深入了解Kafka【一】概述与基础架构

1、概述
Kafka是一个分布式的、基于发布订阅的消息系统,主要解决应用解耦、异步消息、流量削峰等问题。
2、发布订阅模型
消息生产者将消息发布到Topic中,同时有多个消息消费者订阅该消息,消费者消费数据之后,并不会清除消息。属于一对多的模式,如图:
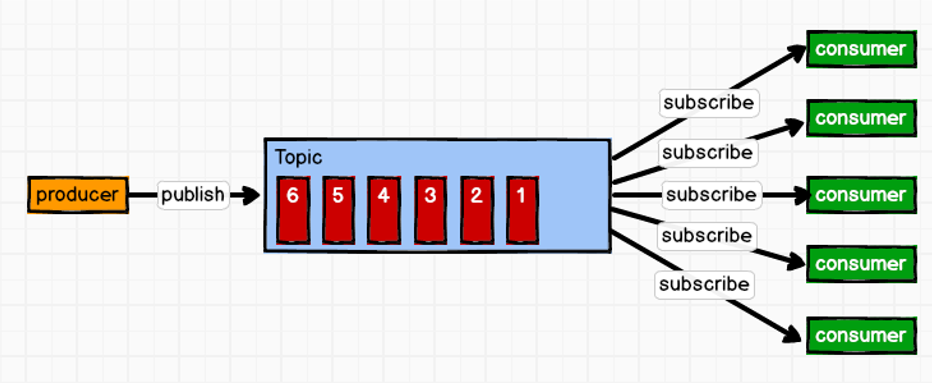
3、系统架构
网上找了个不错的架构图:
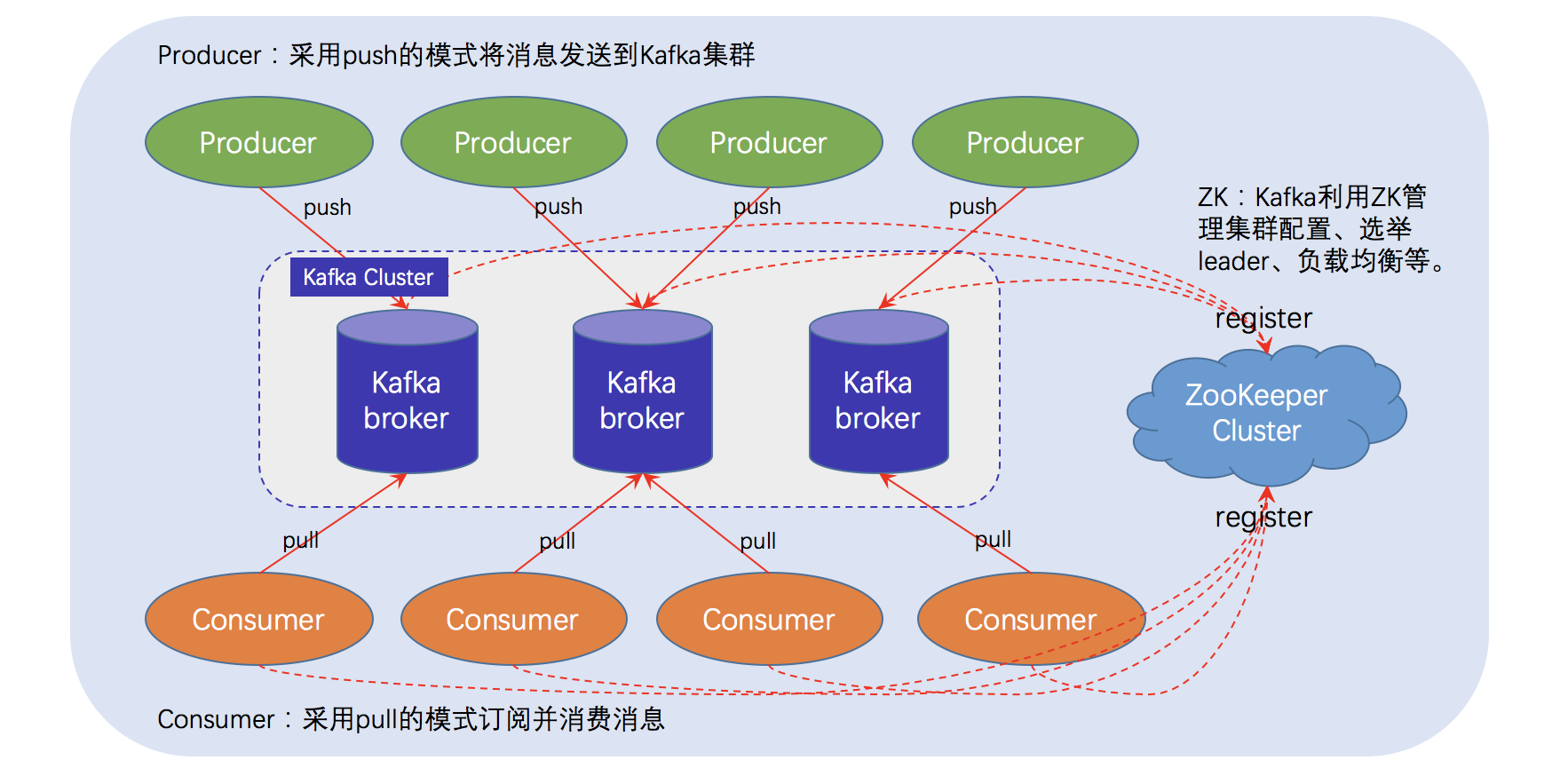
上图中标识了一个kafka体系架构包括若干Producer、Broker、Consumer和一个zookeeper集群。
再贴两张带有Topic和Partition的架构图:
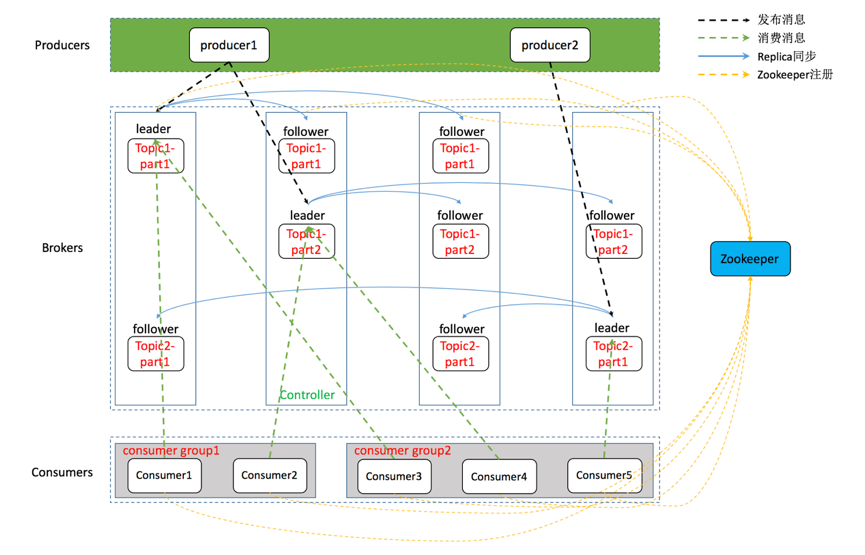
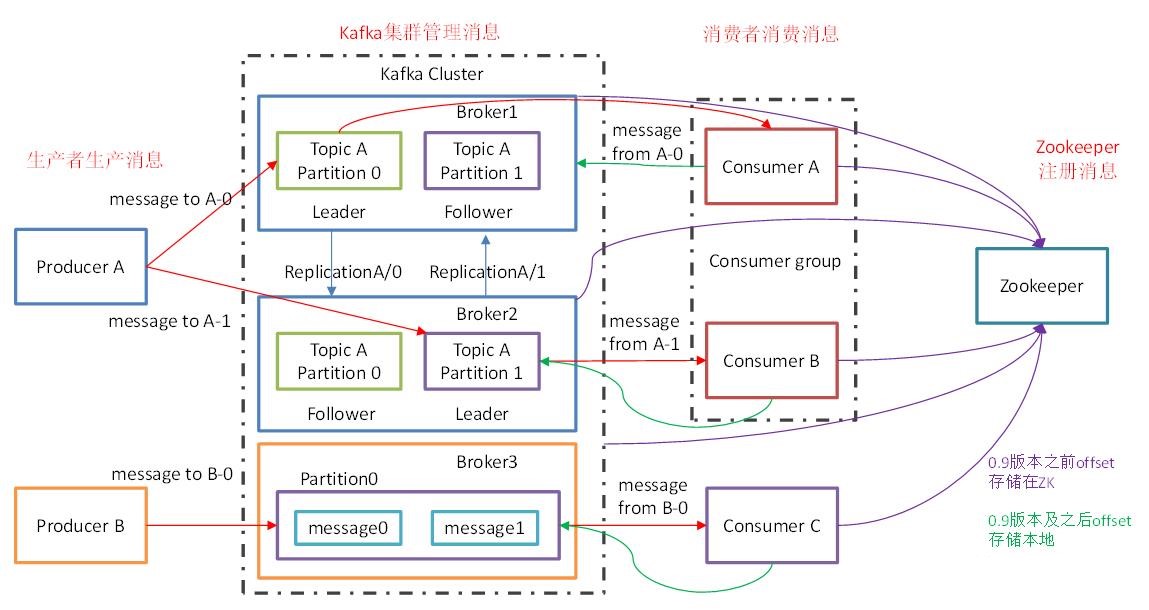
下面介绍一下各个角色:
3.1、Producer
消息生产者,将消息push到Kafka集群中的Broker。
3.2、Consumer
消息消费者,从Kafka集群中pull消息,消费消息。
3.3、Consumer Group
消费者组,由一到多个Consumer组成,每个Consumer都属于一个Consumer Group。消费者组在逻辑上是一个订阅者。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。
即每条消息只能被Consumer Group中的一个Consumer消费;但是可以被多个Consumer Group组消费。这样就实现了单播和多播。
3.4、Broker
一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,每个Broker可以容纳多个Topic.
3.5、Topic
消息的类别或者主题,逻辑上可以理解为队列。Producer只关注push消息到哪个Topic,Consumer只关注订阅了哪个Topic。
3.6、Partition
负载均衡与扩展性考虑,一个Topic可以分为多个Partition,物理存储在Kafka集群中的多个Broker上。可靠性上考虑,每个Partition都会有备份Replica。
3.7、Replica
Partition的副本,为了保证集群中的某个节点发生故障时,该节点上的Partition数据不会丢失,且Kafka仍能继续工作,所以Kafka提供了副本机制,一个Topic的每个Partition都有若干个副本,一个Leader和若干个Follower。
3.8、Leader
Replica的主角色,Producer与Consumer只跟Leader交互。
3.9、Follower
Replica的从角色,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会变成新的Leader。
3.9、Controller
Kafka集群中的其中一台服务器,用来进行Leader election以及各种Failover(故障转移)。
3.9、ZooKeeper
Kafka通过Zookeeper存储集群的meta等信息。
4、Topic和Partition
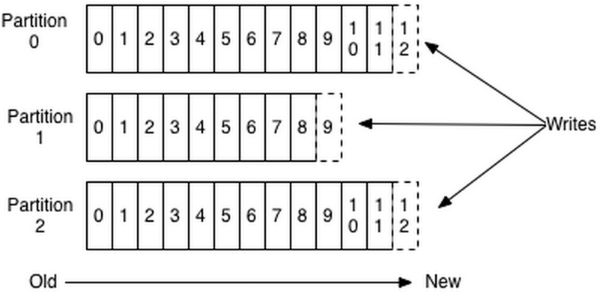
一个Topic可以认为是一类信息,逻辑上的队列,每条消息都要指定Topic。为了使得Kafka的吞吐量可以线性提高,物理上将Topic分成一个或多个Partition。每个Partition在存储层面时append log文件,消息push进来后,会被追加到log文件的尾部,每条消息在文件中的位置成为offset(偏移量),offset是一个long型数字,唯一的标识一条信息。因为每条消息都追加到Partition的尾部,所以属于磁盘的顺序写,效率很高。如图:
5、网络模型
Kafka的网络模型基于Reactor模型,即响应模型。Kafka网络模型分为两部分:Kafka客户端即Consumer和Producer都是单线程的Reactor模型,Kafka服务端是多线程的Reactor模型。
5.1、单线程Reactor
如图:
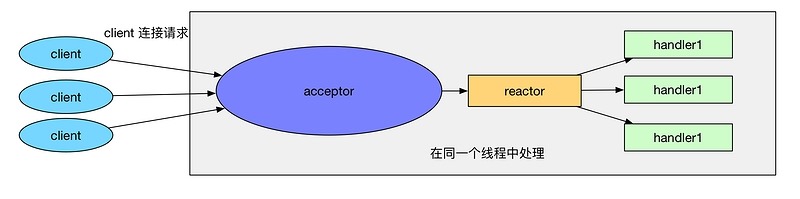
Reactor线程负责多路分离套接字,Accept新连接,并分派请求到Handler处理器。
5.2、多线程Reactor
以下来自;消息中间件—简谈Kafka中的NIO网络通信模型
如图:
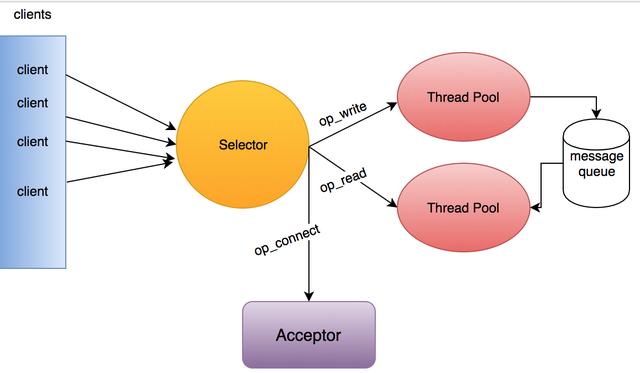
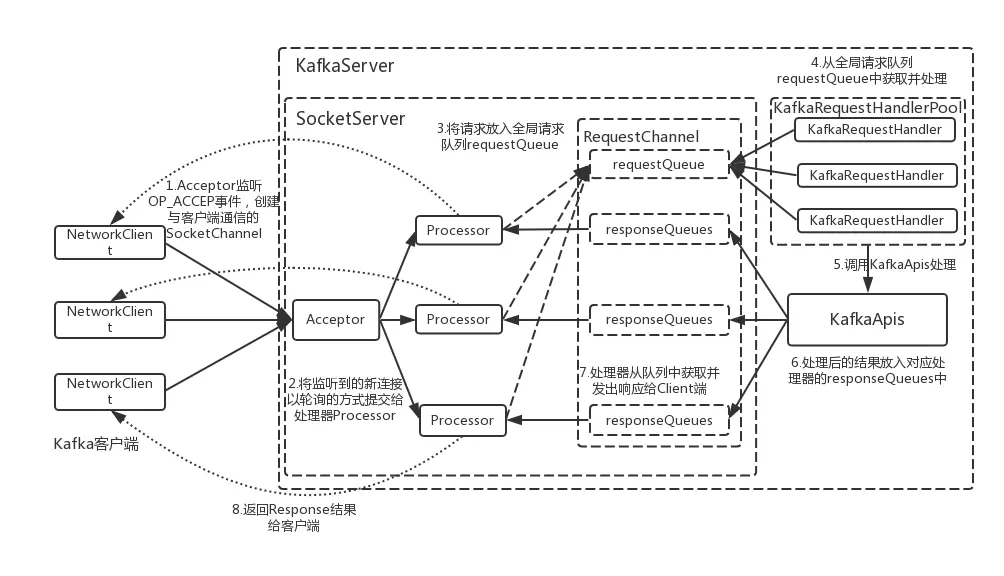
- Acceptor:1个接收线程,负责监听新的连接请求,同时注册OP_ACCEPT 事件,将新的连接按照"round robin"方式交给对应的 Processor 线程处理;
- Processor:N个处理器线程,其中每个 Processor 都有自己的 selector,它会向 Acceptor 分配的 SocketChannel 注册相应的 OP_READ 事件,N 的大小由“num.networker.threads”决定;
- KafkaRequestHandler:M个请求处理线程,包含在线程池—KafkaRequestHandlerPool内部,从RequestChannel的全局请求队列—requestQueue中获取请求数据并交给KafkaApis处理,M的大小由“num.io.threads”决定;
- RequestChannel:其为Kafka服务端的请求通道,该数据结构中包含了一个全局的请求队列 requestQueue和多个与Processor处理器相对应的响应队列responseQueue,提供给Processor与请求处理线程KafkaRequestHandler和KafkaApis交换数据的地方。
- NetworkClient:其底层是对 Java NIO 进行相应的封装,位于Kafka的网络接口层。Kafka消息生产者对象—KafkaProducer的send方法主要调用NetworkClient完成消息发送;
- SocketServer:其是一个NIO的服务,它同时启动一个Acceptor接收线程和多个Processor处理器线程。提供了一种典型的Reactor多线程模式,将接收客户端请求和处理请求相分离;
- KafkaServer:代表了一个Kafka Broker的实例;其startup方法为实例启动的入口;
- KafkaApis:Kafka的业务逻辑处理Api,负责处理不同类型的请求;比如“发送消息”、“获取消息偏移量—offset”和“处理心跳请求”等;
参考
深入浅出理解基于 Kafka 和 ZooKeeper 的分布式消息队列
kafka架构原理
阿里大牛实战归纳——Kafka架构原理
Kafka架构图
Kafka 设计解析(一):Kafka 背景及架构介绍
消息中间件—简谈Kafka中的NIO网络通信模型
Reactor模式

深入了解Kafka【一】概述与基础架构的更多相关文章
- 1.kafka基础架构
kafka基础架构 ## 什么是kafka? Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域. 1.什么是消息队列? 2.使用消息队列的好处 1)解耦 允许你独立的 ...
- [Search Engine] 搜索引擎分类和基础架构概述
大家一定不会多搜索引擎感到陌生,搜索引擎是互联网发展的最直接的产物,它可以帮助我们从海量的互联网资料中找到我们查询的内容,也是我们日常学习.工作和娱乐不可或缺的查询工具.之前本人也是经常使用Googl ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
面向服务体系架构(SOA)和数据仓库(DW)的思考 基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse, ...
- 关于Oracle数据库故障诊断基础架构
本节包含有关Oracle数据库故障诊断基础结构的背景信息.它包含以下主题: 故障诊断基础架构概述 关于事件和问题 故障诊断基础设施组件 自动诊断信息库的结构,内容和位置 故障诊断基础架构概述 故障诊断 ...
- 朱晔的互联网架构实践心得S2E7:漫谈平台架构的工作(基础架构、基础服务、基础平台、基础中间件等等)
前言 程序开发毕竟还不是搬砖这种无脑体力劳动,需要事先有标准,有架构,有设计,绝对不是新公司今天创立,明天就可以开始编码的.其实很多公司在起步的时候没有财力和资源建设独立的基础架构或平台架构部门,甚至 ...
- hadoop之yarn详解(基础架构篇)
本文主要从yarn的基础架构和yarn的作业执行流程进行阐述 一.yarn的概述 Apache Yarn(Yet Another Resource Negotiator的缩写)是hadoop集群资源管 ...
- ITIL《信息技术基础架构库》
一 概述 1. ITIL 自上世纪70年代开始,个人计算机以及计算机网络开始在欧美发达国家普及.随着时间的推移,信息系统的规模越来越大,人们对信息系统的依赖也越来越强.特别是到了80年代,互联网开始普 ...
- AWS EC2+Docker+JMeter构建分布式负载测试基础架构
目录 概述及范围 前提条件 Part 1: Local setup-本地配置 Part 2: Cloud端基础架构--Infrastructure 总结: 原文链接 @ 概述及范围 本文介绍有关如何使 ...
- 深入浅出node.js游戏服务器开发1——基础架构与框架介绍
2013年04月19日 14:09:37 MJiao 阅读数:4614 深入浅出node.js游戏服务器开发1——基础架构与框架介绍 游戏服务器概述 没开发过游戏的人会觉得游戏服务器是很神秘的 ...
随机推荐
- odoo13之文件预览widget/模块
本文示例代码可查看github仓库:odoo13_file_preview 文件预览效果图展示 效果描述: 1.当点击图片或者文件时展开图片. 2.当点击关闭按钮时关闭图片预览. 3.当点击下载按钮时 ...
- 004_自己尝试go语言中的方法
go语言可以给任意类型定义方法,我在学习过程中,一开始一头雾水,但是随着理解的深入,现在也大概知道了什么叫做方法 之前的一些例子其实讲的并不是特别生动,下面我用一个生动的例子演示一下 首先提出需求.我 ...
- CentOS yum 安装nginx
当使用以下命令安装Nginx时,发现无法安装成功 yum install -y nginx 需要做一点处理. 安装Nginx源 执行以下命令: rpm -ivh http://nginx.org/pa ...
- The Involution Principle
目录 Catalan Paths Vandermonde Determinant The Pfaffian Catalan Paths 从 \((0,0)\) 走到 \((n,n)\), 每次只能向上 ...
- RIPS源码阅读记录(二)
Author: tr1ple 这部分主要分析scanner.php的逻辑,在token流重构完成后,此时ini_get是否包含auto_prepend_file或者auto_append_file 取 ...
- 【小白学AI】XGBoost 推导详解与牛顿法
文章转自公众号[机器学习炼丹术],关注回复"炼丹"即可获得海量免费学习资料哦! 目录 1 作者前言 2 树模型概述 3 XGB vs GBDT 3.1 区别1:自带正则项 3.2 ...
- 2020-06-11:Redis支持的数据类型?
福哥答案2020-06-11: 福哥口诀法:字哈列集有(string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合))位超地流(位图bitma ...
- Vue 图片压缩上传: element-ui + lrz
步骤 安装依赖包 npm install --save lrz 在main.js里引入 import lrz from 'lrz' 封装 compress函数 封装上传组件 upload-image ...
- vue scss 样式穿透
使用2个style的方式不够优雅,可以使用下面方式做样式穿透 .normal-field /deep/ .el-form-item { margin-bottom: 0px; } .normal-fi ...
- 图的DFS和BFS(邻接表)
用C++实现图的DFS和BFS(邻接表) 概述 图的储存方式有邻接矩阵和邻接表储存两种.由于邻接表的实现需要用到抽象数据结构里的链表,故稍微麻烦一些.C++自带的STL可以方便的实现List,使算 ...