Python和BeautifulSoup进行网页爬取
在大数据、人工智能时代,我们通常需要从网站中收集我们所需的数据,网络信息的爬取技术已经成为多个行业所需的技能之一。而Python则是目前数据科学项目中最常用的编程语言之一。使用Python与BeautifulSoup可以很容易的进行网页爬取,通过网站爬虫获取信息可以帮助企业或个人节省很多的时间和金钱。学习本文之后,我相信大部分新手都能根据自己的需求来开发出相应的网页爬虫。
基础条件
了解简单的Python编程规则(Python 3.x)了解简单的网页Html标签
如果您是完全的新手也不用担心,通过本文您可以很容易地理解。
安装所需包
首先,您需要先安装好Python 3.x,Python安装包可以从python.org下载,然后我们需要安装requests和beautifulsoup4两个包,安装代码如下:
$ pip install requests $ pip install beautifulsoup4
爬取网页数据
现在我们已经做好了一切准备工作。在本教程中,我们将演示从没被墙的维基百科英文版页面中获取历届美国总统名单。
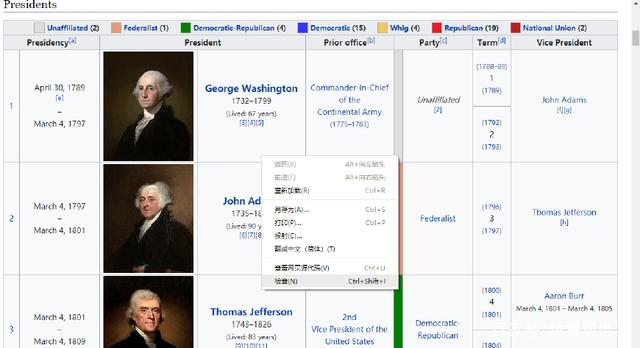
由下图可知,表格的内容位于class属性为wikitable的table标签下,我们需要了解这些标签信息来获取我们所需内容。

了解网页信息之后,我们就可以编写代码了。首先,我们要导入我们安装的包:
import requests from bs4 import BeautifulSoup
为了获取网页数据我们要使用requests的get()方法:
url = "https://en.wikipedia.org/wiki/List_of_Presidents_of_the_United_States" page = requests.get(url)
检查http响应状态,来确保我们能正常获取网页,如果输出状态代码为200则为正常:
print(page.status_code)
现在我们已经获取了网页数据,让我们看看我们得到了什么:
print(page.content)
上面的代码会显示http相应的全部内容,包括html代码和我们需要的文本数据信息。通过使用beautifulsoup的prettify()方法可以将其更美观的展示出来:
soup = BeautifulSoup(page.content, 'html.parser') print(soup.prettify())
这会将数据按照我们上面“检查”中看到的代码形式展示出来:
接下来我们将使用bs4对象的find方法提取table标签中的数据,此方法返回bs4对象:
tb = soup.find('table', class_='wikitable')
table标签下有很多嵌套标签,通过网页检查中的代码可以发现,我们最终是需要获得title元素中的文本数据,而title元素位于a标签下,a标签位于b标签下,b标签位于table标签下。为了获取所有我们所需的数据,我们需要提取table标签下的所有b标签,然后找到b标签下的所有a标签,为此,我们使用find_all方法来迭代获取所有b标签下的a标签:
for link in tb.find_all('b'):
name = link.find('a')
print(name)
可以看出,这并不是我们所要的最终结果,其中掺杂着html代码,不用担心,我们只需为上面的代码添加get_text()方法,即可提取出所有a标签下title元素的文本信息,代码改动如下:
for link in tb.find_all('b'):
name = link.find('a')
print(name.get_text('title'))
最终获得所有总统的名单如下:
George Washington John Adams Thomas Jefferson James Monroe 。。。
Python和BeautifulSoup进行网页爬取的更多相关文章
- 在Python中使用BeautifulSoup进行网页爬取
目录 什么是网页抓取? 为什么我们要从互联网上抓取数据? 网站采集合法吗? HTTP请求/响应模型 创建网络爬虫 步骤1:浏览并检查网站/网页 步骤2:创建用户代理 步骤3:导入请求库 检查状态码 步 ...
- 如何利用python模仿浏览器进行网页爬取?
http://wwwsearch.sourceforge.net/mechanize/ http://www.ibm.com/developerworks/cn/linux/l-python-mech ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- Python爬虫——request实例:爬取网易云音乐华语男歌手top10歌曲
requests是python的一个HTTP客户端库,跟urllib,urllib2类似,但比那两个要简洁的多,至于request库的用法, 推荐一篇不错的博文:https://cuiqingcai. ...
- 【学习笔记】Python 3.6模拟输入并爬取百度前10页密切相关链接
[学习笔记]Python 3.6模拟输入并爬取百度前10页密切相关链接 问题描述 通过模拟网页,实现百度搜索关键词,然后获得网页中链接的文本,与准备的文本进行比较,如果有相似之处则代表相关链接. me ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- Python网络爬虫与如何爬取段子的项目实例
一.网络爬虫 Python爬虫开发工程师,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页 ...
- 使用urllib进行网页爬取
# coding=gbk # 抓取开奖号码 # url:http://datachart.500.com/dlt/zoushi/jbzs_foreback.shtml ''' 对网页逐行迭代,找到目标 ...
- WebFetch 是无依赖极简网页爬取组件
WebFetch 是无依赖极简网页爬取组件,能在移动设备上运行的微型爬虫. WebFetch 要达到的目标: 没有第三方依赖jar包 减少内存使用 提高CPU利用率 加快网络爬取速度 简洁明了的api ...
随机推荐
- Dotween 应用
dotween是做缓动比较简单实用的插件,下面就使用经验进行浅谈 1)通用方法:如下图官网截图所示,如果看不懂可以跳过,这是一个通用方法,前两个参数为委托类型,可以用lambda表达式,也可以直接写成 ...
- webpack中如何使用图标字体
1.webpack安装相关依赖 $ npm install font-awesome-webpack less less-loader css-loader style-loader file-loa ...
- RESTFul API最佳实践
RESTful API最佳实践 RESTful API 概述 基本概念 REST 英文全称:Representational State Transfer,直译为:表现层状态转移.首次是由Roy Th ...
- 前端技术之:webpack热模块替换(HMR)
第一步:安装HMR中间件: npm install --save-dev webpack-hot-middleware 第二步:webpack配置中引入webpack对象 const we ...
- CVE-2019-16097:Harbor任意管理员注册漏洞复现
0x00 Harbor简介 Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如安全.标识和管理等,扩展了开源Docker Distri ...
- 博客文章编辑器 Cmd Markdown
欢迎使用 Cmd Markdown 编辑阅读器 编辑器点击打开链接 学习语言地址点击打开链接
- [考试反思]0825NOIP模拟测试30:没落
AB卷,15人. Lrefrain rank#1 179 skyh rank#2 122 116 108 54 42虽说还是不怎么样,但是有好转的迹象. 开卷审题,T1是个(假)期望,感觉也许还可做. ...
- 4、Hibernate的查询方式
一.Hibernate的查询方式:OID查询 1.OID检索:Hibernate根据对象的OID(主键)进行检索 1-1.使用get方法 Customer customer = session.get ...
- EffectiveJava-3
一.如果其他类型更适合,则尽量避免使用字符串 1. 字符串不适合代替枚举类型 2. 字符串不适合代替聚合类型,例如: String compoundKey = className+ "#&q ...
- python编程【环境篇】- 如何优雅的管理python的版本
简介 之前的文章(Python2还是python3 )中我们提到,建议现在大家都采用python3,因为python2在今年年底将不在维护.但在实际的开发和使用python过程中,我们避免不了还得用到 ...