【KAWAKO】TVM-使用c++进行推理
前言
在tvm工程的apps目录下,有一个howto_deploy的工程,根据此工程进行修改,可以得到c++推理程序。

修改cpp_deploy.cc文件
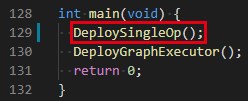
DeploySingleOp()函数不需要,直接将其和相关的Verify函数一起删掉。
修改DeployGraphExecutor()函数
读取指定模型,同时获得后面所需的函数
LOG(INFO) << "Running graph executor...";
printf("load in the library\n");
DLDevice dev{kDLCPU, 1};
tvm::runtime::Module mod_factory = tvm::runtime::Module::LoadFromFile("../model_autotune.so");
printf("create the graph executor module\n");
tvm::runtime::Module gmod = mod_factory.GetFunction("default")(dev);printf(" default\n");
tvm::runtime::PackedFunc set_input = gmod.GetFunction("set_input");printf(" set_input\n");
tvm::runtime::PackedFunc get_output = gmod.GetFunction("get_output");printf(" get_output\n");
tvm::runtime::PackedFunc run = gmod.GetFunction("run");printf(" run\n");
定义输入输出的变量
printf("Use the C++ API\n");
tvm::runtime::NDArray input = tvm::runtime::NDArray::Empty({1, 1, 640}, DLDataType{kDLFloat, 32, 1}, dev);
tvm::runtime::NDArray input_state = tvm::runtime::NDArray::Empty({1, 2, 128, 2}, DLDataType{kDLFloat, 32, 1}, dev);
tvm::runtime::NDArray output = tvm::runtime::NDArray::Empty({1, 1, 640}, DLDataType{kDLFloat, 32, 1}, dev);
tvm::runtime::NDArray output_state = tvm::runtime::NDArray::Empty({1, 2, 128, 2}, DLDataType{kDLFloat, 32, 1}, dev);
从bin文件中读取数据
float input_storage[1 * 1 * 640];
FILE* fp = fopen("../input.bin", "rb");
fread(input->data, 1 * 1 * 640, 4, fp);
fclose(fp);
float input_state_storage[1 * 2 * 128 * 2];
FILE* fp_state = fopen("../input_state.bin", "rb");
fread(input_state->data, 1 * 2 * 128 * 2, 4, fp_state);
fclose(fp_state);
将数据输入到网络
printf("set the right input\n");
set_input("input_4", input);
set_input("input_5", input_state);
运行推理
struct timeval t0, t1;
int times = 100000; // 3394
gettimeofday(&t0, 0);
printf("run the code\n");
for(int i=0;i<times;i++)
run();
gettimeofday(&t1, 0);
printf("%.5fms\n", ((t1.tv_sec - t0.tv_sec) * 1000 + (t1.tv_usec - t0.tv_usec) / 1000.f)/times);
得到输出
printf("get the output\n");
get_output(0, output);printf(" 0\n");
get_output(1, output_state);printf(" 1\n");
将输出保存到bin文件
FILE* fp_out = fopen("output.bin", "wb");
fwrite(output->data, 1 * 1 * 640, 4, fp_out);
fclose(fp_out);
FILE* fp_out_state = fopen("output_state.bin", "wb");
fwrite(output_state->data, 1 * 2 * 128 * 2, 4, fp_out_state);
fclose(fp_out_state);
numpy与bin文件的互相转换
numpy转bin
import numpy as np
import os
input_1 = np.load("./input.npy")
input_2 = np.load("./input_states.npy")
build_dir = "./"
with open(os.path.join(build_dir, "input.bin"), "wb") as fp:
fp.write(input_1.astype(np.float32).tobytes())
with open(os.path.join(build_dir, "input_state.bin"), "wb") as fp:
fp.write(input_2.astype(np.float32).tobytes())
bin转numpy
output = np.fromfile("./output.bin", dtype=np.float32)
output_state = np.fromfile("./output_state.bin", dtype=np.float32)
使用CMakeLists.txt进行编译
在howto_deploy目录下创建CMakeLists.txt
cmake_minimum_required(VERSION 3.2)
project(how2delploy C CXX)
SET(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O3 -Wall -g2 -ggdb")
SET(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall -fPIC")
set(TVM_ROOT /path/to/tvm)
set(DMLC_CORE ${TVM_ROOT}/3rdparty/dmlc-core)
include_directories(${TVM_ROOT}/include)
include_directories(${DMLC_CORE}/include)
include_directories(${TVM_ROOT}/3rdparty/dlpack/include)
link_directories(${TVM_ROOT}/build/Release)
add_definitions(-DDMLC_USE_LOGGING_LIBRARY=<tvm/runtime/logging.h>)
add_executable(cpp_deploy_norm cpp_deploy.cc)
target_link_libraries(cpp_deploy_norm ${TVM_ROOT}/build/libtvm_runtime.so)
老四连
mkdir build
cd build
cmake ..
make
运行
cd build
./cpp_deploy_norm
【KAWAKO】TVM-使用c++进行推理的更多相关文章
- 使用Tensorize评估硬件内部特性
使用Tensorize评估硬件内部特性 这是有关如何在TVM中执行张量的入门文档. 通过使用调度原语tensorize,人们可以用相应的内部函数代替计算单元,从而轻松利用handcrafted mic ...
- 【翻译】借助 NeoCPU 在 CPU 上进行 CNN 模型推理优化
本文翻译自 Yizhi Liu, Yao Wang, Ruofei Yu.. 的 "Optimizing CNN Model Inference on CPUs" 原文链接: h ...
- AI推理与Compiler
AI推理与Compiler AI芯片编译器能加深对AI的理解, AI芯片编译器不光涉及编译器知识,还涉及AI芯片架构和并行计算如OpenCL/Cuda等.如果从深度学习平台获得IR输入,还需要了解深度 ...
- 将TVM集成到PyTorch
将TVM集成到PyTorch 随着TVM不断展示出对深度学习执行效率的改进,很明显PyTorch将从直接利用编译器堆栈中受益.PyTorch的主要宗旨是提供无缝且强大的集成,而这不会妨碍用户.PyTo ...
- TVM代码生成codegen
TVM代码生成codegen 硬件后端提供程序(例如Intel,NVIDIA,ARM等),提供诸如cuBLAS或cuDNN之类的内核库以及许多常用的深度学习内核,或者提供框架例,如带有图形引擎的DNN ...
- 桥接PyTorch和TVM
桥接PyTorch和TVM 人工智能最引人入胜的一些应用是自然语言处理.像BERT或GPT-2之类的模型及其变体,可以获住足够多的文本信息. 这些模型属于称为Transformers的神经网络类体系结 ...
- TVM适配NN编译Compiler缺陷
TVM适配NN编译Compiler缺陷 内容纲要 前言 TVM针对VTA的编译流程 自定义VTA架构:TVM的缺陷与性能瓶颈 TVM缺陷与瓶颈 缺陷一:SRAM配置灵活性差 缺陷二:计算阵列配置僵硬 ...
- TVM优化GPU机器翻译
TVM优化GPU机器翻译 背景 神经机器翻译(NMT)是一种自动化的端到端方法,具有克服传统基于短语的翻译系统中的弱点的潜力.最近,阿里巴巴集团正在为全球电子商务部署NMT服务. 将Transform ...
- TVM 优化 ARM GPU 上的移动深度学习
TVM 优化 ARM GPU 上的移动深度学习 随着深度学习的巨大成功,将深度神经网络部署到移动设备的需求正在迅速增长.与桌面平台上所做的类似,在移动设备中使用 GPU 既有利于推理速度,也有利于能源 ...
- 端到端TVM编译器(下)
端到端TVM编译器(下) 4.3 Tensorization DL工作负载具有很高的运算强度,通常可以分解为张量运算符,如矩阵乘法或一维卷积.这些自然分解导致了最近的添加张量计算原语.这些新的原语带来 ...
随机推荐
- 进军东南亚市场,腾讯云数据库 TDSQL 助力印尼 BNC 银行数字化转型
腾讯云数据库在助力金融核心系统分布式替换上,已经辐射到了东南亚市场. 东南亚最大的银行之一印尼BNC银行(Bank Neo Commerce)已正式完成新核心分布式迁移,使用腾讯云数据库TDSQL后, ...
- typora实现多平台发布文章
源码下载 前言 之前写过一片文章,typora 使用CSDN作为图床,用来存储 markdown 文章的图片资源文件.后来发现 typora 还可以自定义导出命令,那么也可以利用这个功能实现直接发布到 ...
- day 19 分组查询 & having和where区别
day19 分组查询group by having用法 用于分组关键字(group by)后面 用于对分组之后的结果集进行筛选 having关键字后面可以使用聚合函数 having和where的区别 ...
- Ubuntu20.04创建快捷方式(CLion)
打开命令行,创建在桌面上xxx.desktop文件 touch ~/Desktop/Clion.desktop 编辑desktop文件 [Desktop Entry] Encoding=UTF-8 N ...
- Scrum敏捷开发方法实践
前言 作者所在的公司在项目开发的过程中采用着当下互联网公司中流行的小步快跑开发策略,特别借鉴了敏捷开发中的迭代递增思想来指导项目的开发.我们经过对相关敏捷开发方法的调查研究,最终采用了Scrum敏 ...
- STM32按键控制LED亮灭的代码
led.c #include "led.h" void LED_Config(void) { GPIO_InitTypeDef GPIO_InitStruct; RCC_APB2P ...
- jquerylib表单
用jquerylib,实现表格添加内容和删除内容 <!DOCTYPE html> <html> <head> <meta charset="UTF- ...
- 利用Git同步思源笔记
旧文章从语雀迁移过来,原日期为2022-10-22 思源笔记是一款优秀的本地优先的双链大纲笔记软件,拥有强大的笔记编辑功能且都是免费,唯一付费的就是云同步等一些服务了.但如果暂时还用不着云同步的,我们 ...
- 实践GoF的23种设计模式:命令模式
摘要:命令模式可将请求转换为一个包含与请求相关的所有信息的对象, 它能将请求参数化.延迟执行.实现 Undo / Redo 操作等. 本文分享自华为云社区<[Go实现]实践GoF的23种设计模式 ...
- [python] 向量检索库Faiss使用指北
Faiss是一个由facebook开发以用于高效相似性搜索和密集向量聚类的库.它能够在任意大小的向量集中进行搜索.它还包含用于评估和参数调整的支持代码.Faiss是用C++编写的,带有Python的完 ...