Deep Learning —— 异步优化器 —— RMSpropAsync —— 异步RMSprop
看到了一个概念,叫做异步更新优化器,也就是使用异步的方式实现deep learning中的参数优化的method,这个概念比较新奇,虽然看到的异步更新神经网络的代码比较多,但是很少见到有人单独把异步优化器这个概念单独提出来,大部分实现异步更新的算法中都是对各个线程加锁以实现异步更新神经网络参数的。
那么这种单独的异步优化器(RMSpropAsync)和加Lock锁的异步更新参数的方法有什么不同呢?
看了一下其实没啥不同的,可以说基本就是一个东西,只不过实现方法不同而已。我们现在所使用的优化器除了SGD(随机梯度下降)方法外都是要保存之前计算梯度下降的过程结果的,这个过程结果也叫做“二阶动量部分”,使用异步优化器(RMSpropAsync)方法则是在不同线程进行梯度更新时从全局中取出这个之前的计算结果,保存在自己的线程中,因此每个线程在更新时都会单独从全局中取出并保存一份过程结果,并在线程内进行计算并得到更新后的神经网络参数,但是要注意,由于异步优化器(RMSpropAsync)一般不采用加锁的方法,因此在更新“二阶动量部分”和神经网络参数部分已经可能与其他线程发生竞争,因此如果不加锁异步优化器(RMSpropAsync)是不能完全保证线程安全的。
可以说,不加锁的异步优化器(RMSpropAsync)只能一定程度上减少线程竞争带来的不同步问题,但是根据一些网上的资料显示,该种方式其最大优点时加快异步优化器的运算,也就是说提速才是该方法的主要目的。
============================================
不过也有些代码实现对异步优化器(RMSpropAsync)采用了一些微小的差异改变,如:
代码地址:
https://github.com/chainer/chainerrl/blob/master/chainerrl/optimizers/rmsprop_async.py
异步优化器(RMSpropAsync)代码:
def init_state(self, param):
xp = cuda.get_array_module(param.array)
with cuda.get_device_from_array(param.array):
self.state['ms'] = xp.zeros_like(param.array) def update_core_cpu(self, param):
grad = param.grad
if grad is None:
return
hp = self.hyperparam
ms = self.state['ms'] ms *= hp.alpha
ms += (1 - hp.alpha) * grad * grad
param.array -= hp.lr * grad / numpy.sqrt(ms + hp.eps) def update_core_gpu(self, param):
grad = param.grad
if grad is None:
return
cuda.elementwise(
'T grad, T lr, T alpha, T eps',
'T param, T ms',
'''ms = alpha * ms + (1 - alpha) * grad * grad;
param -= lr * grad / sqrt(ms + eps);''',
'rmsprop')(grad, self.hyperparam.lr, self.hyperparam.alpha,
self.hyperparam.eps, param.array, self.state['ms'])
优化器(RMSpropAsync)代码:
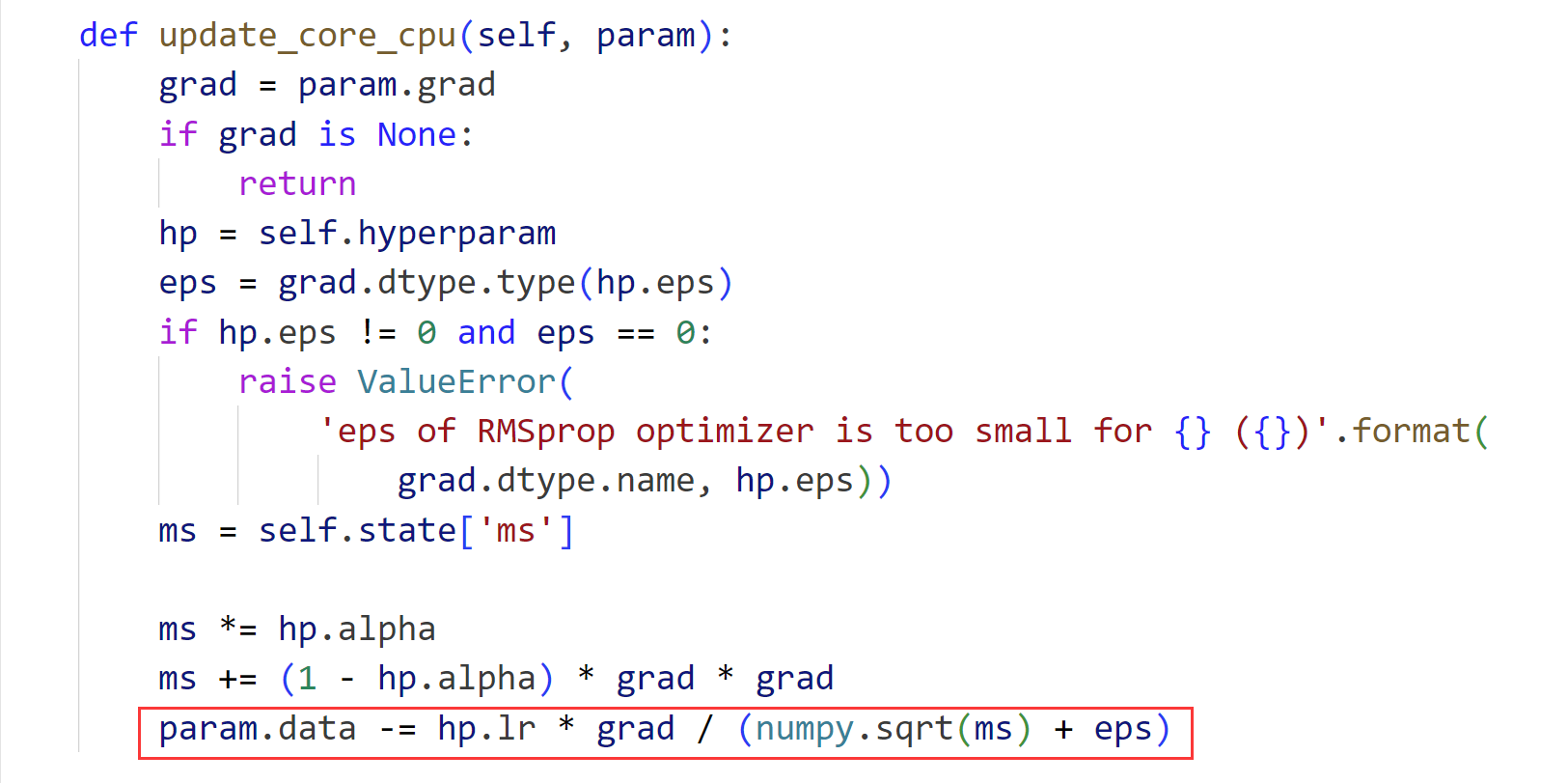
----------------------------------------------------------------------
可以看到在这个框架下所实现的差别是epsilon变量是否在开方运算内:
================================================
附注:


Deep Learning —— 异步优化器 —— RMSpropAsync —— 异步RMSprop的更多相关文章
- (1)Deep Learning之感知器
What is deep learning? 在人工智能领域,有一个方法叫机器学习.在机器学习这个方法里,有一类算法叫神经网络.神经网络如下图所示: 上图中每个圆圈都是一个神经元,每条线表示神经元之间 ...
- 深度学习(deep learning)优化调参细节(trick)
https://blog.csdn.net/h4565445654/article/details/70477979
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- Tensorflow-各种优化器总结与比较
优化器总结 机器学习中,有很多优化方法来试图寻找模型的最优解.比如神经网络中可以采取最基本的梯度下降法. 梯度下降法(Gradient Descent) 梯度下降法是最基本的一类优化器,目前主要分为三 ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- Deep Learning基础--参数优化方法
1. 深度学习流程简介 1)一次性设置(One time setup) -激活函数(Activation functions) - 数据预处理(Data Preprocessing) ...
- 【python实现卷积神经网络】优化器的实现(SGD、Nesterov、Adagrad、Adadelta、RMSprop、Adam)
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- Yarn源码分析之事件异步分发器AsyncDispatcher
AsyncDispatcher是Yarn中事件异步分发器,它是ResourceManager中的一个基于阻塞队列的分发或者调度事件的组件,其在一个特定的单线程中分派事件,交给AsyncDispatch ...
- 优化器,SGD+Momentum;Adagrad;RMSProp;Adam
Optimization 随机梯度下降(SGD): 当损失函数在一个方向很敏感在另一个方向不敏感时,会产生上面的问题,红色的点以“Z”字形梯度下降,而不是以最短距离下降:这种情况在高维空间更加普遍. ...
随机推荐
- go.mod file not found in current directory or any parent directory; see 'go help modules' (exit status 1)
go.mod file not found in current directory or any parent directory; see 'go help modules' (exit stat ...
- 用cvCvtColor转化RGB彩色图像为灰度图像时发生的小失误
版本信息 MAC版本:10.10.5 Xcode版本:7.2 openCV版本:2.4.13 在运行程序的时候发现cvCvtColor的地方程序报错 error: (-215) src.depth() ...
- linux中cp复制时处理软链接的两种方式
linux中cp复制时处理软链接的两种方式 cp -r -L 复制原始文件 cp -r -P 复制软链接本身
- PetaLinux常用命令汇总
创建petalinux工程 Create a new project from a reference BSP file. 用于从官方下载的BSP中抽取数据产生工程. petalinux-create ...
- FFmpeg开发笔记(三十四)Linux环境给FFmpeg集成libsrt和librist
<FFmpeg开发实战:从零基础到短视频上线>一书的"10.2 FFmpeg推流和拉流"提到直播行业存在RTSP和RTMP两种常见的流媒体协议.除此以外,还有比较两 ...
- 2-SET详解
前置知识 SET问题的标准定义:在计算机科学中,布尔可满足性问题(有时称为命题可满足性问题,缩写为SATISFIABILITY或SAT)是确定是否存在满足给定布尔公式的解释的问题.(全是废话) 说人话 ...
- 《DNK210使用指南 -CanMV版 V1.0》第六章 Kendryte K210固件烧录
第六章 Kendryte K210固件烧录 1)实验平台:正点原子DNK210开发板 章节摘自[正点原子]DNK210使用指南 - CanMV版 V1.0 3)购买链接:https://detail. ...
- TI AM62x工业核心板规格书(单/双/四核ARM Cortex-A53 + 单核ARM Cortex-M4F,主频1.4GHz)
1 核心板简介 创龙科技SOM-TL62x是一款基于TI Sitara系列AM62x单/双/四核ARM Cortex-A53 + 单核ARM Cortex-M4F异构多核处理器设计的高性能低功耗工业级 ...
- 怎么判断一个变量arr的话是否为数组(此题用 typeof 不行)?
arr instanceof Array arr.constructor == Array Object.protype.toString.call(arr) == '[Object Array]'
- Java 反射获取对象里的值
最近在负责邮件服务,里面会涉及到很多Email模板,这里我使用到了java的模板引擎:jetbrick-template,需要使用Map集合一个个往里面设置值,然后调用模板方法,进行替换.实体类一个个 ...