键时,改成'\t',或者 X'09';空格分隔符 whitespace,换行分隔符 '\n' 或者 X'0A';回车分隔符 '\r' 或者 X'0D';默认为'\t'。
optionally enclosed by 'char':字段包括符。当为 ' ' 时,不把字段包括在任何引号符号中;当为 "'" 时,字段包括在单引号中;当为'"'时,字段在包括双引号中;默认不使用引用符。
fields escaped by 'char':转义字符,默认为'\'。
trailing nullcols:表字段没有对应的值时,允许为空。
append into table "T_USER_CTRL" -- 操作类型
-- 1) insert into --为缺省方式,在数据装载开始时要求表为空
-- 2) append into --在表中追加新记录
-- 3) replace into --删除旧记录(相当于delete from table 语句),替换成新装载的记录
-- 4) truncate into --删除旧记录(相当于 truncate table 语句),替换成新装载的记录skip=1 :表示插入数据时,跳过第一行(标题),从第二行开始导入;
3、sqluldr 导入处理
3.1、基本的导入语句
sqlldr userid=hxj/hxj control=h:\sqluldr\mv_xlsymx1_sqlldr.ctl data=h:\mx.csv rows=1000
如果是本地库,可以直接只用 用户名/密码;
如果是远程库,需要将userid写全 userid=用户名/密码@ip:1521/服务名
比如:userid=zxx/zxx123@10.3.36.110:1521/orcl,填写自己远程库地址
3.2、带有日志log参数
sqlldr userid=hxj/hxj control=h:\sqluldr\mv_xlsymx1_sqlldr.ctl data=h:\mx.csv log=h:\log\mx.log rows=1000
注意:这里的log的路径不能写“+”;
4、虚拟列处理
sqluldr2导出数据的时候,如果该表中含有虚拟列,你导出的时候没有过滤掉虚拟列,比如:select * from 带有虚拟列的表,那么你要对这些虚拟列进行处理,否则导入的时候回报错。
我发现了三种处理方法:
4.1、在虚拟列后面加上filler,将这一列过滤掉。
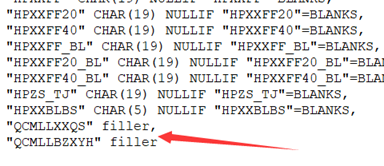
4.2、将.ctl文件中的虚拟列删除掉就可以了

4.3、在导出的时候,不导出虚拟列
比如,不写select * from 表名
直接将不是虚拟列的列名写出来 select id,name from 表名
5、使用并行处理
5.1 未使用并行处理
sqlldr userid=hxj/hxj control=h:\ctl\qsddlqymx1_cyqs.ctl data=h:\qsddlqymx1_cyqs.dmp log=h:\log\qsddlqymx1_cyqs.log
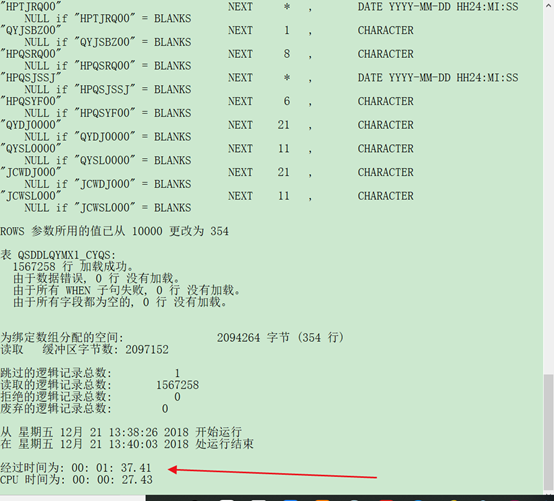
1567258条数据大概需要 一分半
5.2、使用并行处理数据
需要在导入语句中加入 direct=true parallel=true,如下所示:
sqlldr userid=hxj/hxj control=h:\ctl\qsddlqymx1_cyqs.ctl data=h:\qsddlqymx1_cyqs.dmp log=h:\log\qsddlqymx1_cyqs.log direct=true parallel=true
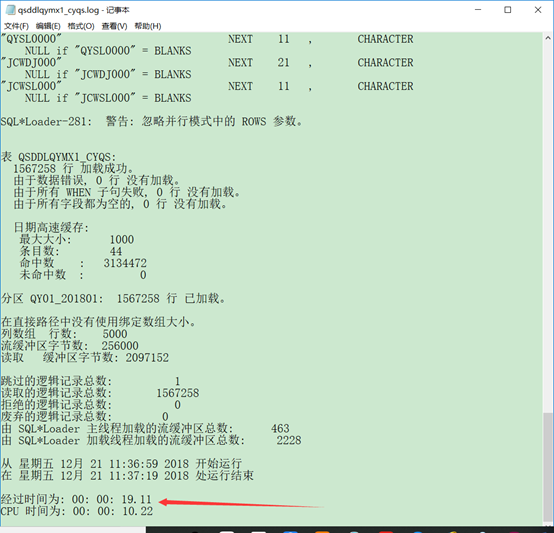
并行能更快的导入数据,1567258条数据大概20秒,但是有缺点(我测试的时候发现的,可能有别的解决方法)
(1):首先.ctl文件必须是append into table 表名;
(2):需要导入的表不能有索引。
这是我写的第一篇博客,望看客老爷们多多指教。
sqluldr2 学习心得的更多相关文章
- 我的MYSQL学习心得(一) 简单语法
我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(二) 数据类型宽度
我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(三) 查看字段长度
我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(四) 数据类型
我的MYSQL学习心得(四) 数据类型 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(五) 运 ...
- 我的MYSQL学习心得(五) 运算符
我的MYSQL学习心得(五) 运算符 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据 ...
- 我的MYSQL学习心得(六) 函数
我的MYSQL学习心得(六) 函数 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(七) 查询
我的MYSQL学习心得(七) 查询 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
- 我的MYSQL学习心得(八) 插入 更新 删除
我的MYSQL学习心得(八) 插入 更新 删除 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得( ...
- 我的MYSQL学习心得(九) 索引
我的MYSQL学习心得(九) 索引 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...
随机推荐
- Hbasewindows系统下启动报错及解决办法
今天在本地windows电脑上,装pinpoint时,需要先安装一个Hbase数据库,按照教程下载启动Hbase数据库时,却启动报错:java.io.IOException: Could not lo ...
- 《深入理解Nginx:模块开发与架构解析》读书笔记
1.nginx的特点:快.扩展性强.可靠性强.内存低消耗.支持高并发.热部署.开源免费 2.nginx由master进程来管理多个(CPU数)worker进程 3.配置按功能分,有4类: 1)用于调试 ...
- Redhat中关于httpd仓库安装的简要步骤
创建repo-server: yum install httpd yum install httpd -y < -y 表示在安装过程中与界面交互时自动答复yes >sys ...
- Ubuntu 16.04上搭建CDH5.16.1集群
本文参考自:<Ubuntu16.04上搭建CDH5.14集群> 1.准备三台(CDH默认配置为三台)安装Ubuntu 16.04.4 LTS系统的服务器,假设ip地址分布为 192.168 ...
- SpringBoot与数据访问
pom依赖: <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- 【洛谷p1605】迷宫
(还记得我昨天大概没人看到的博客(我删辽)吗qwq,2019.4.14下午交的qwq 那篇博客大致内容就是:我提交楼上这道题,交了好久好久好久好久 现在我告诉你,那次评测还N/A着呢qwq) tqlq ...
- MVC实战之排球计分(六)—— 使用EF框架,创建Controller,生成数据库。
在上篇博客我们写到,此软件的数据库连接我们使用的是EF框架,code first模式下, 通过模型类,在创建controller的时候直接生成数据库,完成数据库的连接,与操作. 在使用EF框架之前,我 ...
- input 标签的 disabled 和 readonly 属性
首先这两种属性都会使显示出来的文本框不能输入. disabled 属性:规定禁用 input 元素.被禁用的 input 元素既不可用,也不可点击和编辑,使用 tab 键时将会被跳过,用户的所有操作对 ...
- 在idea中用tomcat远程部署调试
适用于生产环境下的调试. 1.catalina配置 在服务器的bin下创建setenv.sh,内容如下 1099是jmx,最后是服务器ip 2.启动tomcat ./catalina.sh jpda ...
- Pyhon中运算符的使用
1. a & b python中的&延续了C/C++的含义,表示位运算. 例如 3 & 4:3&5:6&7 3 & 4 = (011)2 & ( ...