Deep Learning —— 异步优化器 —— RMSpropAsync —— 异步RMSprop
看到了一个概念,叫做异步更新优化器,也就是使用异步的方式实现deep learning中的参数优化的method,这个概念比较新奇,虽然看到的异步更新神经网络的代码比较多,但是很少见到有人单独把异步优化器这个概念单独提出来,大部分实现异步更新的算法中都是对各个线程加锁以实现异步更新神经网络参数的。
那么这种单独的异步优化器(RMSpropAsync)和加Lock锁的异步更新参数的方法有什么不同呢?
看了一下其实没啥不同的,可以说基本就是一个东西,只不过实现方法不同而已。我们现在所使用的优化器除了SGD(随机梯度下降)方法外都是要保存之前计算梯度下降的过程结果的,这个过程结果也叫做“二阶动量部分”,使用异步优化器(RMSpropAsync)方法则是在不同线程进行梯度更新时从全局中取出这个之前的计算结果,保存在自己的线程中,因此每个线程在更新时都会单独从全局中取出并保存一份过程结果,并在线程内进行计算并得到更新后的神经网络参数,但是要注意,由于异步优化器(RMSpropAsync)一般不采用加锁的方法,因此在更新“二阶动量部分”和神经网络参数部分已经可能与其他线程发生竞争,因此如果不加锁异步优化器(RMSpropAsync)是不能完全保证线程安全的。
可以说,不加锁的异步优化器(RMSpropAsync)只能一定程度上减少线程竞争带来的不同步问题,但是根据一些网上的资料显示,该种方式其最大优点时加快异步优化器的运算,也就是说提速才是该方法的主要目的。
============================================
不过也有些代码实现对异步优化器(RMSpropAsync)采用了一些微小的差异改变,如:
代码地址:
https://github.com/chainer/chainerrl/blob/master/chainerrl/optimizers/rmsprop_async.py
异步优化器(RMSpropAsync)代码:
def init_state(self, param):
xp = cuda.get_array_module(param.array)
with cuda.get_device_from_array(param.array):
self.state['ms'] = xp.zeros_like(param.array) def update_core_cpu(self, param):
grad = param.grad
if grad is None:
return
hp = self.hyperparam
ms = self.state['ms'] ms *= hp.alpha
ms += (1 - hp.alpha) * grad * grad
param.array -= hp.lr * grad / numpy.sqrt(ms + hp.eps) def update_core_gpu(self, param):
grad = param.grad
if grad is None:
return
cuda.elementwise(
'T grad, T lr, T alpha, T eps',
'T param, T ms',
'''ms = alpha * ms + (1 - alpha) * grad * grad;
param -= lr * grad / sqrt(ms + eps);''',
'rmsprop')(grad, self.hyperparam.lr, self.hyperparam.alpha,
self.hyperparam.eps, param.array, self.state['ms'])
优化器(RMSpropAsync)代码:
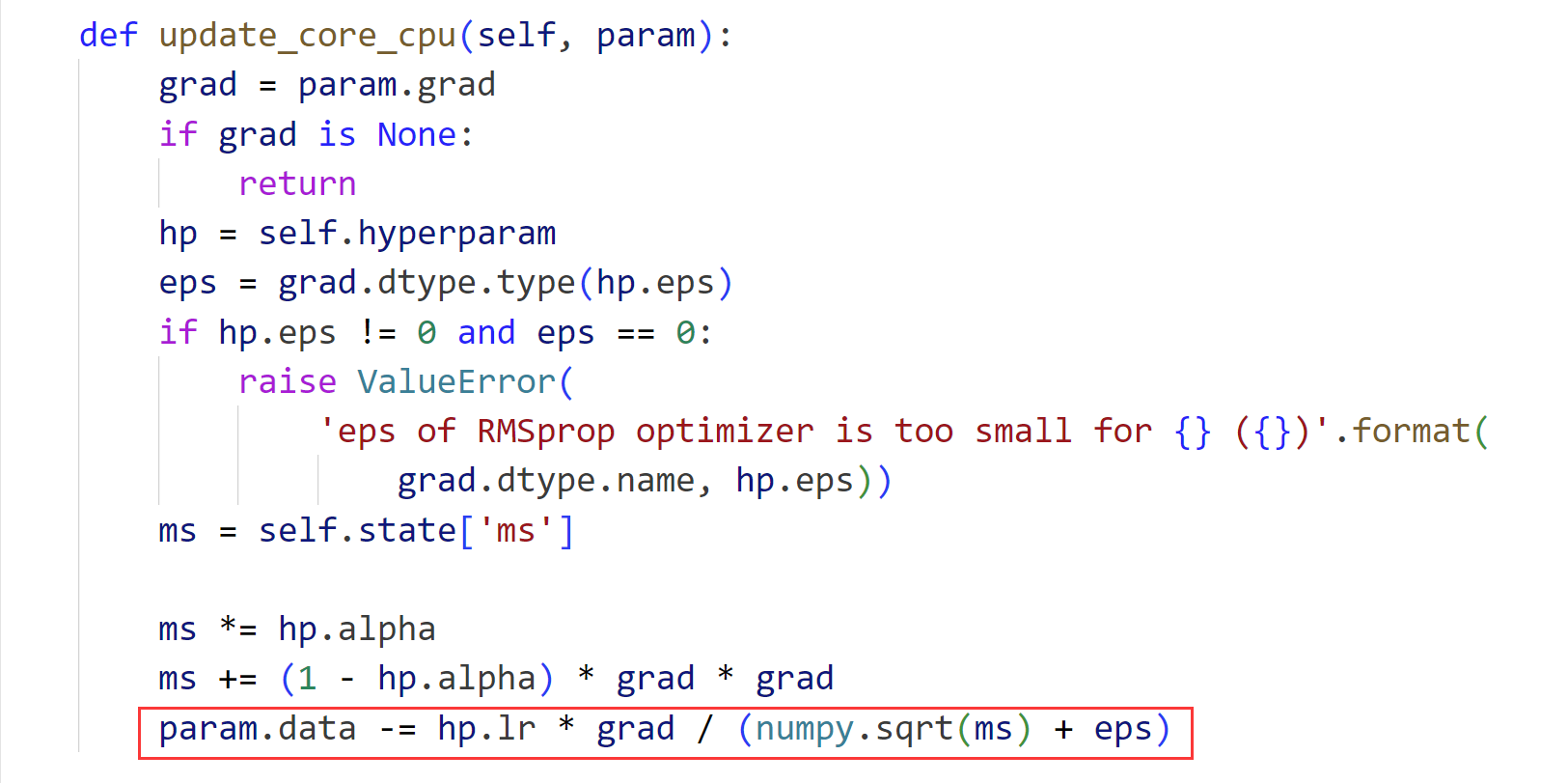
----------------------------------------------------------------------
可以看到在这个框架下所实现的差别是epsilon变量是否在开方运算内:
================================================
附注:


Deep Learning —— 异步优化器 —— RMSpropAsync —— 异步RMSprop的更多相关文章
- (1)Deep Learning之感知器
What is deep learning? 在人工智能领域,有一个方法叫机器学习.在机器学习这个方法里,有一类算法叫神经网络.神经网络如下图所示: 上图中每个圆圈都是一个神经元,每条线表示神经元之间 ...
- 深度学习(deep learning)优化调参细节(trick)
https://blog.csdn.net/h4565445654/article/details/70477979
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- Tensorflow-各种优化器总结与比较
优化器总结 机器学习中,有很多优化方法来试图寻找模型的最优解.比如神经网络中可以采取最基本的梯度下降法. 梯度下降法(Gradient Descent) 梯度下降法是最基本的一类优化器,目前主要分为三 ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- 【python实现卷积神经网络】优化器的实现(SGD、Nesterov、Adagrad、Adadelta、RMSprop、Adam)
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- Yarn源码分析之事件异步分发器AsyncDispatcher
AsyncDispatcher是Yarn中事件异步分发器,它是ResourceManager中的一个基于阻塞队列的分发或者调度事件的组件,其在一个特定的单线程中分派事件,交给AsyncDispatch ...
- 优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization 随机梯度下降(SGD): 当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降:这种情况在高维空间更加普遍. ...
随机推荐
- Windows SERVER 新建FTP 服务器
Windows SERVER 新建FTP 服务器 FTP主机上的操作(本机IP为:192.168.137.2): 1.新建一个名为 ftpa 的Windows用户. 2.在D盘新建一个 FtpBook ...
- EF MYSQL 出现:输入字符串的格式不正确
实体类字段和数据库类型不一致. 比如:数据库是char类型字段,程序里声明为int.
- (三)xpath爬取4K高清美女壁纸
功能:通过xpath爬取彼岸图网的高清美女壁纸 url = 'http://pic.netbian.com/4kmeinv/' 1. 通过url请求整张页面的数据 2.通过页面的标签定位图片所在的位置 ...
- 设置profile启动配置 -Dspring.profiles.active=dev
- 《软件性能测试分析与调优实践之路》第二版-手稿节选-Mysql数据库性能定位与分析
在做MySQL数据的性能定位前,需要先知道MySQL查询时数据库内部的执行过程.只有弄清SQL的执行过程,才能对执行过程中的每一步的性能做定位分析.如图6-2-1所示. 图6-2-1 从图中可以看到, ...
- spring事务传递特性-REQUIRES_NEW和NESTED
spring对于事务的实现的确是它的一大优点,节省了程序员不少时间. 关于事务,有许多可以聊的内容,例如实现方式.实现原理.传递特性等. 本文讨论传递特性中的REQUIRES_NEW,NESTED. ...
- 处理 3d 视频的简单理论基础
背景 公司产品需要满足一些带有3d功能的应用场景,需要需要懂得如何处理3d信号.之前在调试以前产品的时候,发现处理3d信号的时候,是由2个画面叠加起来的. 导言 3D视频(或3D信号)为什么是两个画面 ...
- MySQL - CASE WHEN的高级用法
Case语法 CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN conditionN THEN resultN E ...
- Node.js - fs.path模块
首先我有话说,是谁说的学完ajax就可以去vue了,太天真了我,学会js钻出来个ajax,学完ajax钻出来个node.js这一步步的,当然node不会学到太深入把表面的认识一下就可以了,这之后可能更 ...
- .NET CORE 部署提示 An error occurred while starting the application.
错误提示: 解决方法 检查一下nuget引用包 是否更新了版本,如果升级或者降级了版本,需要将新的dll文件更新一下