吴裕雄 python 机器学习——混合高斯聚类GMM模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import mixture
from sklearn.metrics import adjusted_rand_score
from sklearn.datasets.samples_generator import make_blobs def create_data(centers,num=100,std=0.7):
X, labels_true = make_blobs(n_samples=num, centers=centers, cluster_std=std)
return X,labels_true #混合高斯聚类GMM模型
def test_GMM(*data):
X,labels_true=data
clst=mixture.GaussianMixture()
clst.fit(X)
predicted_labels=clst.predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true,predicted_labels)) # 用于产生聚类的中心点
centers=[[1,1],[2,2],[1,2],[10,20]]
# 产生用于聚类的数据集
X,labels_true=create_data(centers,1000,0.5)
# 调用 test_GMM 函数
test_GMM(X,labels_true)
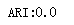
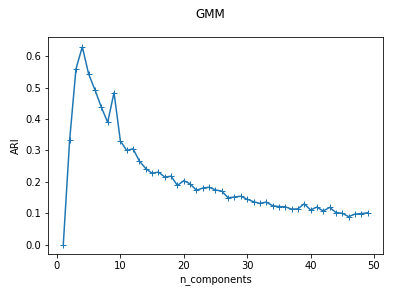
def test_GMM_n_components(*data):
'''
测试 GMM 的聚类结果随 n_components 参数的影响
'''
X,labels_true=data
nums=range(1,50)
ARIs=[]
for num in nums:
clst=mixture.GaussianMixture(n_components=num)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
## 绘图
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(nums,ARIs,marker="+")
ax.set_xlabel("n_components")
ax.set_ylabel("ARI")
fig.suptitle("GMM")
plt.show() # 调用 test_GMM_n_components 函数
test_GMM_n_components(X,labels_true)
def test_GMM_cov_type(*data):
'''
测试 GMM 的聚类结果随协方差类型的影响
'''
X,labels_true=data
nums=range(1,50) cov_types=['spherical','tied','diag','full']
markers="+o*s"
fig=plt.figure()
ax=fig.add_subplot(1,1,1) for i ,cov_type in enumerate(cov_types):
ARIs=[]
for num in nums:
clst=mixture.GaussianMixture(n_components=num,covariance_type=cov_type)
clst.fit(X)
predicted_labels=clst.predict(X)
ARIs.append(adjusted_rand_score(labels_true,predicted_labels))
ax.plot(nums,ARIs,marker=markers[i],label="covariance_type:%s"%cov_type) ax.set_xlabel("n_components")
ax.legend(loc="best")
ax.set_ylabel("ARI")
fig.suptitle("GMM")
plt.show() # 调用 test_GMM_cov_type 函数
test_GMM_cov_type(X,labels_true)

吴裕雄 python 机器学习——混合高斯聚类GMM模型的更多相关文章
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——超大规模数据集降维IncrementalPCA模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——数据预处理正则化Normalizer模型
from sklearn.preprocessing import Normalizer #数据预处理正则化Normalizer模型 def test_Normalizer(): X=[[1,2,3, ...
- 吴裕雄 python 机器学习——数据预处理标准化MaxAbsScaler模型
from sklearn.preprocessing import MaxAbsScaler #数据预处理标准化MaxAbsScaler模型 def test_MaxAbsScaler(): X=[[ ...
- 吴裕雄 python 机器学习——数据预处理标准化StandardScaler模型
from sklearn.preprocessing import StandardScaler #数据预处理标准化StandardScaler模型 def test_StandardScaler() ...
- 吴裕雄 python 机器学习——数据预处理标准化MinMaxScaler模型
from sklearn.preprocessing import MinMaxScaler #数据预处理标准化MinMaxScaler模型 def test_MinMaxScaler(): X=[[ ...
- 吴裕雄 python 机器学习——支持向量机线性分类LinearSVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——数据预处理字典学习模型
from sklearn.decomposition import DictionaryLearning #数据预处理字典学习DictionaryLearning模型 def test_Diction ...
- 吴裕雄 python 机器学习——数据预处理流水线Pipeline模型
from sklearn.svm import LinearSVC from sklearn.pipeline import Pipeline from sklearn import neighbor ...
随机推荐
- npm run build 打包后,如何运行在本地查看效果
目前,使用vue-cli脚手架写了一个前端项目,之前一直是使用npm run dev 在8080端口上进行本地调试.项目已经进行一半了,今天有时间突然想使用npm run build进行上线打包,试试 ...
- maven编译package慢
mvn package编译出现连接不上mvn库的问题: [root@localhost nnnnn]# mvn package[INFO] Scanning for projects...Downlo ...
- Reading Notes : 180213 计算机的硬件构成与处理流程
读书<计算机组成原理>,<鸟哥的Linux私房菜基础篇> 基本上接触过计算机的人,都多少知道计算机的具体构成,但是真正能讲明白的却说了很多,本节将讲解一下计算机的基本硬件构成和 ...
- QLViewController在iOS7下的自定义
原文来自:QLViewController在iOS7下的自定义 原先的项目使用了quicklook framework,用于在iPhone上浏览各类文件,除了txt文本会有乱码的问题,其他文件的显示都 ...
- 如何编写及运行JS
JS也是一种脚本语言,他可以有两种方式在HTML页面进行引入,一种是外联,一种是内部. 外联JS的写法为: <script src="相对路径"></ ...
- module.exports与exports的联系与区别
首先说明他们是啥? 在CommonJS规范中,exports和module.exports这两个对象是把某一模块化文件中的属性和方法暴露给外部模块的接口(说法可能不准确),外部模块通过require引 ...
- 『ACM C++』 Codeforces | 1066B - Heaters
今日不写日感,直接扔上今日兴趣点: 新研究称火星曾经有一个巨大的地下水系统 链接:https://mbd.baidu.com/newspage/data/landingsuper?context=%7 ...
- SQL Server公用表达式CET递归查询所有上级数据
with cte as( select bianma,fjbm from #tree where chkDisabled='true' union all select t.bianma,t.fjbm ...
- Java 8 – Map排序
前提 Map是Java中最常用的集合类之一,这里整理了关于HashMap的排序 (关于List的排序,请查看Collections.sort()的doc或源码). 将无序的HashMap借助Strea ...
- md5加密+盐方式一
这种方法是采用随机生成盐值加入password中组合成的新密码,下面是md5+盐的一个工具类,直接导入使用即可! 工具类 package com.oracle.utils; import java.s ...