记一次python写爬虫爬取学校官网的文章
有一位老师想要把官网上有关数字化的文章全部下载下来,于是找到我,使用python来达到目的
首先先查看了文章的网址
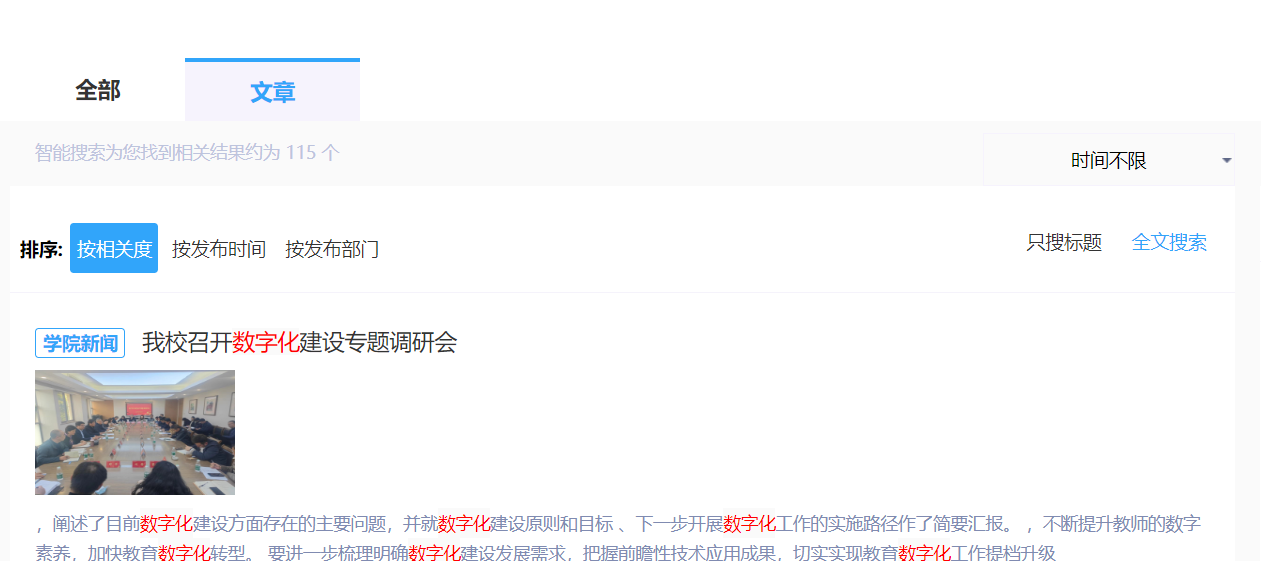
获取了网页的源代码发现一个问题,源代码里面没有url,这里的话就需要用到抓包了,因为很明显这里显示的内容是进行了一个请求,所以只能通过抓包先拿到请求的url从而获得每一篇文章对应的url,获取到了之后使用python全部下载到了一个文本文件中
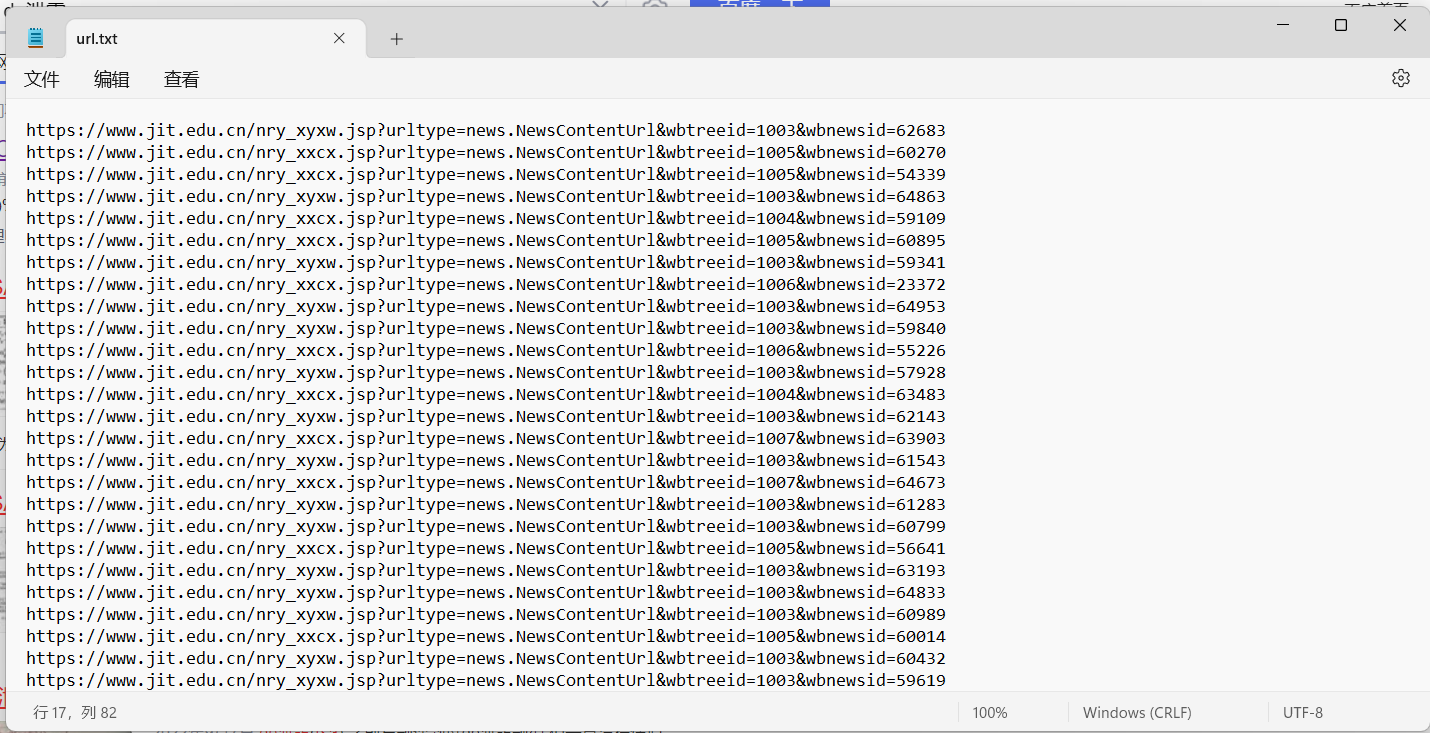
这时候我们就拿到了所有文章的链接,接下来写函数实现获取网页源代码,这里用到了python爬虫常用的BeautifulSoup处理源代码很方便以下是实现的代码:
def html(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.67",
"cookie": "Hm_lvt_af43f8d0f4624bbf72abe037042ebff4=1640837022; __gads=ID=a34c31647ad9e765-22ab388e9bd6009c:T=1637739267:S=ALNI_MYCjel4B8u2HShqgmXs8VNhk1NFuw; __utmc=66375729; __utmz=66375729.1663684462.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __gpi=UID=000004c822cf58b2:T=1649774466:RT=1663684463:S=ALNI_Ma3kL14WadtyLP-_lSQquhy_w85ag; __utma=66375729.1148601284.1603116839.1663684462.1663687392.2; .Cnblogs.AspNetCore.Cookies=CfDJ8NfDHj8mnYFAmPyhfXwJojexiKc4NcOPoFywr0vQbiMK4dqoay5vz8olTO_g9ZwQB7LGND5BBPtP2AT24aKeO4CP01olhQxu4EsHxzPVjGiKFlwdzRRDSWcwUr12xGxR89b_HFIQnmL9u9FgqjF6CI8canpEYxvgxZlNjSlBxDcWOzuMTVqozYVTanS-vAUSOZvdUz8T2XVahf8CQIZp6i3JzSkaaGUrXzEAEYMnyPOm5UnDjXcxAW00qwVmfLNW9XO_ITD7GVLrOg-gt7NFWHE29L9ejbNjMLECBdvHspokli6M78tCC5gmdvetlWl-ifnG5PpL7vNNFGYVofGfAZvn27iOXHTdHlEizWiD83icbe9URBCBk4pMi4OSRhDl4Sf9XASm7XKY7PnrAZTMz8pvm0ngsMVaqPfCyPZ5Djz1QvKgQX3OVFpIvUGpiH3orBfr9f6YmA7PB-T62tb45AZ3DB8ADTM4QcahO6lnjjSEyBVSUwtR21Vxl0RsguWdHJJfNq5C5YMp4QS0BfjvpL-OvdszY7Vy6o2B5VCo3Jic; .CNBlogsCookie=71474A3A63B98D6DA483CA38404D82454FB23891EE5F8CC0F5490642339788071575E9E95E785BF883C1E6A639CD61AC99F33702EF6E82F51D55D16AD9EBD615D26B40C1224701F927D6CD4F67B7375C7CC713BD; _ga_3Q0DVSGN10=GS1.1.1663687371.1.1.1663687557.1.0.0; Hm_lvt_866c9be12d4a814454792b1fd0fed295=1662692547,1663250719,1663417166,1663687558; Hm_lpvt_866c9be12d4a814454792b1fd0fed295=1663687558; _ga=GA1.2.1148601284.1603116839; _gid=GA1.2.444836177.1663687558; __utmt=1; __utmb=66375729.11.10.1663687392"}
response = requests.get(url, headers=head) # 获取网页信息
response.encoding = 'utf-8'
#html = response.text #所有内容
content = response.content.decode()
#匹配文章标题
pattern2 = r'"pageTitle" content="(.*?)">'
match2 = re.search(pattern2, content)
#标题
bt = match2.group(1)
soup = BeautifulSoup(content,'html.parser')
#内容
nr=soup.get_text()
write(bt,nr)
伪造一个header的头,因为学校官网设置的有简易的反爬机制,所以需要伪装成正常的浏览器访问,写一个简单的正则匹配文章的标题作为txt的文件名
现在拿到了标题和文章内容就可以写入文本了
创建文本文件并写入内容代码:
def write(bt,nr):
with open(r'C:\Users\13777\Desktop\猜猜看\1\\'+bt+'.txt','w',encoding='utf-8') as f:
f.write(nr)
with open(r'C:\Users\13777\Desktop\猜猜看\1\\'+bt+'.txt','r',encoding='utf-8') as f:
lines = f.readlines()
# 切片方法,从第4行开始,到倒数第2行结束
new_lines = lines[67:-1]
with open(r'C:\Users\13777\Desktop\猜猜看\1\\'+bt+'.txt','w',encoding='utf-8') as f:
f.writelines(new_lines)
print('yes')
with open(r'C:\Users\13777\Desktop\猜猜看\url.txt') as t:
for line in t.readlines():
url = line.strip()
html(url)
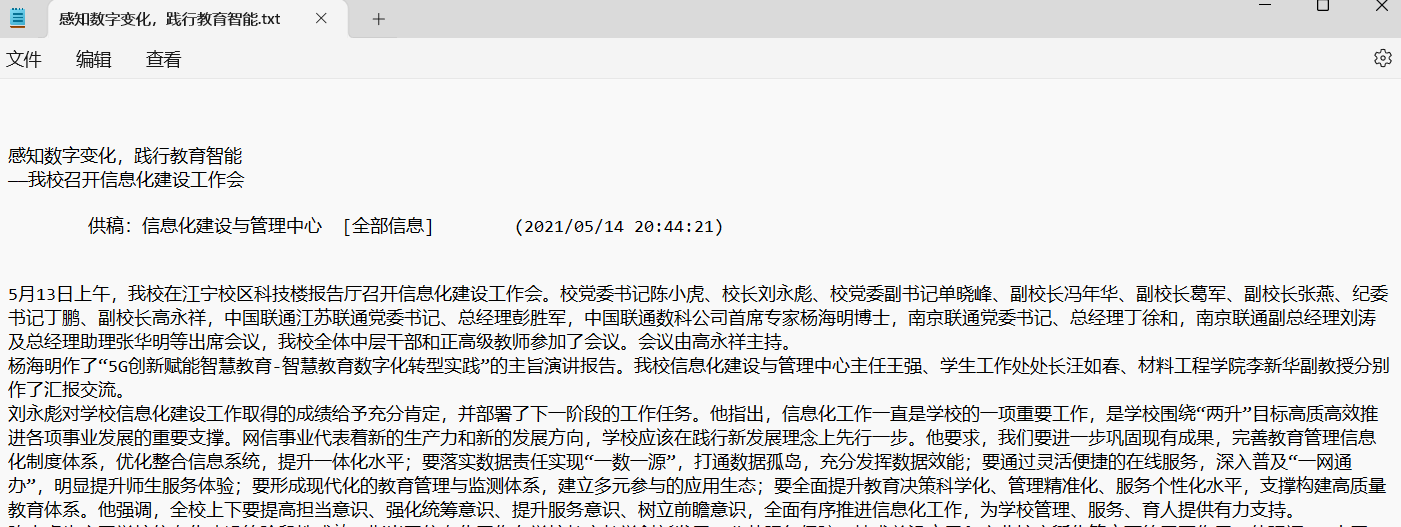
这里遇到一个问题就是经过BeautifulSoup处理后的内容前面有一段是没有任何作用的文本,于是写入文本再进行切片把前面没有用处的文本去掉,剩下的都是文章的内容
最终实现的效果:

记一次python写爬虫爬取学校官网的文章的更多相关文章
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- Python写爬虫-爬甘农大学校新闻
Python写网络爬虫(一) 关于Python: 学过C. 学过C++. 最后还是学Java来吃饭. 一直在Java的小世界里混迹. 有句话说: "Life is short, you ne ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- python学习(十六)写爬虫爬取糗事百科段子
原文链接:爬取糗事百科段子 利用前面学到的文件.正则表达式.urllib的知识,综合运用,爬取糗事百科的段子先用urllib库获取糗事百科热帖第一页的数据.并打开文件进行保存,正好可以熟悉一下之前学过 ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- Python写爬虫爬妹子
最近学完Python,写了几个爬虫练练手,网上的教程有很多,但是有的已经不能爬了,主要是网站经常改,可是爬虫还是有通用的思路的,即下载数据.解析数据.保存数据.下面一一来讲. 1.下载数据 首先打 ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
随机推荐
- char值转换为int怎么才能不是ASCII值
直接将char类型的变量强制转换为int类型是不行的,那样只会传递变量所对应的ASCII码 怎么才能将char类型转换为int类型呢?String类型的可以通过方法转换为int类型.那是不是可以将ch ...
- Web _Servlet(url-pattern)的配置与优先级
url-pattern的配置方式有三种: 1.完全路径匹配:以 '/' 开始 例: /ServletDemo1 , /aaa/ServletDemo2 , /aa/bb/ServletDemo3 ...
- FCC 高级算法题 对称差分
Symmetric Difference 创建一个函数,接受两个或多个数组,返回所给数组的 对等差分(symmetric difference) (△ or ⊕)数组. 给出两个集合 (如集合 A = ...
- 8-WebShell总结
WebShell 1.webshell介绍 在计算机科学中,Shell 俗称壳(用来区别"核"),是指"为使用者提供操作界面"的软件(命令解释器).类似于win ...
- pip安装报错 cannot uninstall a distutils installed project
sudo pip install --ignore-installed xxx 在安装jupyter notebook的时候,遇到了这个问题,于是上网搜索,搜到了靠谱答案github解决方案 sudo ...
- uglifyjs-webpack-plugin配置
项目使用vuecli3搭建,在vue.config.js文件中进行配置,主要配置了去除线上环境的打印信息. 首先安装插件, 执行命令 npm install uglifyjs-webpack-plug ...
- windows系统下使用java语言,在mysql数据库中做定时数据备份、删除
有这样一个业务需求,需要将数据归档的表每月定时备份,并且删除之前表中的数据,话不多说,直接上代码! 注意:这种方法适合数据量小,业务要求不高的场景! 项目采用SpringBoot + MyBatis ...
- windows下 mstsc 远程Ubuntu 图形界面
安装及设置xrdp ------------------------------------------------------ touch ~/installXrdp.sh cat > ~/ ...
- Nginx http 文件服务器 中文名称文件乱码以及不能访问下载问题 (解决全过程)
书接上文: 在Windows 环境下使用 Nginx 搭建 HTTP文件服务器 实现文件下载 全步骤(详细) _ 发现的中文乱码问题,终于自己解决了! ^_^ Nginx http 文件服务器 中文名 ...
- java生态下的后端开发都有哪些技术栈?
前言 我08年毕业,那时(2003-2010)C#还比较时髦的,大学跟着老师进修的,毕业后就从事winform窗体应用程序开发.慢慢的web网站兴起,就转到aps.net开发,再到后来就上了另一艘船( ...