Spark 总结2
网页访问时候 没有打开
注意防火墙!

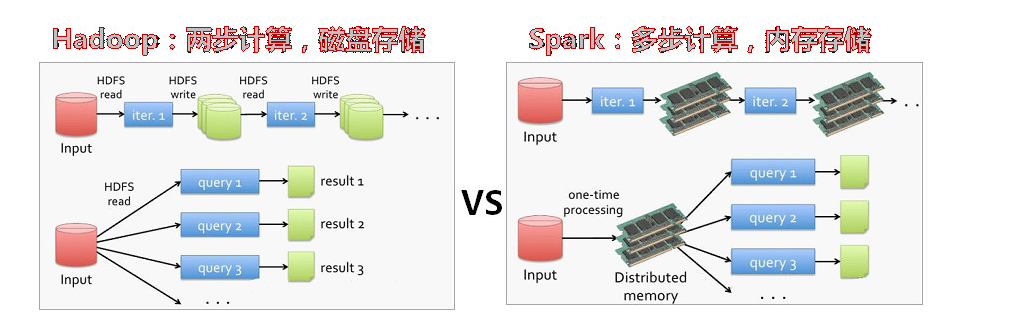
启动park shell
bin下面的spark-shell 这样启动的是单机版的
可以看到没有接入集群中:

应该这么玩儿 用park协议 spark://192.168.94.132:7077 地址 协议
./spark-shell --mster spark://192.168.94.132:7077
必须指定启动资源!!
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。总结的非常好!!!!!!
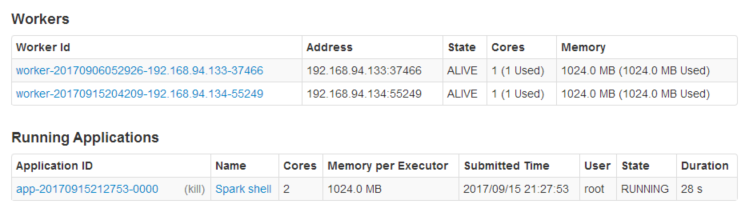
指定资源:

SparkContext (sc)
通向spark集群的一个入口 通过它来提交任务
Spark 总结2的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
随机推荐
- 服务器之FRU
EEPROM是server主板上的电可擦除可编程只读存储器, 里面存储了FRU data, 包括制造商,产品型号,产品序列号,资产序列号等信息,为厂商和客户提供资产信息管理. 所以正确的FRU格式以及 ...
- Consul1 在window7安装
1.从下载地址:https://www.consul.io/downloads.html下载解压到某一地方.以本机为例:既解压到D:/tool下 2. 将consul.exe文件所在的文件路径添加到 ...
- vue起手式
主要步骤 安装node 安装npm 安装vue-cli(vue命令行工具) 初始化一个vue项目 进行开发 # 安装node # 安装npm # 安装cnpm,在中国大陆防止被墙 # 安装git # ...
- Android无线测试之—UiAutomator UiSelector API介绍之五
对象搜索—文本与描述 一.文本属性定位对象: 返回值 API 描述 UiSelector test(String text) 文本完全匹配 UiSelector testContains(String ...
- python MD5操作
def my_md5(str): import hashlib new_str = str.encode() #把字符串转成bytes类型 # new_str = b'%s'%str #把字符串转成b ...
- windows下在Eclipse中启动的tomcat没有乱码,单独部署到tomcat下乱码解决方案
今天遇到了一个很奇怪的问题,在Eclipse中调试,运行项目一切正常,项目的所有编码都是统一的UTF-8.但是在单独部署到tomcat上的时候出现了中文乱码. 解决方案 第一步:确保项目,jsp页面, ...
- FW 执行Git命令时出现各种 SSL certificate problem 的解决办法
比如我在windows下用Git clone gitURL 就提示 SSL certificate problem: self signed certificate 这种问题,在windows下出现 ...
- 【转】NPIV - 连接虚拟机与存储的桥梁
转自:http://blog.csdn.net/jewes/article/details/7705895 解决什么问题 我们知道在存储区域网络(SAN:storage area network),主 ...
- JS基础知识简介
使用js的三种方式 1.HTML标签内嵌js <button onclick="javascript:alert(真点啊)">有本事点我</button> ...
- MySQL复制(一):复制的基本步骤
从这里开始,对复制的内容开始做一些详细的描述,复制从简单到入门 复制最简单的模式如下 基本的三个简单步骤 1 配置一个服务器为master 2 配置一个服务器为slave 3 将slave连接到mas ...