Hadoop-HA(高可用)集群搭建
Hadoop-HA集群搭建
一、基础准备工作
1、准备好5台Linux系统虚拟服务器或物理服务器
我这里演示采用虚拟服务器搭建Hadoop-HA集群,各自功能分配如下:
NameNode节点:vt-serv、vt-serv4
DataNode节点:vt-serv1、vt-serv2、vt-serv3
Journalnode节点:vt-serv1、vt-serv2、vt-serv3
Zookeeper服务器:vt-serv1、vt-serv2、vt-serv3
mysql数据库:vt-serv
Hive数据仓库:vt-serv4
注:这5台服务器已经配置好了JDK1.8、Zookeeper、mysql-5.6等必备工具及基本环境,这些基础配置以及Hive在这里不作介绍!
2、在每台服务器上创建共同的账号:hadoop ;以及工作组:bigdata
#添加工作组
$ groupadd bigdata
#添加用户到指定工作组
$ useradd -g bigdata hadoop
3、配置hadoop账户在服务器之间进行免密登录
① 在各服务器上生成密钥
#在hadoop用户下生成密钥
$ ssh-keygen -t rsa
② 将每一台服务器生成的密钥整合到同一台服务器(每一台服务器上执行)
#整合密钥
$ ssh-copy-id vt-serv
③ 将整合成功的密钥分发到其它几台服务器
#分发密钥
scp ~/.ssh/authorized_keys vt-serv1:~/.ssh/
scp ~/.ssh/authorized_keys vt-serv2:~/.ssh/
scp ~/.ssh/authorized_keys vt-serv3:~/.ssh/
scp ~/.ssh/authorized_keys vt-serv4:~/.ssh/
④ 修改authorized_keys权限(只允许自己可以读写,权限过大系统会拒绝远程登录;同样每一台服务器都执行)
#修改权限
$ chmod 500 ~/.ssh/authorized_keys
⑤ 测试远程登录(任意服务器之间进行登录操作验证,如果能直接登录到对方服务器就表示配置OK!)
#vt-serv上验证免密登录
$ ssh vt-serv4
二、HA高可用集群搭建
1、准备好hadoop安装包
我这是用的是hadoop-2.7.6.tar.gz 官网提供
2、创建hadoop工作目录
#创建目录
$ mkdir -p /opt/bigdata/HA
$ mkdir -p /opt/data/HA/
3、解压安装包
#解压包到工作目录
$ tar -zxf hadoop-2.7.6.tar.gz /opt/bigdata/
4、配置core-site.xml文件
####core-site.xml begin#####
<configuration>
<!-- 指定hadoop运行时临时目录位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/HA/tmp</value>
</property>
<!-- 把两个NameNode)的地址组装成一个集群mycluster,需要和hdfs-site.xml一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- Zookeeper集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>vt-serv1:2181,vt-serv2:2181,vt-serv3:2181</value>
</property>
</configuration>
####core-site.xml end#####
5、配置hdfs-site.xml文件
####hdfs-site.xml begin#####
<configuration>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>vt-serv:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>vt-serv4:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>vt-serv:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>vt-serv4:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置(单数) -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://vt-serv1:8485;vt-serv2:8485;vt-serv3:8485/mycluster</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/HA/journal</value>
</property>
<!-- namenode文件路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/data/HA/name</value>
</property>
<!-- datanode文件路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/data/HA/data</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 开启故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
####hdfs-site.xml end#####
6、编辑slaves 加入数据节点服务器名
#编辑slaves文件
$ vi /opt/bigdata/HA/hadoop-2.7.6/etc/hadoop/slaves
#加入我的数据节点服务器名称
vt-serv1
vt-serv2
vt-serv3
7、将配置好的hadoop分发到各台服务器相同目录
#文件分发
$ scp -r /opt/bigdata/HA/hadoop-2.7.6/ vm-serv2:/opt/bigdata/HA/
8、启动JournalNode(我的JournalNode配置的分别是vt-serv1 、vt-serv2、vt-serv3三台服务器,分别去启动)
$ hadoop-daemon.sh start journalnode
9、在nn1格式化namenode
#格式化namenode这是关键的一步
$ hdfs namenode -format
10、在nn1启动namenode
$ hadoop-daemon.sh start namenode
11、在nn2同步namenode
$ hdfs namenode -bootstrapStandby
12、格式zookeeper zkfc数据(需要先保证Zookeeper是正常启动)
$ hdfs zkfc -formatZK
13、启动HDFS HA集群(在哪台namenode启动,则作为active)
$ start-dfs.sh
14、验证(停止 actived 那台服务器的 namenode)
$ hadoop-daemon.sh stop namenode
正常情况下集群会把另一台namenode的standby状态自动切换为active状态 至此Hadoop-HA高可用集群配置完毕!
15、配置本地虚拟域名(路径:C:\Windows\System32\drivers\etc\hosts)加入自己的虚拟域名
#加入我的namenode服务器的虚拟域名
192.168.56.10 vt-serv
192.168.56.14 vt-serv4
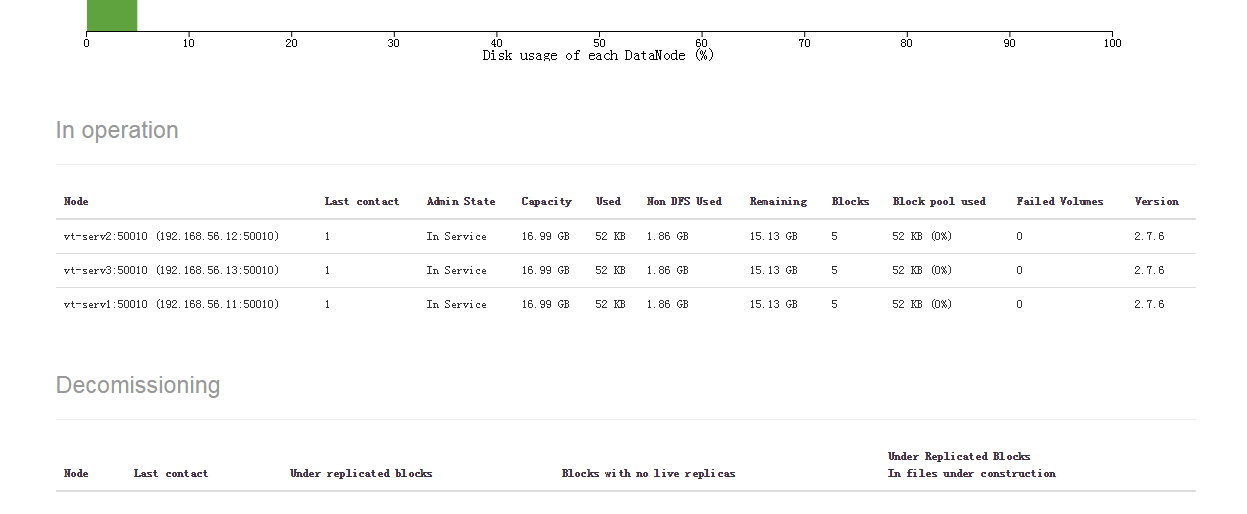
16、访问http://vt-serv:50070

Datanodes页面可以看到我的三台数据节点服务器已经加入服务
17、在Hadoop上创建目录
#创建目录
$ hdfs dfs -mkdir /tmp
18、附上我的Hadoop-HA集群启动脚本代码
#!/bin/sh # 1.声明需要操作的服务器
zkservs=("vt-serv1" "vt-serv2" "vt-serv3")
hadoopServs=("vt-serv" "vt-serv1" "vt-serv2" "vt-serv3" "vt-serv4")
namenode="vt-serv" # 2.循环执行启动Zookeeper命令
echo -e "\033[34m ===============启动Zookeeper===============\033[0m"
for zkserv in ${zkservs[@]}
do
ssh $zkserv 'zkServer.sh start'
done # 3.检查Zookeeper状态
echo -e "\033[34m =============== 检查Zookeeper状态 ===============\033[0m"
for zkserv in ${zkservs[@]}
do
echo -e "\033[34m =============== ZK-$zkserv 状态 ===============\033[0m"
ssh $zkserv 'zkServer.sh status'
done # 4.启动start-dfs.sh
echo -e "\033[34m =============== 启动Hadoop-HA ===============\033[0m"
ssh $namenode 'start-dfs.sh' # 5.检查HDFS是否启动成功
echo -e "\033[34m =============== 检查Hadoop状态 ===============\033[0m"
for hdserv in ${hadoopServs[@]}
do
echo -e "===============Hadoop-$hdserv 进程 ==============="
ssh $hdserv 'jps'
done
# 6.Hadoop-HA集群启动完成
echo -e "\033[34m =============== Hadoop-HA集群启动完成 ===============\033[0m"
Hadoop-HA(高可用)集群搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- Hadoop HA 高可用集群搭建
一.首先配置集群信息 vi /etc/hosts 二.安装zookeeper 1.解压至/usr/hadoop/下 .tar.gz -C /usr/hadoop/ 2.进入/usr/hadoop/zo ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
- HDFS-HA高可用集群搭建
HA高可用集群搭建 1.总体集群规划 在hadoop102.hadoop103和hadoop104三个节点上部署Zookeeper. hadoop102 hadoop103 hadoop104 Nam ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
随机推荐
- 微服务架构下分布式事务解决方案——阿里云GTS
https://blog.csdn.net/jiangyu_gts/article/details/79470240 1 微服务的发展 微服务倡导将复杂的单体应用拆分为若干个功能简单.松耦合的服务,这 ...
- 老男孩Day9作业:高级FTP
一.作业需求 1. 用户加密认证(已完成) 2. 多用户同时登陆(已完成) 3. 每个用户有自己的家目录且只能访问自己的家目录(已完成) 4. 对用户进行磁盘配额.不同用户配额可不同(已完成) 5. ...
- Xamarin Forms:小马过河,王者归来
因为我媳妇的原因,去年下半年从零开始学习Android原生开发,做了一个答题库app.整体给我的感觉是入门难度不大,前期折腾一番,大部分时间都是花在开发上面,其实任何一门语言都是如此. 今年我又有另一 ...
- win10在CMD操作MySQL时中文显示乱码
根据网上说明直接修改数据库各种的字符集没有效果,后来经过测试发现需要先更换至旧版CMD才行. 具体总流程如下: 1.在边框栏上右键,打开属性栏. 2.选择“使用旧版控制台” 3.重启CMD,并设置字符 ...
- 自旋锁Spin lock与互斥锁Mutex的区别
POSIX threads(简称Pthreads)是在多核平台上进行并行编程的一套常用的API.线程同步(Thread Synchronization)是并行编程中非常重要的通讯手段,其中最典型的应用 ...
- 红蓝对抗 - 蓝队手册(BTFM)(转载)
本文已发表在嘶吼RoarTalk,未经授权,请勿转载! http://www.4hou.com/technology/10173.html 最佳阅读体验版:https://stackedit.io/v ...
- Python web前端 06 运算符 循环
Python web前端 06 运算符 循环 一.运算符 #JS六大数据类型 #number 数字 #string 字符串 #boolean 布尔型 #function 函数 #undefined 未 ...
- Python 实现 ZoomEye API SDK
版权声明:未经作者授权,禁止转载! ZoomEye想必大家都很熟悉,自从官方开放了API,网上各种版本的SDK乱飞.今天我也来发一个自己写的. 首先我们从https://github.com/SEC0 ...
- js关于原型,原型链的面试题
之前面试的时候遇到过原型和原型链方面的题目,具体的已经忘了,只记得当时回答的稀里糊涂,今天查了一些资料,把自己所理解的写出来,加深记忆. 1,前提 在js中,对象都有__proto__属性,一般这个是 ...
- vue点击tab跳转页面,给点击的tab添加样式,且解决刷新以后点击的tab样式消失问题
<ul class="nij"> <li v-for="item in nav" @click="selectNav(item.ti ...