Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:

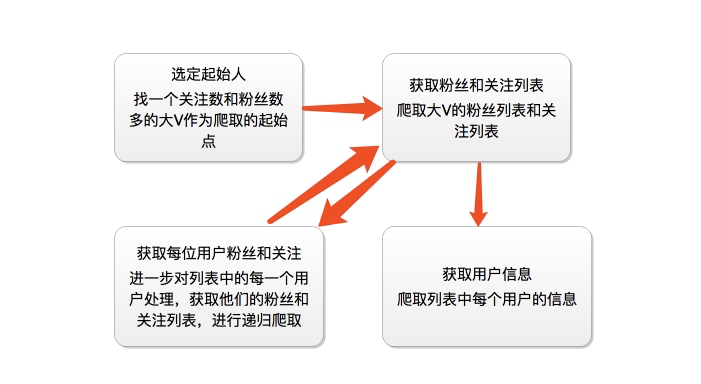
爬虫分析过程
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
我们抓取的大V账号的主要信息是:

其次我们要获取这个账号的关注列表和被关注列表
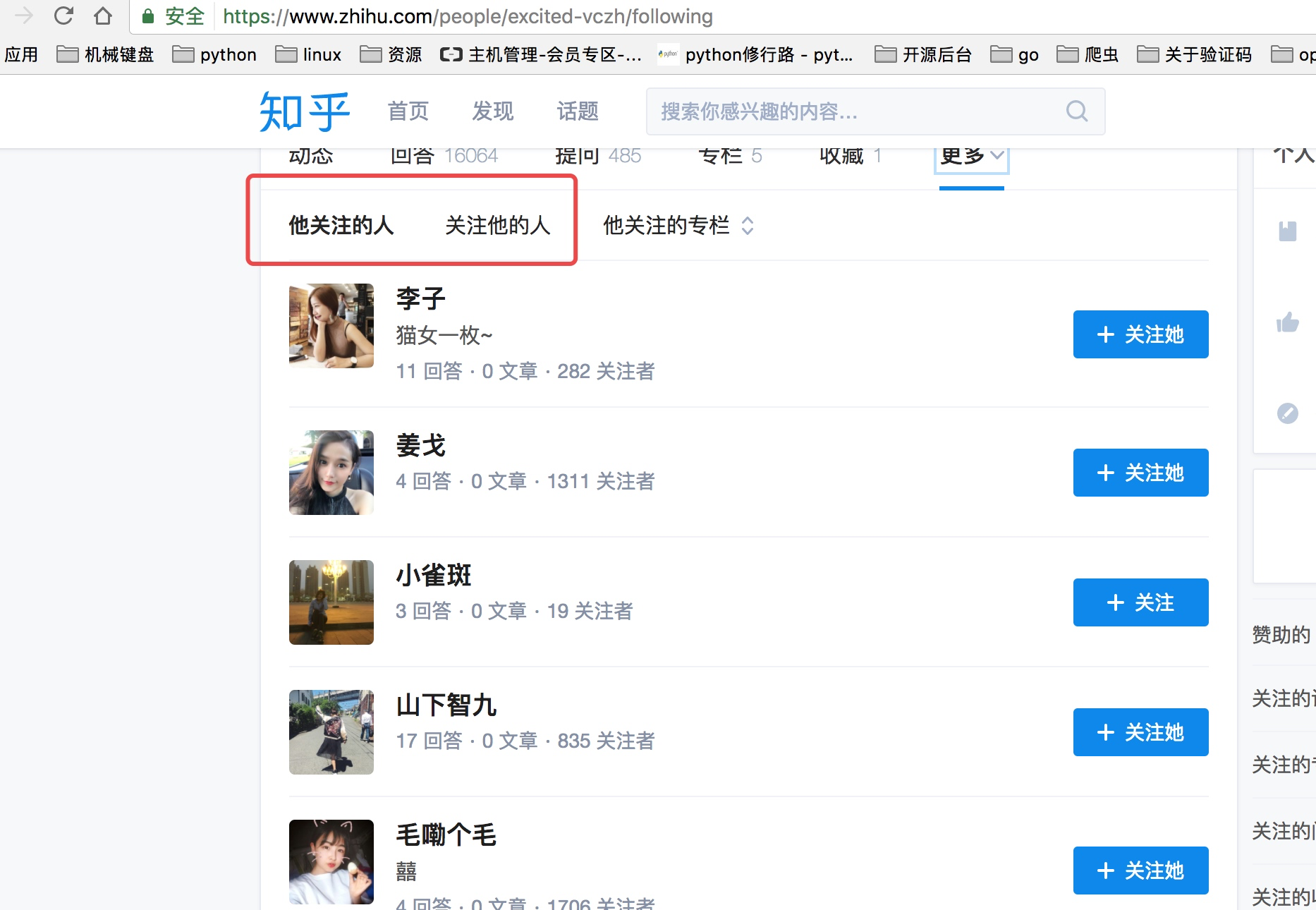
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
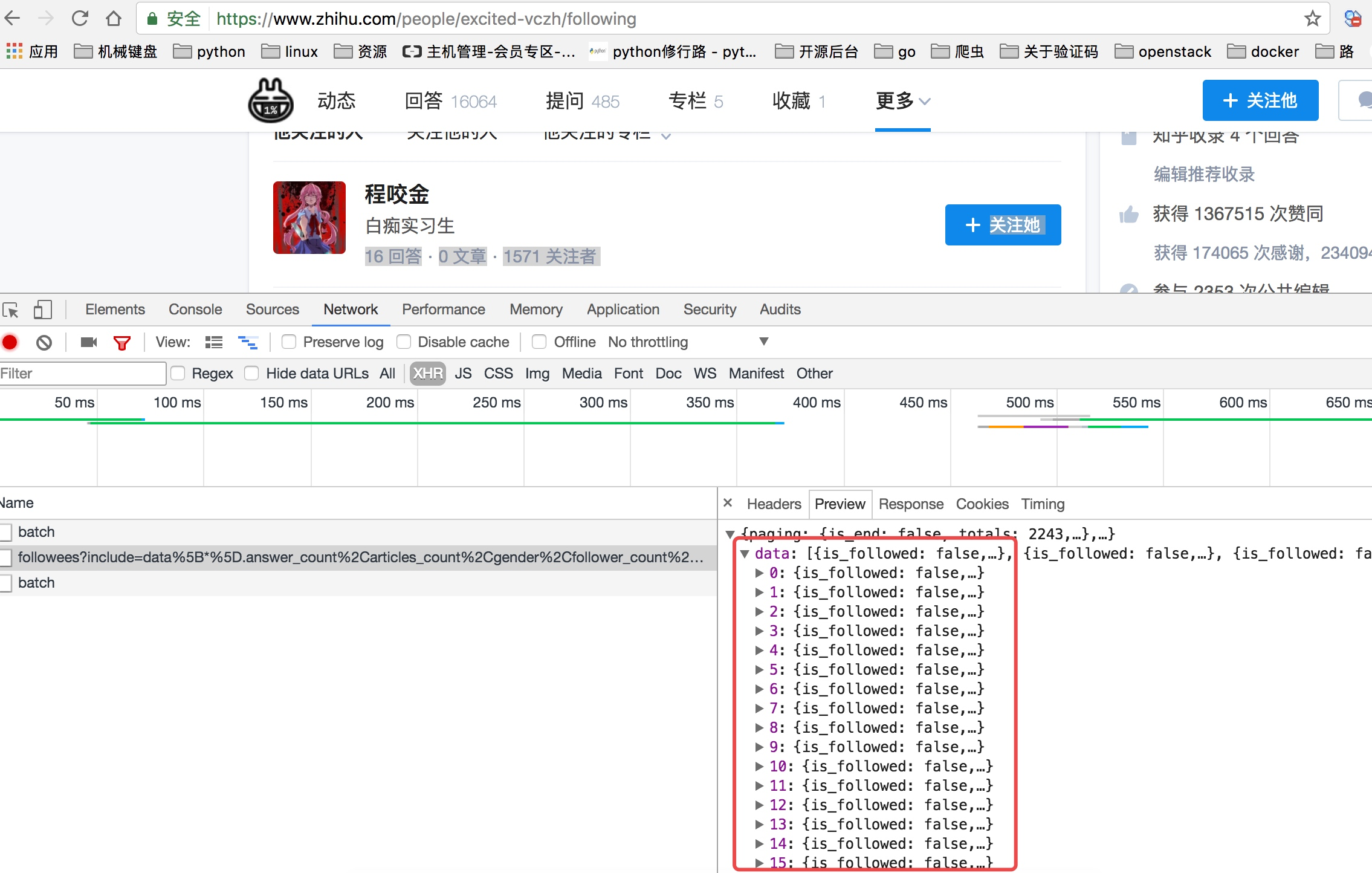
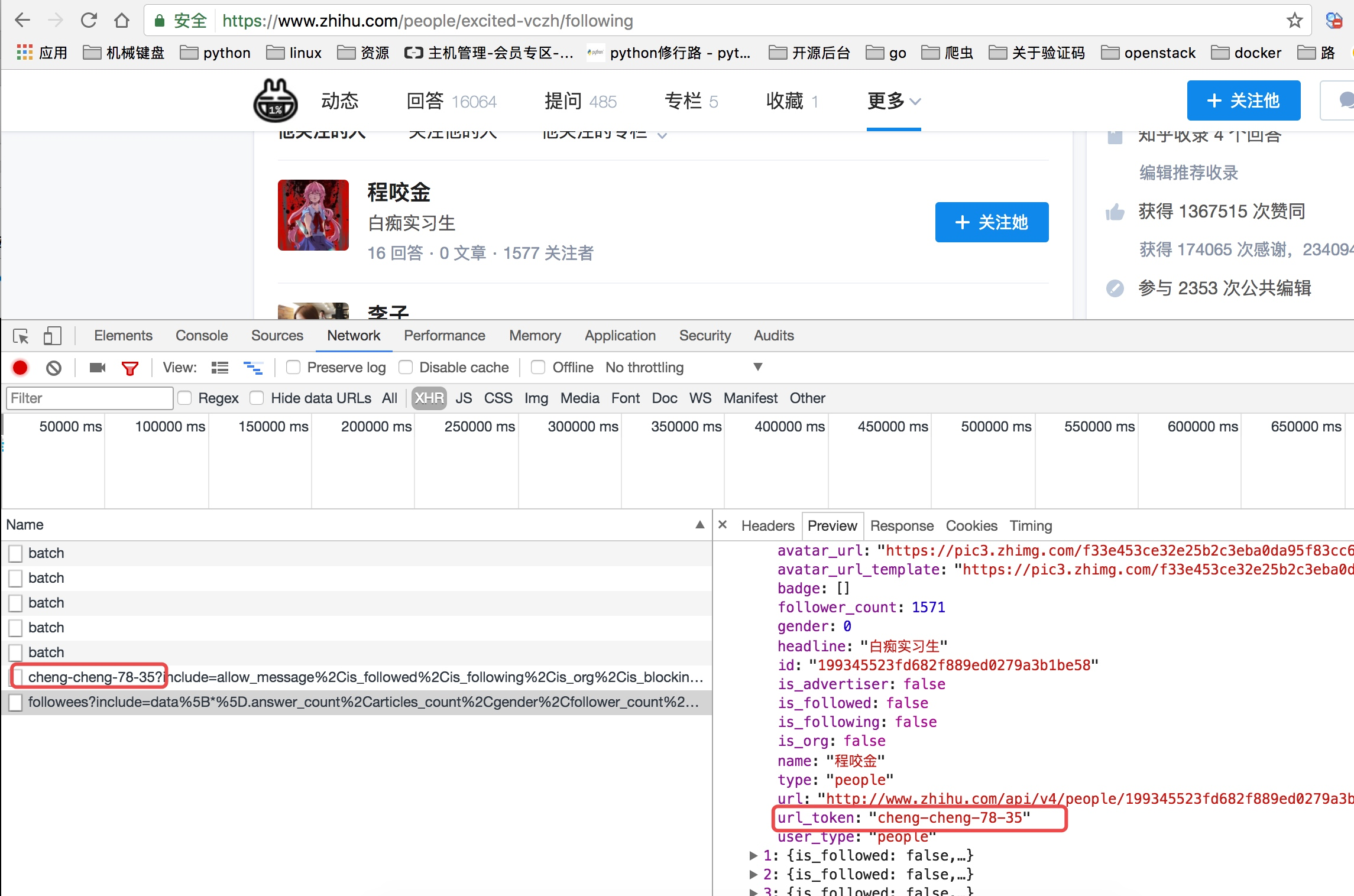
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。


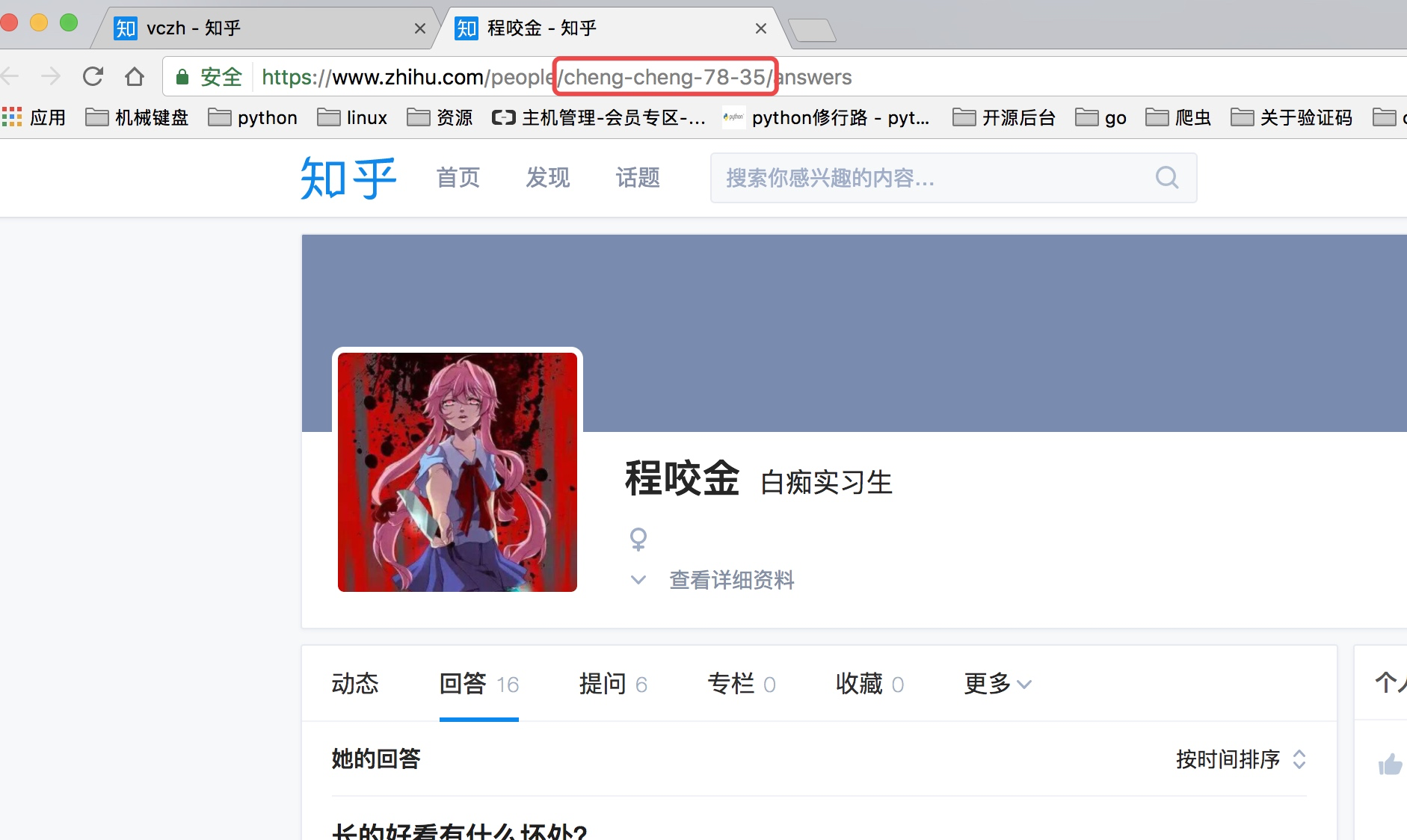
上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:
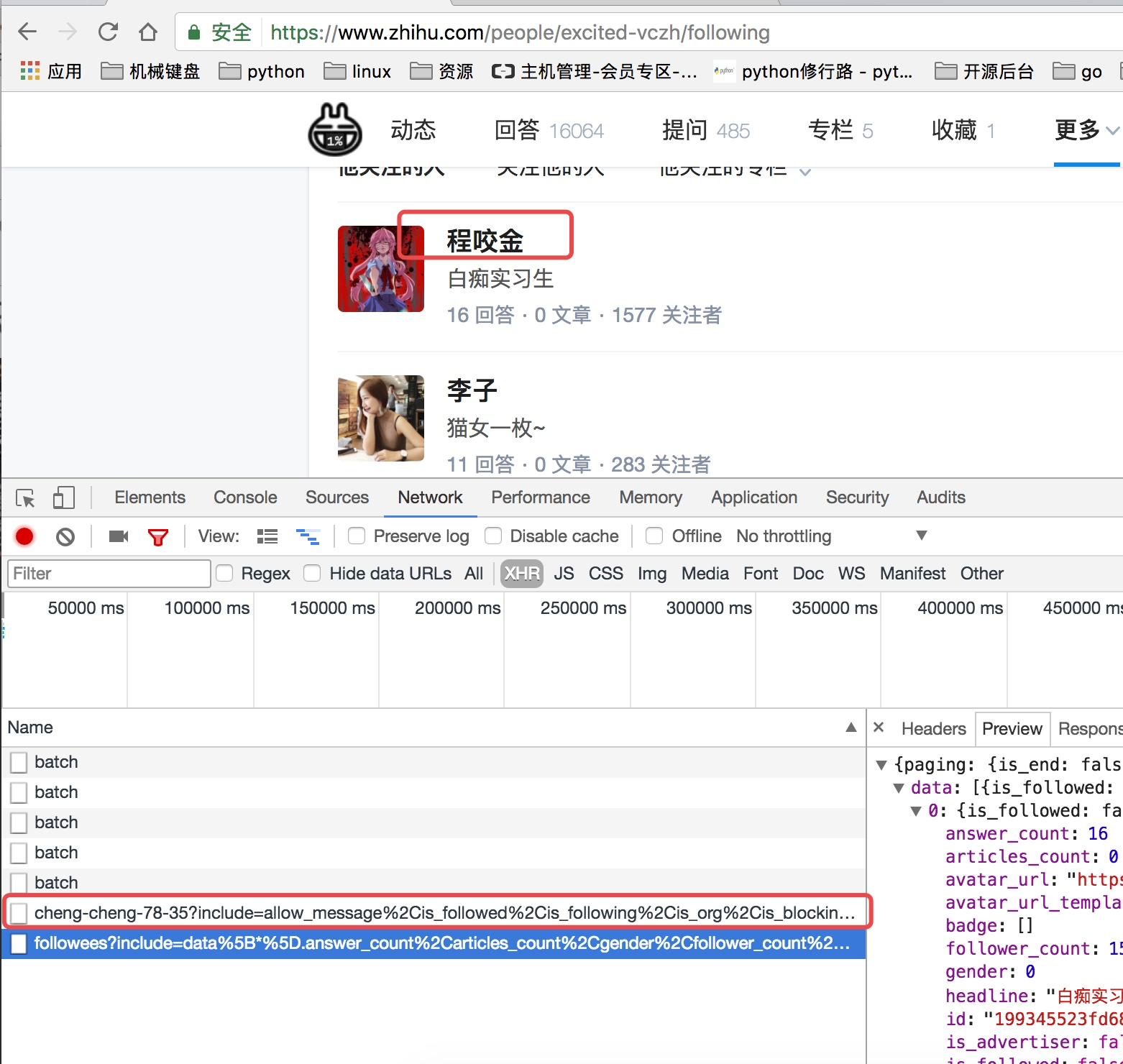
我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:

通过上面的分析我们知道了以下两个地址:
获取用户关注列表的地址:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
获取单个用户详细信息的地址:https://www.zhihu.com/api/v4/members/excited-vczh?include=locations%2Cemployments%2Cgender%2Ceducations%2Cbusiness%2Cvoteup_count%2Cthanked_Count%2Cfollower_count%2Cfollowing_count%2Ccover_url%2Cfollowing_topic_count%2Cfollowing_question_count%2Cfollowing_favlists_count%2Cfollowing_columns_count%2Cavatar_hue%2Canswer_count%2Carticles_count%2Cpins_count%2Cquestion_count%2Ccolumns_count%2Ccommercial_question_count%2Cfavorite_count%2Cfavorited_count%2Clogs_count%2Cmarked_answers_count%2Cmarked_answers_text%2Cmessage_thread_token%2Caccount_status%2Cis_active%2Cis_bind_phone%2Cis_force_renamed%2Cis_bind_sina%2Cis_privacy_protected%2Csina_weibo_url%2Csina_weibo_name%2Cshow_sina_weibo%2Cis_blocking%2Cis_blocked%2Cis_following%2Cis_followed%2Cmutual_followees_count%2Cvote_to_count%2Cvote_from_count%2Cthank_to_count%2Cthank_from_count%2Cthanked_count%2Cdescription%2Chosted_live_count%2Cparticipated_live_count%2Callow_message%2Cindustry_category%2Corg_name%2Corg_homepage%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token
创建项目进行再次分析
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu www.zhihu.com
直接通过scrapy crawl zhihu启动爬虫会看到如下错误:

这个问题其实是爬取网站的时候经常碰到的问题,大家以后见多了就知道是怎么回事了,是请求头的问题,应该在请求头中加User-Agent,在settings配置文件中有关于请求头的配置默认是被注释的,我们可以打开,并且加上User-Agent,如下:
关于如何获取User-Agent,可以在抓包的请求头中看到也可以在谷歌浏览里输入:chrome://version/ 查看
这样我们就可以正常通过代码访问到知乎了
然后我们可以改写第一次的请求,这个我们前面的scrapy文章关于spiders的时候已经说过如何改写start_request,我们让第一次请求分别请求获取用户列表以及获取用户信息

这个时候我们再次启动爬虫

我们会看到是一个401错误,而解决的方法其实还是请求头的问题,从这里我们也可以看出请求头中包含的很多信息都会影响我们爬取这个网站的信息,所以当我们很多时候直接请求网站都无法访问的时候就可以去看看请求头,看看是不是请求头的哪些信息导致了请求的结果,而这里则是因为如下图所示的参数:
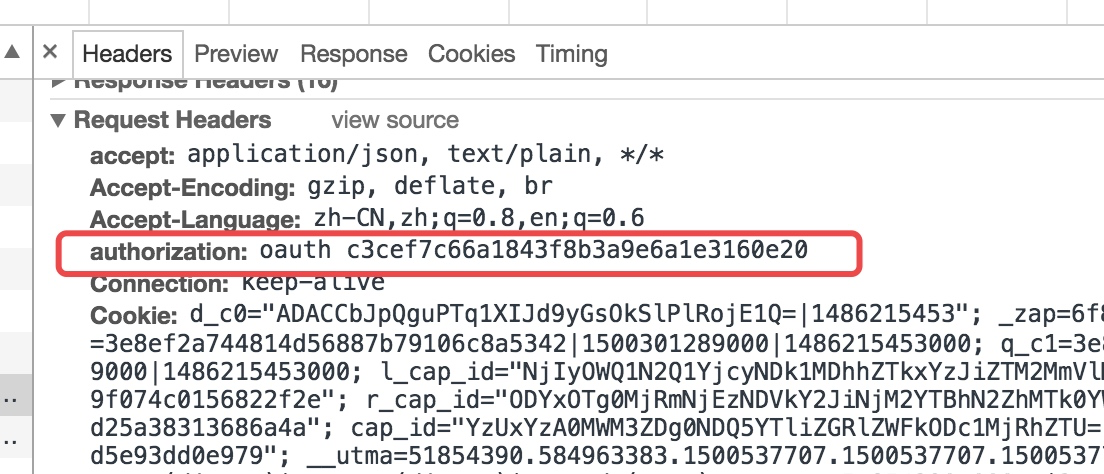
所以我们需要把这个参数同样添加到请求头中:

然后重新启动爬虫,这个时候我们已经可以获取到正常的内容
到此基本的分析可以说是都分析好了,剩下的就是具体代码的实现,在下一篇文张中写具体的实现代码内容!
Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)的更多相关文章
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- 利用Scrapy爬取所有知乎用户详细信息并存至MongoDB
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :崔庆才 本节分享一下爬取知乎用户所有用户信息的 Scrapy 爬虫实战. 本节目标 本节要实现的内容有 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python网络爬虫——Appuim+夜神模拟器爬取得到APP课程数据
一.背景介绍 随着生产力和经济社会的发展,温饱问题基本解决,人们开始追求更高层次的精神文明,开始愿意为知识和内容付费.从2016年开始,内容付费渐渐成为时尚. 罗辑思维创始人罗振宇全力打造" ...
- python爬虫29 | 使用scrapy爬取糗事百科的例子,告诉你它有多厉害!
是时候给你说说 爬虫框架了 使用框架来爬取数据 会节省我们更多时间 很快就能抓取到我们想要抓取的内容 框架集合了许多操作 比如请求,数据解析,存储等等 都可以由框架完成 有些小伙伴就要问了 你他妈的 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
随机推荐
- Python惯用法
目录 1. 不要使用可变类型作为参数的默认值 1. 不要使用可变类型作为参数的默认值 摘自<流畅的Python>8.4.1 class HauntedBus: ""&q ...
- MySQL连接查询驱动表被驱动表以及性能优化
准备我们需要的表结构和数据 两张表 studnet(学生)表和score(成绩)表, 创建表的SQL语句如下 CREATE TABLE `student` ( `id` int(11) NOT NUL ...
- Android中的SharedPreferences存储
一.前言 不同于文件的存储方式,SharedPreferences是使用键值对的方式来存储数据的.也就是说,当保存一条数据的时候,需要给这条数据提供一个对应的键,这样在读取数据的时候就可以通过这个键把 ...
- OS_进程调度:C++实现
实验二.进程调度模拟实验 一.实验目的: 本实验模拟在单处理机环境下的处理机调度,帮助理解进程调度的概念,深入了解进程控制块的功能,以及进程的创建.撤销和进程各个状态间的转换过程. 二.实验内容: 进 ...
- 定时任务Cron
Linux系统中的定时任务cron,一个很实际很有效很简单的一个工作,在日常的生产环境中,会被广泛使用的一个组件.通过设置时间.执行的脚本等内容,能够让系统自动的执行相关任务,很是方便. cron定时 ...
- Java基础-Java中transient有什么用-序列化有那几种方式
此文转载于知乎的一篇文章,看着写的非常全面,分享给大家. 先解释下什么是序列化 我们的对象并不只是存在内存中,还需要传输网络,或者保存起来下次再加载出来用,所以需要Java序列化技术. Java序列化 ...
- 【初学Java学习笔记】AOP与OOP
AOP(Aspect Oriented Programming) 面向切面编程,是属于Spring框架中的内容.AOP相当于OOP的补充,当我们需要对多个对象引入一个公共行为,比如日志,操作记录等,就 ...
- JavaWeb网上图书商城完整项目--day02-14.登录功能的login页面处理
1.现在注册成功之后,我们来到登录页面,登录页面在于 在登录页面.我们也需要向注册页面一样对登录的用户名.密码 验证码等在jsp页面中进行校验,校验我们单独放置一个login.js文件中进行处理,然后 ...
- 第三方登陆--QQ登陆
从零玩转第三方QQ登陆 在真正开始对接之前,我们先来聊一聊后台的方案设计.既然是对接第三方登录,那就免不了如何将用户信息保存.首先需要明确一点的是,用户在第三方登录成功之后, 我们能拿到的仅仅是一个代 ...
- SQL注入之常用工具sqlmap
通常来说,验证一个页面是否存在注入漏洞比较简单,而要获取数据,扩大权限,则要输入很复杂的SQL语句,有时候我们还会对大量的URL进行测试,这时就需要用到工具来帮助我们进行注入了. 目前流行的注入工具有 ...