Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
- 以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的requesst是通过start_requests()来获取的。start_requests()获取 start_urls中的URL,并以parse以回调函数生成Request
- 在回调函数内分析返回的网页内容,可以返回Item对象,或者Dict,或者Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数
- 在回调函数内,可以通过lxml,bs4,xpath,css等方法获取我们想要的内容生成item
- 最后将item传递给Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写start_requests来处理start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析
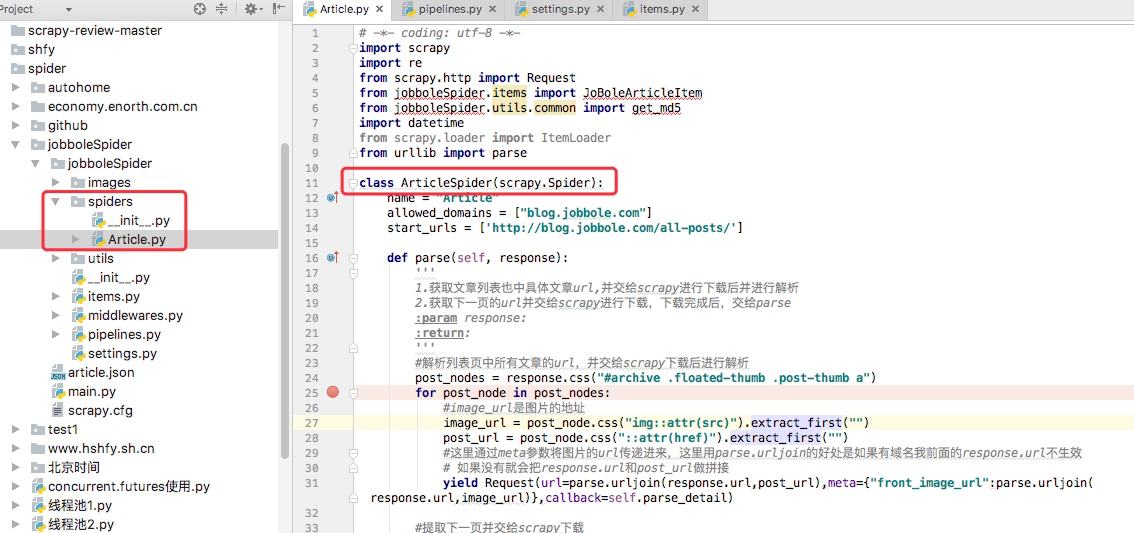
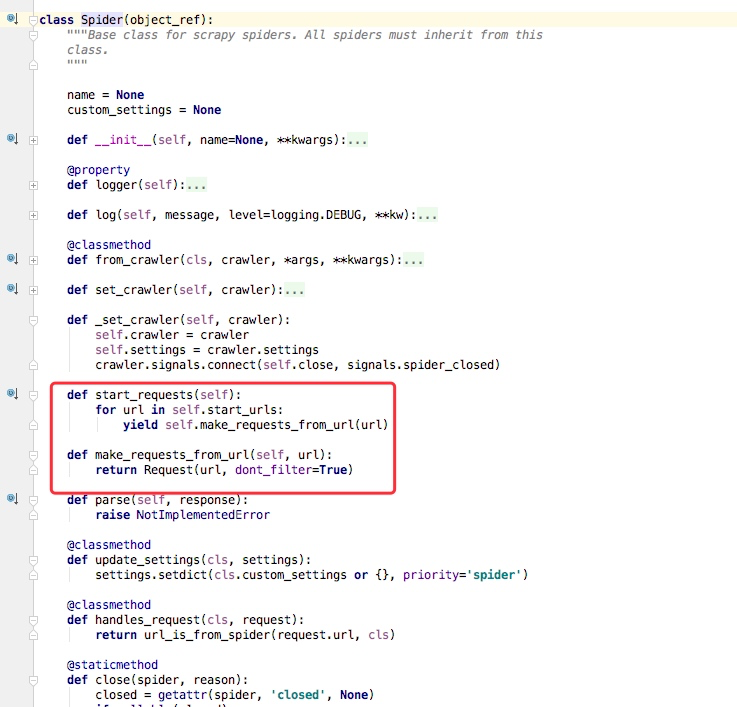
通过上述代码我们可以看到在父类里这里实现了start_requests方法,通过make_requests_from_url做了Request请求
如下图所示的一个例子,parse回调函数中的response就是父类列start_requests方法调用make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回Request,如下属代码中yield Request()并设置回调函数。

spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法的更多相关文章
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- python爬虫从入门到放弃(五)之 正则的基本使用
什么是正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是 事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符",这个"规则字符" 来表达对 ...
- python爬虫从入门到放弃(五)之 正则的基本使用(转)
什么是正则表达式 正则表达式是对字符串操作的一种逻辑公式,就是 事先定义好的一些特定字符.及这些特定字符的组合,组成一个“规则字符”,这个“规则字符” 来表达对字符的一种过滤逻辑. 正则并不是pyth ...
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
随机推荐
- activeMQ的简单介绍
1.什么叫activeMQ? ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线.ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现 ...
- 纯css实现select下拉框并排显示
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Java IO流之打印流与标准流
一.打印流 1.1打印流特点与构造方法 1)PrintStream和PrintWriter类都提供了一系列重载的print和println方法来输出各种类型的数据. 2)PrintStream和Pri ...
- Java 9 揭秘(3. 创建你的第一个模块)
文 by / 林本托 Tips 做一个终身学习的人. 在这个章节中,主要介绍以下内容: 如何编写模块化的Java程序 如何编译模块化程序 如何将模块的项目打包成模块化的JAR文件 如何运行模块化程序 ...
- 使用wget下载JDK8
每次去官网下载JDK有点烦 但是直接使用wget 又得同意协议所以 使用如下的wget就好了(注意是64位的哦) 先去官网看一下地址变化 没有如下 :修改后面的下载地址即可 注意哦~ 2.然后使用下面 ...
- nodeJS之流stream
前面的话 当内存中无法一次装下需要处理的数据时,或者一边读取一边处理更加高效时,我们就需要用到数据流.NodeJS中通过各种Stream来提供对数据流的操作.本文将详细说明NodeJS中的流strea ...
- sqlserver 游标写法
1.简单游标 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 declare m_cursor cursor scroll for select Address,People ...
- python入门小记
一.help python中的帮助手册,对于初学者,多多使用help,多看看原生注释-- 1.help的使用 1.命令需要使用双引号或者单引号括起来,不使用引号引起来会报错 2.类或者函数(方法)不需 ...
- 用PHP和Ajax进行前后台数据交互——以用户登录为例
很多网站中都有用户登录系统,要完成用户的注册和登陆,就一定要用到前后台的数据交互.在这里以简单的用户注册和登陆为例介绍一下前后台交互的大致流程. 首先,我们来做一个简单的登陆界面. 这里为了方便我使用 ...
- Git配合Tag的代码回滚
现有的远程仓库版本的tag为v1.0 前置准备 具体操作: 我们在本地修改一下readme文件,然后进行add,commit操作. 再给我们的commit打上tag git tag -a v1.1 - ...