python 爬取历史天气
python 爬取历史天气
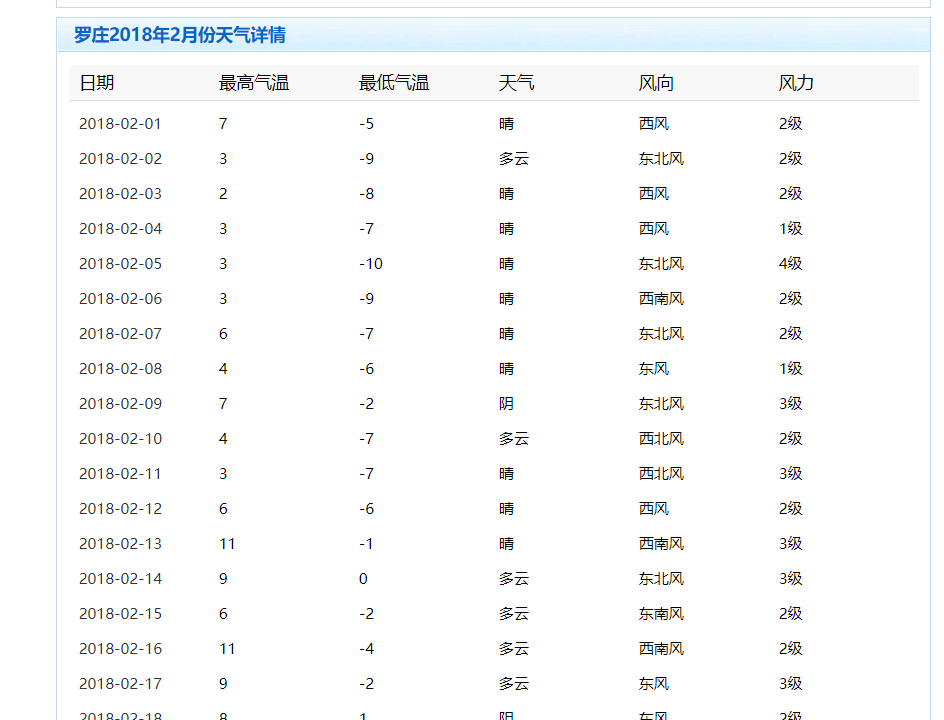
官网:http://lishi.tianqi.com/luozhuangqu/201802.html
# encoding:utf-8
import requests
from bs4 import BeautifulSoup
import pymysql
import pandas as pd date_list = [x.strftime('%Y%m') for x in list(pd.date_range(start='2016-09', end='2018-09', freq="m"))]
url_str = "http://lishi.tianqi.com/"
# citys = ["苍山", "费县", "河东区", "莒南", "临沭", "兰山市", "罗庄区", "蒙阴", "平邑", "郯城", "沂南", "沂水"]
# city_code = ["cangshan", "feixian", "hedong", "junan", "linshu", "lanshan", "luozhuangqu", "mengyin", "pingyi",
# "tancheng", "yinan", "yishui"] city_code = ["yishui"] urls = []
# url拼接
for city in city_code:
for date_item in date_list:
url = url_str + city + "/" + date_item + ".html"
urls.append(url) # 数据爬取
for url in urls:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
weather_list = soup.select('div[class="tqtongji2"]')
for weather in weather_list:
weather_date = weather.select('a')[0].string.encode('utf-8')
ul_list = weather.select('ul')
for ul in ul_list[1:]:
li_list = ul.select('li')
tCity = "沂水"
tDate = li_list[0].string
tTopTem = li_list[1].string
tLowTem = li_list[2].string
tWeather = li_list[3].string
tWindDir = li_list[4].string
tWindPower = li_list[5].string # 数据库存储
conn = pymysql.connect(host='localhost', user='root', passwd='', database='weather',
charset='utf8') # 链接数据库
cursor = conn.cursor() # 获得游标
# 向数据库添加数据的SQL语句
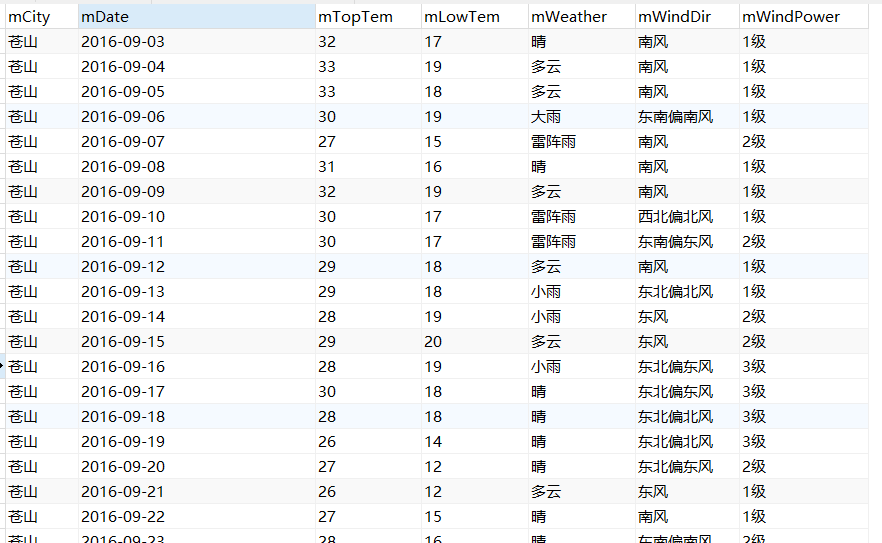
sql = "insert into mWeather (mCity,mDate,mTopTem,mLowTem,mWeather,mWindDir,mWindPower) values ('%s','%s','%s','%s','%s','%s','%s')" \
% (tCity, tDate, tTopTem, tLowTem, tWeather, tWindDir, tWindPower)
cursor.execute(sql) # 执行
conn.commit() # 提交添加数据的命令
cursor.close()
conn.close()
print(tCity + " 城市 " + tDate + " 数据 ----- 爬取成功!")
python 爬取历史天气的更多相关文章
- PHP爬取历史天气
PHP爬取历史天气 PHP作为宇宙第一语言,爬虫也是非常方便,这里爬取的是从天气网获得中国城市历史天气统计结果. 程序架构 main.php <?php include_once(". ...
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- Scrapy实战篇(五)之爬取历史天气数据
本篇文章我们以抓取历史天气数据为例,简单说明数据抓取的两种方式: 1.一般简单或者较小量的数据需求,我们以requests(selenum)+beautiful的方式抓取数据 2.当我们需要的数据量较 ...
- python爬取中国天气网站数据并对其进行数据可视化
网址:http://www.weather.com.cn/textFC/hb.shtml 解析:BeautifulSoup4 爬取所有城市的最低天气 对爬取的数据进行可视化处理 按温度对城市进行排 ...
- PyQuery爬取历史天气信息
1.准备工作: 网址:https://lishi.tianqi.com/xian/index.html 爬虫类库:PyQuery,requests 2.网页分析: 红线部分可更改为需要爬取的城市名,如 ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
- 初识python 之 爬虫:爬取中国天气网数据
用到模块: 获取网页并解析:import requests,html5lib from bs4 import BeautifulSoup 使用pyecharts的Bar可视化工具"绘制图表& ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- python3爬取墨迹天气并发送给微信好友,附源码
需求: 1. 爬取墨迹天气的信息,包括温湿度.风速.紫外线.限号情况,生活tips等信息 2. 输入需要查询的城市,自动爬取相应信息 3. 链接微信,发送给指定好友 思路比较清晰,主要分两块,一是爬虫 ...
随机推荐
- node代码打包为 exe文件---端口进程关闭demo
最近用到 java,用tomcat起的服务,经常服务关了,对应的进程还在跑,导致再次启动服务失败,需要手动关闭进程. 使用 dos命令虽然只有两行,总是输,也很烦. netstat -ano | fi ...
- 使用 nghttpx 搭建 HTTP/2 代理 (转)
来自http://www.fanyue.info/2015/08/nghttpx-http2.html 使用 nghttpx 搭建 HTTP/2 代理 [转] HTTP/1.1,定义于 1999 年, ...
- .NET拾忆:FileSystemWatcher 文件监控
资源: https://msdn.microsoft.com/zh-cn/library/system.io.filesystemwatcher_properties(v=vs.110).aspx F ...
- Linux基础(五) Shell函数
Shell 函数 linux shell 可以用户定义函数,然后在shell脚本中可以随便调用. shell中函数的定义格式如下: [ function ] funname [()] { action ...
- pyqt常用窗口组件
扩展知识: 熟悉常用的窗口组件: 1 按钮类 QPushButton 普通按钮 QToolButton 工具按钮:通常在工具栏使用 QRadioButton 单选框 QCheckBox ...
- 阿里云esc服务器上部署java项目
文章中使用centos(6和7版本).Xshell.Xftp 因为部署过程直接从操作服务器开始,如果你还没有连接好服务器请参考http://blog.csdn.net/ctrlxv/article/d ...
- sqli-labs(十六)(order by注入)
第四十六关: http://www.bubuko.com/infodetail-2481914.html 这有篇文章讲得还不错可以看下 这关是order by后面的一个注入,用报错注入和盲注都是可以的 ...
- 21Oracle数据库和实例
Oracle数据库:相关的操作系统文件(即储存在计算机硬盘上的文件)的集合,这些文件组织在一起,成为一个逻辑整体,即为Oracle数据库.物理存在 Oracle实例:位于物理内存里的数据结构,它由操作 ...
- 将Web项目War包部署到Tomcat服务器基本步骤
参考来源: http://www.cnblogs.com/pannysp/archive/2012/03/07/2383364.html 1. 常识: 1.1 War包 War包一般是在进行Web ...
- executing in nfs will not generate core dump file
最近遇到了一个奇怪的问题. linux系统的pc搭建nfs server,开发板作为nfs client,开发板中全程root权限操作,执行的程序放到 nfs server 中 exports 出的目 ...