第三次作业-Python网络爬虫与信息提取
1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
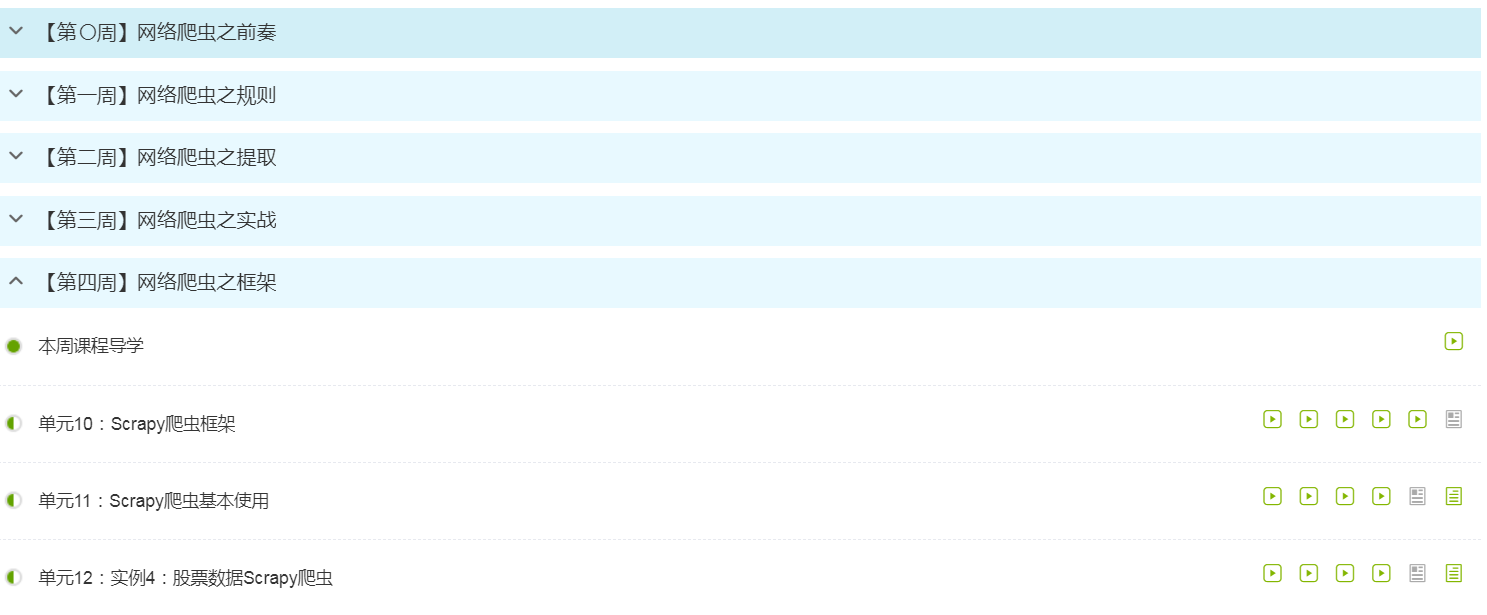
3.学习完成第0周至第4周的课程内容,并完成各周作业
 过程。
过程。
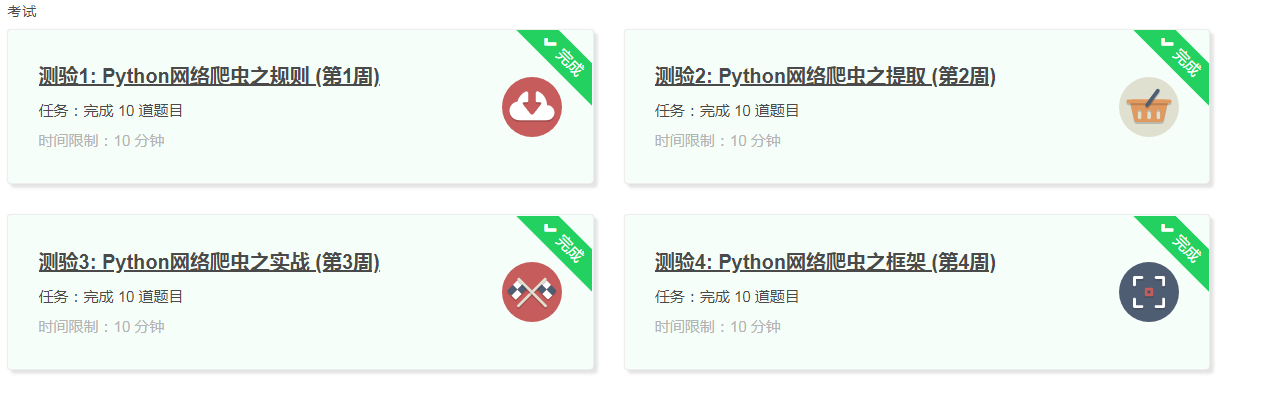
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过学习python网络爬虫与信息提取,对于python的了解更多了,这个网课上的很详细,老师讲的也很细致。通过这个课程我也知道了很多以前没有接触到的知识,我知道了什么是网络爬虫以及爬虫有什么作用,我都有去做了下功课。网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。爬虫可以作为通用搜索引擎网页收集器,做垂直搜索引擎,并且科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
Python网络爬虫是可以跨平台,对对Linux和windows都有不错的支持;科学计算,数值拟合:Numpy,Scipy;可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2;复杂网络:Networkx;统计:与R语言接口:Rpy。用python写爬虫是为了满足“抓数据”的需求,使用爬虫软件更为方便,不用把时间花在解析网页上、测试程序上以及处理防采集上。
python网络爬虫与信息是有五个框架,每一个都有自己的特点。Requests框架:自动爬取HTML页面与自动网络请求提交;robots.txt:网络爬虫排除标准;BeautifulSoup框架:解析HTML页面;Re框架:正则框架,提取页面关键信息;Scrapy框架:网络爬虫原理,专业爬虫框架介绍。而requests库是目前公认的爬取网页最好的python第三方库,特点是简单。Python网络爬虫的主要方法有很多,其中request()是构造一个请求,是支撑各方法的基础;get()是获取html网页的主要方法,对应的是http的get;head()是获取html网页头的信息方法,对应的是http的head ;post() 是向html网页提交post请求,对应的是http的post;put()是向html网页提交put请求,对应的是http的put;patch()是向html页面提交局部修改请求,对应的是http的patch;而delete()是向html页面提交删除请求,对应的是http的delete。
response对象的属性有五种,r.status_code是http请求返回的状态,200表示链接成功,404表示失败;r.text是http响应内容的字符串形式,即,url对应的页面内容;r.encoding是从http header中获取对应的内容编码形式 ;r.apparent_encoding是从内容中分析的响应内容编码方式;r.content是http响应的内容的二进制形式。
Python的内容多式多样,是学无止境的,要学好这门课程,是需要长时间的钻研,仅仅靠这个课程是远远不够的。在这里面我们学到了很多书本以外的知识,这都是一种收获,老师上的课也都很详细,把每一个知识点都有讲透,并且呈现出来,让我对python的兴趣多了一点。中国大学生慕课也是一个好的平台,能让更多人可以学习,通过这个平台去了解更多的知识,让自己的专业知识更加丰富。
第三次作业-Python网络爬虫与信息提取的更多相关文章
- 第三次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 第一周 Requests库的爬 ...
- 第3次作业-MOOC学习笔记:Python网络爬虫与信息提取
1.注册中国大学MOOC 2.选择北京理工大学嵩天老师的<Python网络爬虫与信息提取>MOOC课程 3.学习完成第0周至第4周的课程内容,并完成各周作业 4.提供图片或网站显示的学习进 ...
- Python网络爬虫与信息提取
1.Requests库入门 Requests安装 用管理员身份打开命令提示符: pip install requests 测试:打开IDLE: >>> import requests ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取(一)
学习 北京理工大学 嵩天 课程笔记 课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解 ...
- Python网络爬虫与信息提取(三)—— Re模块
regular expression / regex / RE 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配.Python 自1.5版本起增加了re 模块,它提供 ...
- Python网络爬虫与信息提取(二)—— BeautifulSoup
BeautifulSoup官方介绍: Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. 官方 ...
- python网络爬虫与信息提取 学习笔记day2
Day2: 查看robots协议: 查看京东的robots协议 查看百度的robots协议,可以看到百度拒绝了搜狗的爬虫233 爬取京东商品页面相关信息: import requests url = ...
随机推荐
- 协议分层(因特网5层模型)及7层OSI参考模型
目录 因特网5层模型及7层OSI参考模型 分层的体系结构: 应用层(软件) 运输层(软件) 网络层(硬件软件混合) 链路层(硬件) 物理层(硬件) OSI模型 表示层 会话层 封装 因特网5层模型及7 ...
- 【NHOI2018】扫雷完成图
[题目描述] 扫雷游戏完成后会显示一幅图,图中标示了每个格子的地雷情况.现在,一个 n * n 方阵中有 k 个地雷,请你输出它的扫雷完成图. [输入数据] 输入共 k+1 行: 第 1 行为 2 个 ...
- 附011.Kubernetes-DNS及搭建
一 Kubernetes DNS介绍 1.1 Kubernetes DNS发展 作为服务发现机制的基本功能,在集群内需要能够通过服务名对服务进行访问,因此需要一个集群范围内的DNS服务来完成从服务名到 ...
- Dockerfile构建私有镜像
构建第一个镜像 镜像的定制实际上就是定制每一层所添加的配置,文件.我们可以把每一层修改,安装,构建,操作的命令都写入一个脚本,这个脚本就是Dockerfile.Dockerfile是一个文本文件,其内 ...
- linux下信号量可设值的函数操作
#include <sys/types.h>#include <sys/ipc.h>#include <sys/sem.h>#include <errno.h ...
- python小知识课堂
啦啦啦 with上下文管理 __class__和type的关系
- PAT(甲级)2019年春季考试
7-1 Sexy Primes 判断素数 一个点没过17/20分 错因:输出i-6写成了输出i,当时写的很乱,可以参考其他人的写法 #include<bits/stdc++.h> usin ...
- 华为云北京四业务,访问北京一OBS桶,配置指南
[摘要] 华为云跨数据中心,从北京四访问北京一的OBS桶里面的数据.免去数据迁移的麻烦 1 驱动力 跨region访问OBS桶里面的数据时.如果不走云连接,一个OBS桶域名对应的IP地址,是 ...
- mq解决分布式事物问题【代码】
上节课简单说了一下mq是怎么保证数据一致性的.下面直接上代码了. 所需环境:1.zookeepor注册中心 2.kafka的服务端和工具客户端(工具客户端也可以不要只是为了更方便的查看消息而已) ...
- Spring MVC上传文件原理和resolveLazily说明
问题:使用Spring MVC上传大文件,发现从页面提交,到进入后台controller,时间很长.怀疑是文件上传完成后,才进入.由于在HTTP首部自定义了“Token”字段用于权限校验,Token的 ...