EFK(Elasticsearch+Filebeat+Kibana)收集容器日志
介绍
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Beats 是数据采集的得力工具。将 Beats 和您的容器一起置于服务器上,或者将 Beats 作为函数加以部署,然后便可在 Elastisearch 中集中处理数据。如果需要更加强大的处理性能,Beats 还能将数据输送到 Logstash 进行转换和解析。
Kibana 核心产品搭载了一批经典功能:柱状图、线状图、饼图、旭日图,等等。不仅如此,您还可以使用 Vega 语法来设计独属于您自己的可视化图形。所有这些都利用 Elasticsearch 的完整聚合功能。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
EFK架构图:
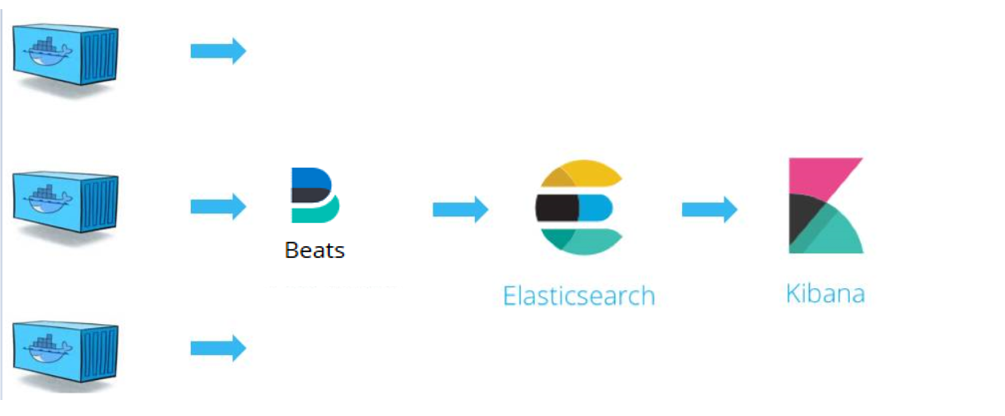
安装
这里采用helm chart安装
官方地址:https://github.com/elastic/helm-charts
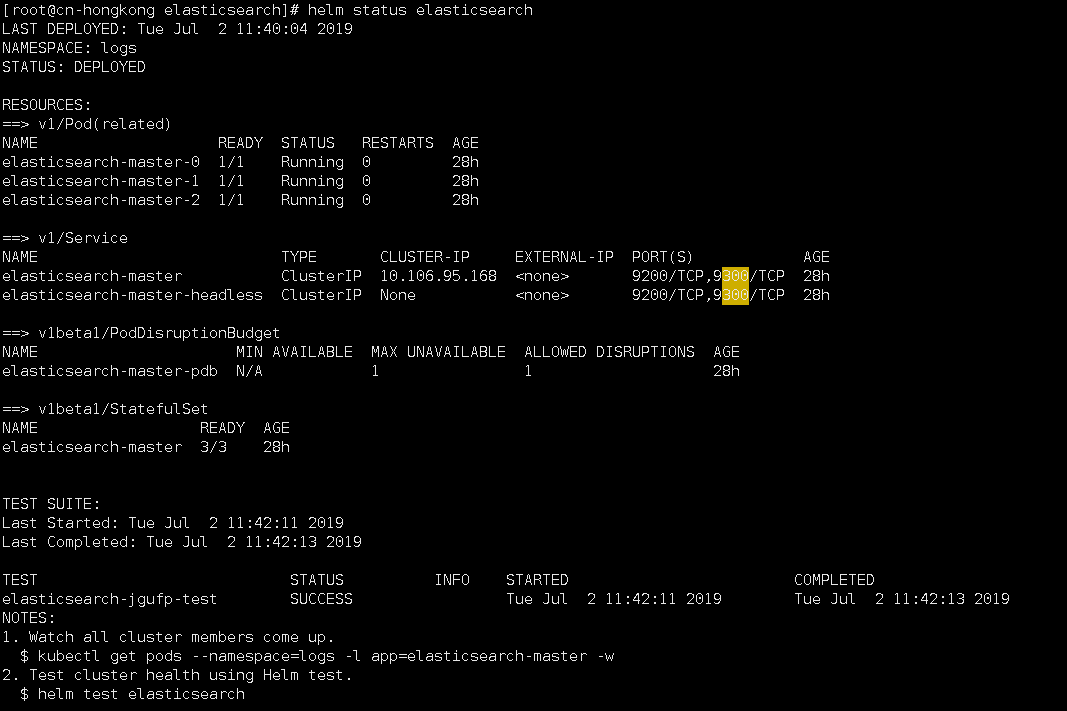
1.安装elasticsearch
$ helm fetch elastic/elasticsearch $ kubectl create ns logs $ helm repo add elastic https://helm.elastic.co #修改values.yaml文件中pv为storageClass动态分配 volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 30Gi
$ helm install -n elasticsearch --namespace=logs ./elasticsearch
查看状态
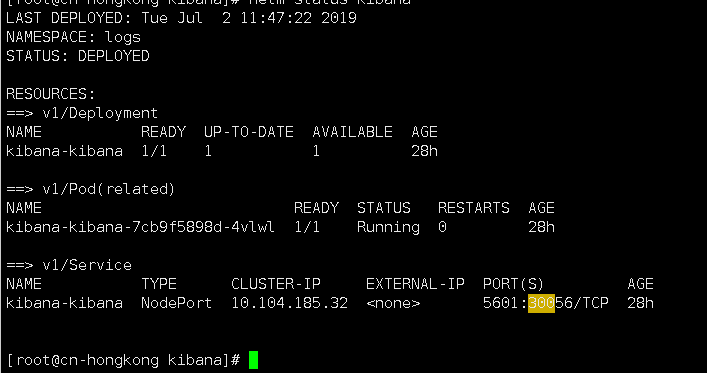
2.安装kibana
$ helm fetch elastic/kibana #修改values.yaml文件中service为nodePort类型 service:
type: NodePort
port: 5601
nodePort: 30056
$ helm install -n kibana --namespace=logs ./kibana
查看状态
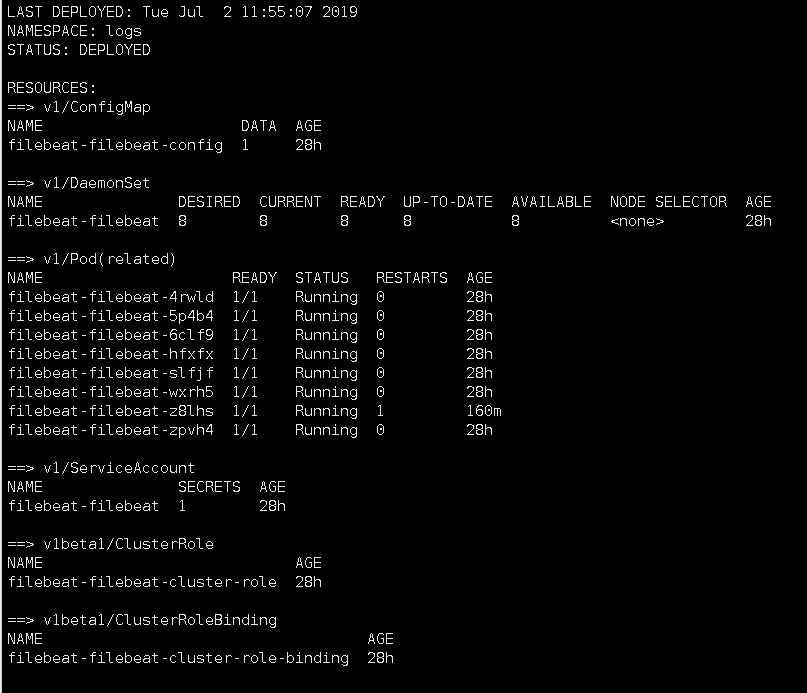
3.安装filebeat
$ helm fetch elastic/filebeat
#默认读取的是节点/var/lib下的所有文件
# Root directory where Filebeat will write data to in order to persist registry data across pod restarts (file position and other metadata).
hostPathRoot: /var/lib $ helm install -n kibana --namespace=logs ./kibana
查看状态,因为是DaemonSet类型所以每台node都会装一个。
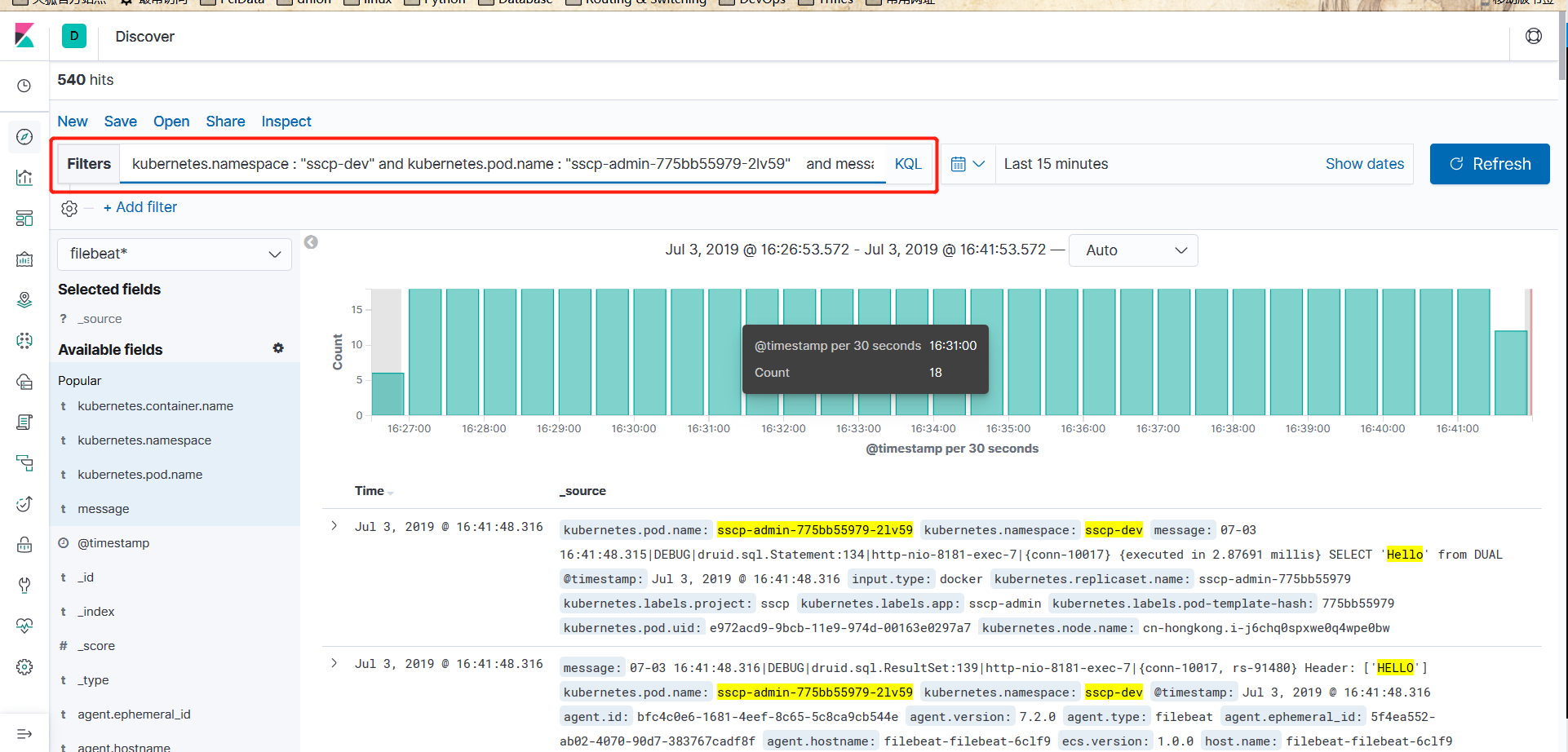
使用
登录kibana,创建index

可以过滤日志
EFK(Elasticsearch+Filebeat+Kibana)收集容器日志的更多相关文章
- Kubernetes部署ELK并使用Filebeat收集容器日志
本文的试验环境为CentOS 7.3,Kubernetes集群为1.11.2,安装步骤参见kubeadm安装kubernetes V1.11.1 集群 1. 环境准备 Elasticsearch运行时 ...
- K8S 使用 SideCar 模式部署 Filebeat 收集容器日志
对于 K8S 内的容器日志收集,业内一般有两种常用的方式: 使用 DaemonSet 在每台 Node 上部署一个日志收集容器,用于收集当前 Node 上所有容器挂载到宿主机目录下的日志 使用 Sid ...
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- ELK日志分析系统(2)-logspout收集容器日志
1. 概述 安装了ELK之后,就是要考虑怎么获取log数据了. 收集log数据的方式有很多种: 1). beats采集数据发布到logstash 2). Filebeat采集数据发布到logstash ...
- ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建
一.ELK搜索引擎原理介绍 在使用搜索引擎是你可能会觉得很简单方便,只需要在搜索栏输入想要的关键字就能显示出想要的结果.但在这简单的操作背后是搜索引擎复杂的逻辑和许多组件协同工作的结果. 搜索引擎的组 ...
- Elasticsearch,Filebeat,Kibana部署,添加图表及elastalert报警
服务端安装 Elasticsearch和Kibana(需要安装openjdk1.8以上) 安装方法:https://www.elastic.co以Ubuntu为例: wget -qO - https: ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
- Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日志集中分析平台
日志监控和分析在保障业务稳定运行时,起到了很重要的作用,不过一般情况下日志都分散在各个生产服务器,且开发人员无法登陆生产服务器,这时候就需要一个集中式的日志收集装置,对日志中的关键字进行监控,触发异常 ...
- ELK( ElasticSearch+ Logstash+ Kibana)分布式日志系统部署文档
开始在公司实施的小应用,慢慢完善之~~~~~~~~文档制作 了好作运维同事之间的前期普及.. ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 软件下载地址: https://www.e ...
随机推荐
- js数组、对象处理
js arry: var arry = []; js object: var obj = {}; obj定义属性: obj.filename=''; obj.id=''; 把 obj 添加到 arry ...
- osg geometry清空vertex
_vertices->clear(); _vertices->dirty(); _drawArrays->set(sog::PrimitiveSet::POINTS,0,0); _g ...
- osgb文件过大,可以通过Compressor=zlib对纹理进行压缩
osg::ref_ptr<osgDB::ReaderWriter::Options> options = new osgDB::ReaderWriter::Options; options ...
- python网络编程 - tcp
网络编程 低级别的网络服务 高级别的网络服务 socket又称“套接字”,应用程序通过“套接字”向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯. tcp 传输控制协议(Tra ...
- 【LeetCode算法-53】Maximum Subarray
Given an integer array nums, find the contiguous subarray (containing at least one number) which has ...
- requests库学习案例
requests库使用流程 使用流程/编码流程 1.指定url 2.基于requests模块发起请求 3.获取响应对象中的数据值 4.持久化存储 分析案例 需求:爬取搜狗首页的页面数据 # 爬取搜狗首 ...
- VC++6.0 打印调试信息
1.在MFC中加入TRACE语句 2.在TOOLS->MFC TRACER中选择 “ENABLE TRACING”点击OK 3.进行调试运行,GO(F5)(特别注意:不是执行‘!’以前之所以不能 ...
- 安装 python 爬虫框架 Scrapy
官方安装说明文档:https://doc.scrapy.org/en/latest/intro/install.html#installing-scrapy 一.scrapy 需要以下依赖 二.一般来 ...
- Leetcode problems classified by company 题目按公司分类(Last updated: October 2, 2017)
All LeetCode Questions List 题目汇总 Sorted by frequency of problems that appear in real interviews. Las ...
- 【SSH进阶之路】Hibernate系列——总结篇(九)
这篇博文是Hibernate系列的最后一篇,既然是最后一篇,我们就应该进行一下从头到尾,整体上的总结,将这个系列的内容融会贯通. 概念 Hibernate是一个对象关系映射框架,当然从分层的角度看,我 ...