记一次python写爬虫爬取学校官网的文章
有一位老师想要把官网上有关数字化的文章全部下载下来,于是找到我,使用python来达到目的
首先先查看了文章的网址
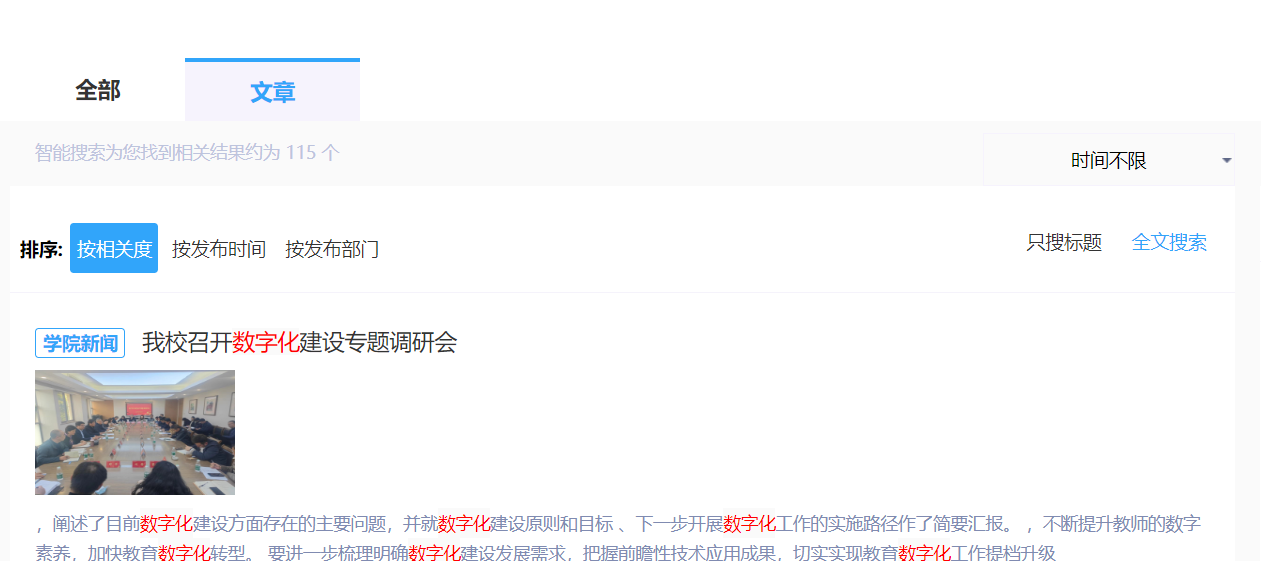
获取了网页的源代码发现一个问题,源代码里面没有url,这里的话就需要用到抓包了,因为很明显这里显示的内容是进行了一个请求,所以只能通过抓包先拿到请求的url从而获得每一篇文章对应的url,获取到了之后使用python全部下载到了一个文本文件中
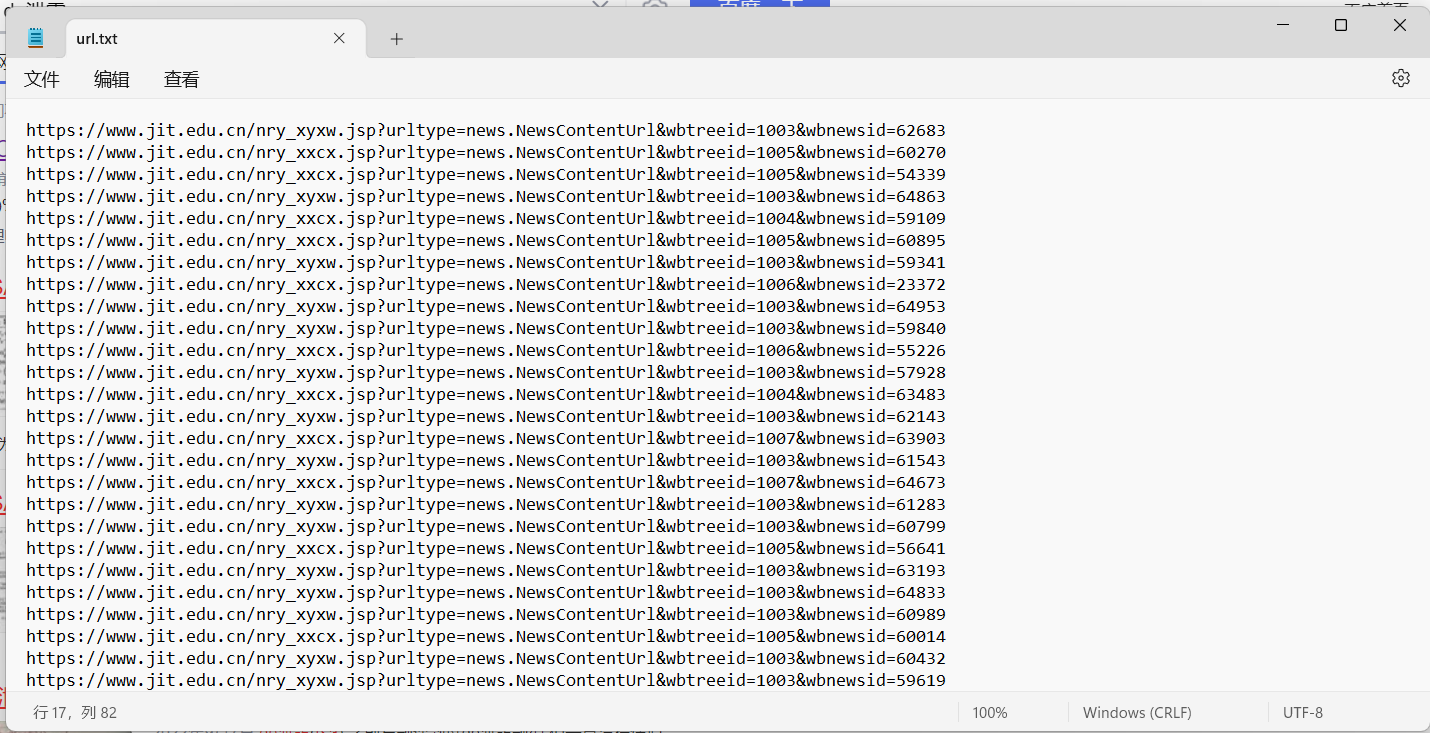
这时候我们就拿到了所有文章的链接,接下来写函数实现获取网页源代码,这里用到了python爬虫常用的BeautifulSoup处理源代码很方便以下是实现的代码:
def html(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67",
"cookie": "Hm_lvt_af43f8d0f4624bbf72abe037042ebff4=1640837022; __gads=ID=a34c31647ad9e765-22ab388e9bd6009c:T=1637739267:S=ALNI_MYCjel4B8u2HShqgmXs8VNhk1NFuw; __utmc=66375729; __utmz=66375729.1663684462.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __gpi=UID=000004c822cf58b2:T=1649774466:RT=1663684463:S=ALNI_Ma3kL14WadtyLP-_lSQquhy_w85ag; __utma=66375729.1148601284.1603116839.1663684462.1663687392.2; .Cnblogs.AspNetCore.Cookies=CfDJ8NfDHj8mnYFAmPyhfXwJojexiKc4NcOPoFywr0vQbiMK4dqoay5vz8olTO_g9ZwQB7LGND5BBPtP2AT24aKeO4CP01olhQxu4EsHxzPVjGiKFlwdzRRDSWcwUr12xGxR89b_HFIQnmL9u9FgqjF6CI8canpEYxvgxZlNjSlBxDcWOzuMTVqozYVTanS-vAUSOZvdUz8T2XVahf8CQIZp6i3JzSkaaGUrXzEAEYMnyPOm5UnDjXcxAW00qwVmfLNW9XO_ITD7GVLrOg-gt7NFWHE29L9ejbNjMLECBdvHspokli6M78tCC5gmdvetlWl-ifnG5PpL7vNNFGYVofGfAZvn27iOXHTdHlEizWiD83icbe9URBCBk4pMi4OSRhDl4Sf9XASm7XKY7PnrAZTMz8pvm0ngsMVaqPfCyPZ5Djz1QvKgQX3OVFpIvUGpiH3orBfr9f6YmA7PB-T62tb45AZ3DB8ADTM4QcahO6lnjjSEyBVSUwtR21Vxl0RsguWdHJJfNq5C5YMp4QS0BfjvpL-OvdszY7Vy6o2B5VCo3Jic; .CNBlogsCookie=71474A3A63B98D6DA483CA38404D82454FB23891EE5F8CC0F5490642339788071575E9E95E785BF883C1E6A639CD61AC99F33702EF6E82F51D55D16AD9EBD615D26B40C1224701F927D6CD4F67B7375C7CC713BD; _ga_3Q0DVSGN10=GS1.1.1663687371.1.1.1663687557.1.0.0; Hm_lvt_866c9be12d4a814454792b1fd0fed295=1662692547,1663250719,1663417166,1663687558; Hm_lpvt_866c9be12d4a814454792b1fd0fed295=1663687558; _ga=GA1.2.1148601284.1603116839; _gid=GA1.2.444836177.1663687558; __utmt=1; __utmb=66375729.11.10.1663687392"}
response = requests.get(url, headers=head) # 获取网页信息
response.encoding = 'utf-8'
#html = response.text #所有内容
content = response.content.decode()
#匹配文章标题
pattern2 = r'"pageTitle" content="(.*?)">'
match2 = re.search(pattern2, content)
#标题
bt = match2.group(1)
soup = BeautifulSoup(content,'html.parser')
#内容
nr=soup.get_text()
write(bt,nr)
伪造一个header的头,因为学校官网设置的有简易的反爬机制,所以需要伪装成正常的浏览器访问,写一个简单的正则匹配文章的标题作为txt的文件名
现在拿到了标题和文章内容就可以写入文本了
创建文本文件并写入内容代码:
def write(bt,nr):
with open(r'C:\Users\13777\Desktop\猜猜看\1\\'+bt+'.txt','w',encoding='utf-8') as f:
f.write(nr)
with open(r'C:\Users\13777\Desktop\猜猜看\1\\'+bt+'.txt','r',encoding='utf-8') as f:
lines = f.readlines()
# 切片方法,从第4行开始,到倒数第2行结束
new_lines = lines[67:-1]
with open(r'C:\Users\13777\Desktop\猜猜看\1\\'+bt+'.txt','w',encoding='utf-8') as f:
f.writelines(new_lines)
print('yes')
with open(r'C:\Users\13777\Desktop\猜猜看\url.txt') as t:
for line in t.readlines():
url = line.strip()
html(url)
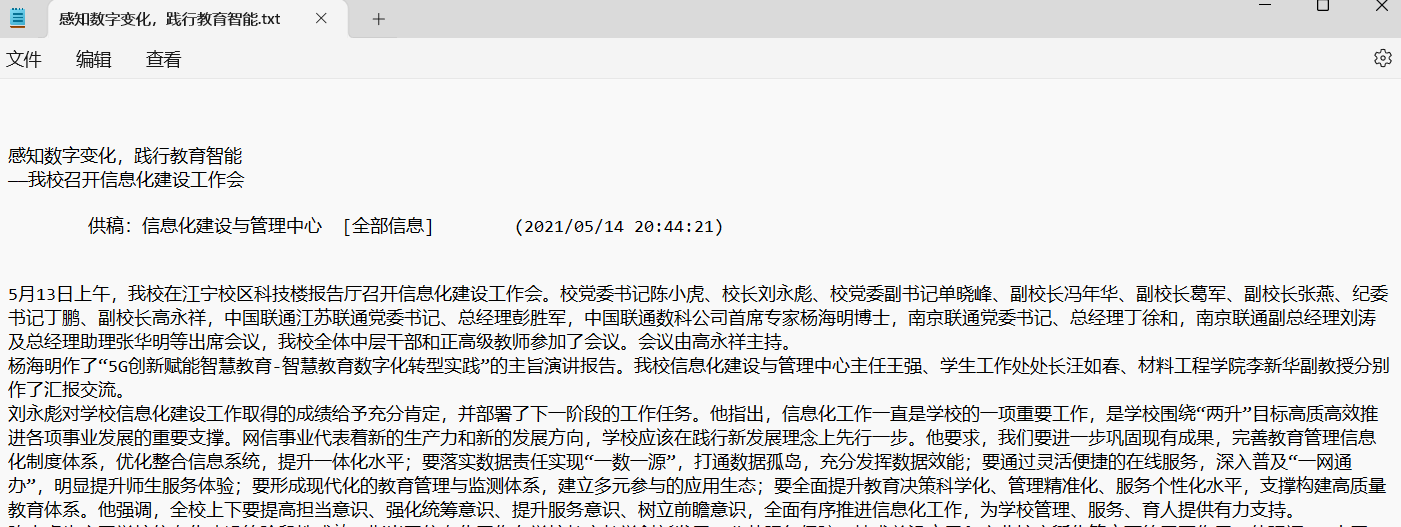
这里遇到一个问题就是经过BeautifulSoup处理后的内容前面有一段是没有任何作用的文本,于是写入文本再进行切片把前面没有用处的文本去掉,剩下的都是文章的内容
最终实现的效果:

记一次python写爬虫爬取学校官网的文章的更多相关文章
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- Python写爬虫-爬甘农大学校新闻
Python写网络爬虫(一) 关于Python: 学过C. 学过C++. 最后还是学Java来吃饭. 一直在Java的小世界里混迹. 有句话说: "Life is short, you ne ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- python学习(十六)写爬虫爬取糗事百科段子
原文链接:爬取糗事百科段子 利用前面学到的文件.正则表达式.urllib的知识,综合运用,爬取糗事百科的段子先用urllib库获取糗事百科热帖第一页的数据.并打开文件进行保存,正好可以熟悉一下之前学过 ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- Python写爬虫爬妹子
最近学完Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据.解析数据.保存数据.下面一一来讲. 1.下载数据 首先打 ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
随机推荐
- css3样式pointer-events,点击穿透和海市蜃楼的效果
css样式pointer-events pointer-events 是CSS3的一个属性,支持的值非常多,其中大部分都是和SVG有关.目前只了解 none 这个值, 其他值后续要补上. pointe ...
- JS刷题自制参考知识
(建议复制到本地,需要看的时候打开Typora,大纲点击要查的内容即可,我一般记不清某个方法的时候就查一下.) 基础 Typescript TypeScript是一个开源的.渐进式包含类型的JavaS ...
- 在Windows平台上利用CMD命令行来压缩和解压缩.tar.gz压缩包
解压命令: tar -xzvf dwt.tar.gz -C tmp/ 上述命令将dwt.tar.gz压缩包解压到tmp/文件夹 压缩命令: tar -czvf dwt.tar.gz dwt/ 上述命令 ...
- Sql Server代理作业、定时任务
需求: 本次需求为每15分钟获取一次思路为,创建结果表,代理作业定时更新数据并存入结果表,后端只需要调用结果表数据数据,如果超期不同的天数则给出不同的提示信息,因为没有触发点,所以用到了本文内容. 右 ...
- HGD2-LSP选择集专题-网络整理
[Visual Lisp]图元选择集专题 图元选择集专题 ;;★★★01.选择集操作★★★ (setq ss (ssadd));;创建一个空选择集 (ssadd (car(entsel)) ss);; ...
- ReentrantLock源码阅读
默认构造方法初始化同步器为非公平同步器 /** * Creates an instance of {@code ReentrantLock}. * This is equivalent to usin ...
- SQLServer自带备份优劣分析
众所周知, SQL Server自身的"维护计划"可以实现自动备份数据库. 既然这样,那还有必要使用第三方专业备份软件吗? 本文以[护卫神·好备份专业版]为例,分析两者之间的优劣. ...
- 抑制stable_secret读取关键信息
如何抑制stable_secret读取关键的"net.ipv6.conf.all.stable_secret"消息? 您可以/dev/null使用以下命令抑制额外的不需要的消息或将 ...
- 【新版】使用 go-cqhttp 扫码登录,一键接入 ChatGPT 机器人到 QQ 群
目录 项目效果 安装 go-cqhttp 虚拟文件 启动 ChatGPT 项目效果 由于 ChatGPT 目前只能在漂亮国使用,所以想要在国内使用 ChatGPT 必然险阻重重 不仅时时刻刻要跟企鹅公 ...
- Android笔记--监听短信内容
监听短信内容 就比如说是在我们用一个软件需要使用"获取验证码"的功能时,能够跟短信的验证码互通,实现较为完整的登录功能: 监听短信内容主要是利用了contentObserver实现 ...