深度学习--LSTM网络、使用方法、实战情感分类问题
深度学习--LSTM网络、使用方法、实战情感分类问题
1.LSTM基础
长短期记忆网络(Long Short-Term Memory,简称LSTM),是RNN的一种,为了解决RNN存在长期依赖问题而设计出来的。
LSTM的基本结构:

2.LSTM的具体说明
LSTM与RNN的结构相比,在参数更新的过程中,增加了三个门,由左到右分别是遗忘门(也称记忆门)、输入门、输出门。
图片来源:

1.点乘操作决定多少信息可以传送过去,当为0时,不传送;当为1时,全部传送。
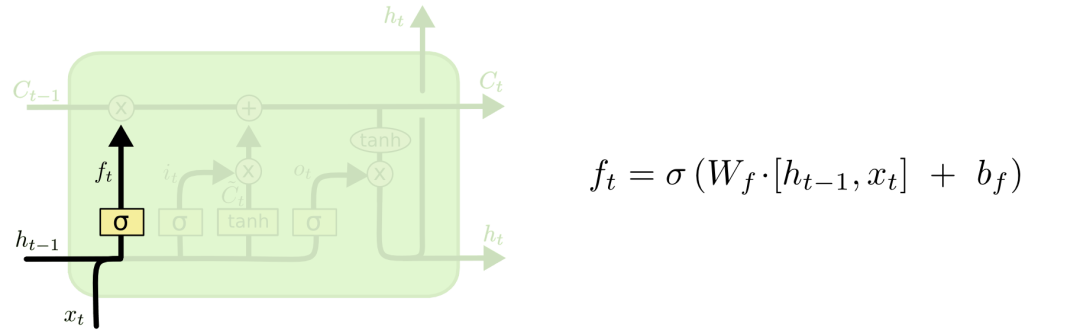
2.1 遗忘门
对于输入xt和ht-1,遗忘门会输出一个值域为[0, 1]的数字,放进Ct−1中。当为0时,全部删除;当为1时,全部保留。
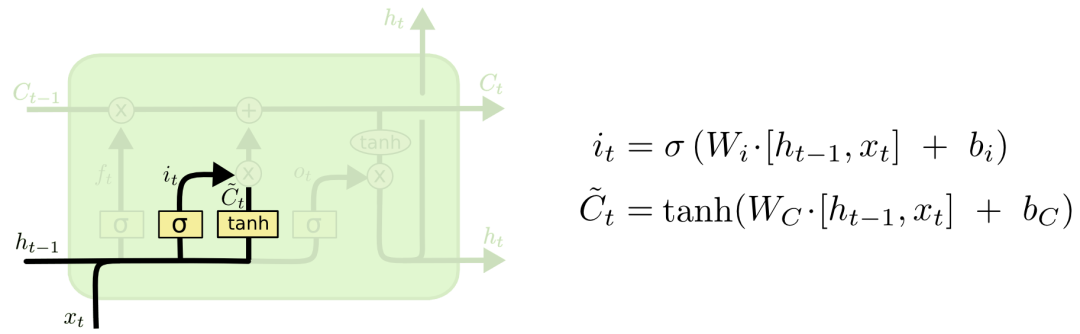
2.2 输入门
对于对于输入xt和ht-1,输入门会选择信息的去留,并且通过tanh激活函数更新临时Ct
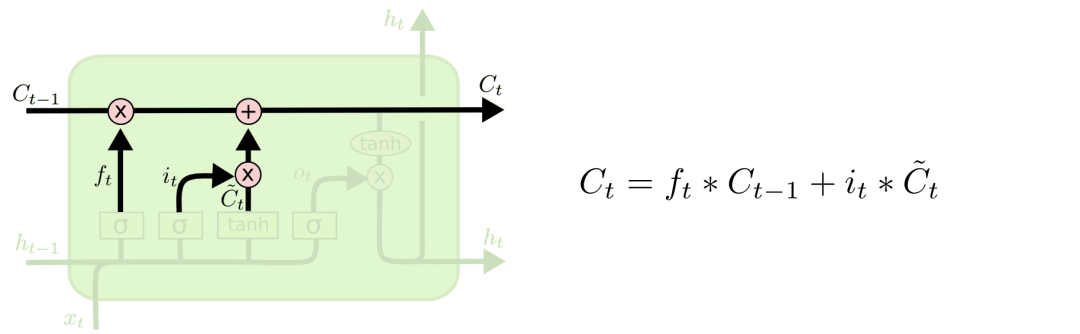
通过遗忘门和输入门输出累加,更新最终的Ct
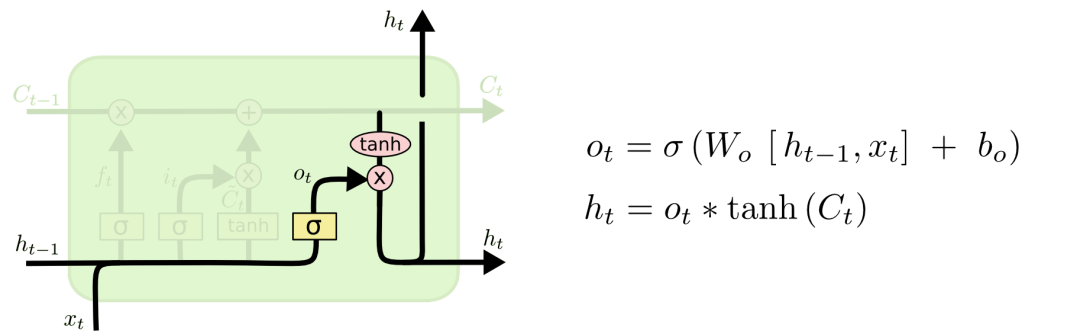
2.3输出门
通过Ct和输出门,更新memory
3.PyTorch的LSTM使用方法
__ init __(input _ size, hidden_size,num _layers)
LSTM.foward():
out,[ht,ct] = lstm(x,[ht-1,ct-1])
x:[一句话单词数,batch几句话,表示的维度]
h/c:[层数,batch,记忆(参数)的维度]
out:[一句话单词数,batch,参数的维度]
import torch
import torch.nn as nn
lstm = nn.LSTM(input_size = 100,hidden_size = 20,num_layers = 4)
print(lstm)
#LSTM(100, 20, num_layers=4)
x = torch.randn(10,3,100)
out,(h,c)=lstm(x)
print(out.shape,h.shape,c.shape)
#torch.Size([10, 3, 20]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])
单层使用方法:
cell = nn.LSTMCell(input_size = 100,hidden_size=20)
x = torch.randn(10,3,100)
h = torch.zeros(3,20)
c = torch.zeros(3,20)
for xt in x:
h,c = cell(xt,[h,c])
print(h.shape,c.shape)
#torch.Size([3, 20]) torch.Size([3, 20])
LSTM实战--情感分类问题
Google CoLab环境,需要魔法。
import torch
from torch import nn, optim
from torchtext import data, datasets
print('GPU:', torch.cuda.is_available())
torch.manual_seed(123)
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
print('len of train data:', len(train_data))
print('len of test data:', len(test_data))
print(train_data.examples[15].text)
print(train_data.examples[15].label)
# word2vec, glove
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)
batchsz = 30
device = torch.device('cuda')
train_iterator, test_iterator = data.BucketIterator.splits(
(train_data, test_data),
batch_size = batchsz,
device=device
)
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
"""
"""
super(RNN, self).__init__()
# [0-10001] => [100]
self.embedding = nn.Embedding(vocab_size, embedding_dim)
# [100] => [256]
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2,
bidirectional=True, dropout=0.5)
# [256*2] => [1]
self.fc = nn.Linear(hidden_dim*2, 1)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
"""
x: [seq_len, b] vs [b, 3, 28, 28]
"""
# [seq, b, 1] => [seq, b, 100]
embedding = self.dropout(self.embedding(x))
# output: [seq, b, hid_dim*2]
# hidden/h: [num_layers*2, b, hid_dim]
# cell/c: [num_layers*2, b, hid_di]
output, (hidden, cell) = self.rnn(embedding)
# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]
hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)
# [b, hid_dim*2] => [b, 1]
hidden = self.dropout(hidden)
out = self.fc(hidden)
return out
rnn = RNN(len(TEXT.vocab), 100, 256)
pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')
optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)
import numpy as np
def binary_acc(preds, y):
"""
get accuracy
"""
preds = torch.round(torch.sigmoid(preds))
correct = torch.eq(preds, y).float()
acc = correct.sum() / len(correct)
return acc
def train(rnn, iterator, optimizer, criteon):
avg_acc = []
rnn.train()
for i, batch in enumerate(iterator):
# [seq, b] => [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i%10 == 0:
print(i, acc)
avg_acc = np.array(avg_acc).mean()
print('avg acc:', avg_acc)
def eval(rnn, iterator, criteon):
avg_acc = []
rnn.eval()
with torch.no_grad():
for batch in iterator:
# [b, 1] => [b]
pred = rnn(batch.text).squeeze(1)
#
loss = criteon(pred, batch.label)
acc = binary_acc(pred, batch.label).item()
avg_acc.append(acc)
avg_acc = np.array(avg_acc).mean()
print('>>test:', avg_acc)
for epoch in range(10):
eval(rnn, test_iterator, criteon)
train(rnn, train_iterator, optimizer, criteon)
深度学习--LSTM网络、使用方法、实战情感分类问题的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- 深度学习Anchor Boxes原理与实战技术
深度学习Anchor Boxes原理与实战技术 目标检测算法通常对输入图像中的大量区域进行采样,判断这些区域是否包含感兴趣的目标,并调整这些区域的边缘,以便更准确地预测目标的地面真实边界框.不同的模型 ...
- 深度学习GPU加速配置方法
深度学习GPU加速配置方法 一.英伟达官方驱动及工具安装 首先检查自己的电脑驱动版本,未更新至最新建议先将驱动更新至最新,然后点击Nvidia控制面板 2.在如下界面中点击系统信息,点击显示可以看见当 ...
- 用深度学习LSTM炒股:对冲基金案例分析
英伟达昨天一边发布“全球最大的GPU”,一边经历股价跳水20多美元,到今天发稿时间也没恢复过来.无数同学在后台问文摘菌,要不要抄一波底嘞? 今天用深度学习的序列模型预测股价已经取得了不错的效果,尤其是 ...
- 【Deeplearning】(转)深度学习知识网络
转自深度学习知识框架,小象牛逼! 图片来自小象学院公开课,下面直接解释几条线 神经网络 线性回归 (+ 非线性激励) → 神经网络 有线性映射关系的数据,找到映射关系,非常简单,只能描述简单的映射关系 ...
- 深度学习RNN实现股票预测实战(附数据、代码)
背景知识 最近再看一些量化交易相关的材料,偶然在网上看到了一个关于用RNN实现股票预测的文章,出于好奇心把文章中介绍的代码在本地跑了一遍,发现可以work.于是就花了两个晚上的时间学习了下代码,顺便把 ...
- 深度学习的Xavier初始化方法
在tensorflow中,有一个初始化函数:tf.contrib.layers.variance_scaling_initializer.Tensorflow 官网的介绍为: variance_sca ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- 深度学习卷积网络中反卷积/转置卷积的理解 transposed conv/deconv
搞明白了卷积网络中所谓deconv到底是个什么东西后,不写下来怕又忘记,根据参考资料,加上我自己的理解,记录在这篇博客里. 先来规范表达 为了方便理解,本文出现的举例情况都是2D矩阵卷积,卷积输入和核 ...
- 深度学习常见的优化方法(Optimizer)总结:Adam,SGD,Momentum,AdaGard等
机器学习的常见优化方法在最近的学习中经常遇到,但是还是不够精通.将自己的学习记录下来,以备不时之需 基础知识: 机器学习几乎所有的算法都要利用损失函数 lossfunction 来检验算法模型的优劣, ...
随机推荐
- 【原创】2022年linux环境下QT6不支持中文输入法解决方案
1.配置环境 export PATH="~/目录/Qt/6.x.x/gcc_64/bin":$PATH export PATH="~/目录/Qt/Tools/Cmake/ ...
- 日志注解,基于ruoyi的后置切面改进而来
有次接口响应时间太长,想知道具体接口执行的时间是多少,于是决定通过注解来实现这个想法,刚好ruoyi本身就提供了完善的日志注解,虽然是采用后置通知,但是完全不影响我们改造它. 想要实现接口耗时的功能, ...
- UIPath踩坑记一 对 COM 组件的调用返回了错误 HRESULT E_FAIL。UiPath.UiNodeClass.InjectAndRunJS
[ERROR] [UiPath.Studio] [1] 错误: System.Exception: 对 COM 组件的调用返回了错误 HRESULT E_FAIL. ---> System.Ex ...
- 问题:fatal: unable to access 'https://github.com/XXXXX': GnuTLS recv error (-110): The TLS connection was non-properly terminated.
问题:fatal: unable to access 'https://github.com/XXXXX': GnuTLS recv error (-110): The TLS connection ...
- vue3-使用百度地图遇到的坑-地图实例化
1.创建地图实例 原因:在使用vue3为了只定义一次地图实例,在所有方法中使用,直接使用如下定义方式: setup() { const data = reactive({ bmap: null,}) ...
- rename基本操作
电脑是Macbook, 用Homebrew先安装rename. 如果没安装Homebrew 直接复制到terminal中回车, 时间稍长. ruby -e "$(curl -fsSL htt ...
- KLatexformula - MathType在Mac上的替代品
KLatexformula - MathType alternative for MAC 1. KLatexformular 好用! 买了Mac, 升级了系统, MathType安装不了, 寻寻觅觅- ...
- linux java 环境搭建
java -version 是否安装 yum -y remove java-1.7.0-openjdk* yum -y install java-1.7.0-openjdk* vim /etc/pro ...
- SpringBoot解决跨域方案
SpringBoot解决跨域的几种方式 跨域资源共享(CORS):通过修改Http协议header的方式,实现跨域.说的简单点就是,通过设置HTTP的响应头信息,告知浏览器哪些情况在不符合同源策略的条 ...
- PHP 计算机码、位运算、运算符优先级
计算机码 计算机在实际存储数据的时候,是采用编码规则的(二进制编码) 计算机码存储的过程: 原码.反码和补码,数值最左边一位用来充当符号位:符号为正数为0,负数为1 原码:数据本身从十进制转换为二进制 ...