centos7搭建kafka集群
一、安装jdk
1.下载jdk压缩包并移动到/usr/local目录
mv jdk-8u162-linux-x64.tar.gz /usr/local
2.解压
tar -zxvf jdk-8u162-linux-x64.tar.gz
配置JDK环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_162
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin更新配置
source /etc/profile
4.检查安装完成

二、安装zk
1.下载zookeeper压缩包并移动到/usr/local目录
mv zookeeper-3.4.12.tar.gz /usr/local/
2.解压zookeeper并改名
tar -zxvf zookeeper-3.4.12.tar.gz
mv zookeeper-3.4.12 zookeeper
3.创建zookeeper的数据和日志存放路径
cd zookeeper
mkdir data
mkdir log
4.添加zk的myid
在data目录下新建文件myid,内容为zk的唯一id,搭建zk集群时会用到server.${myid}

5.修改zookeeper配置文件修改配置文件
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
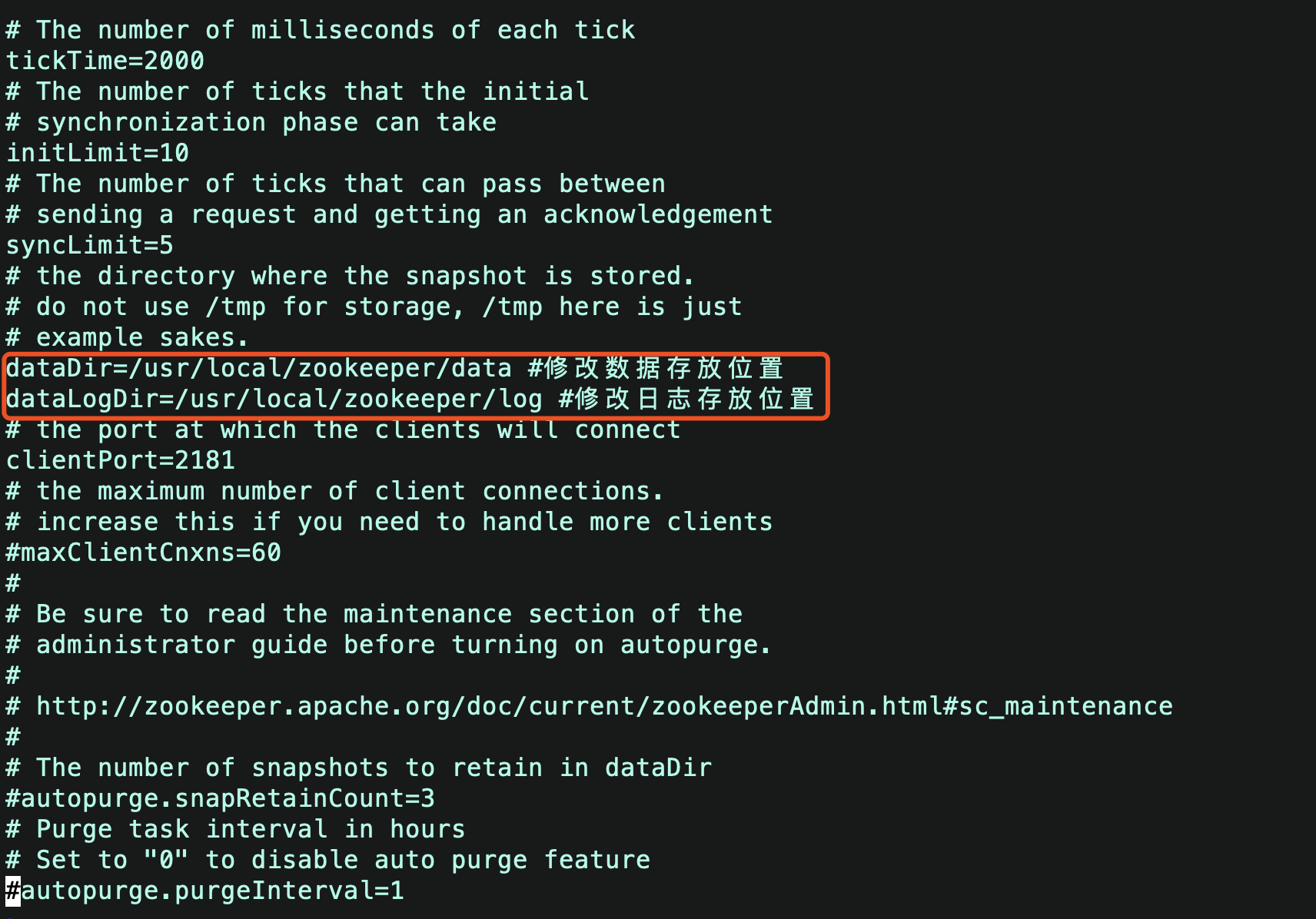
修改如下内容:
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/log
6.添加集群信息
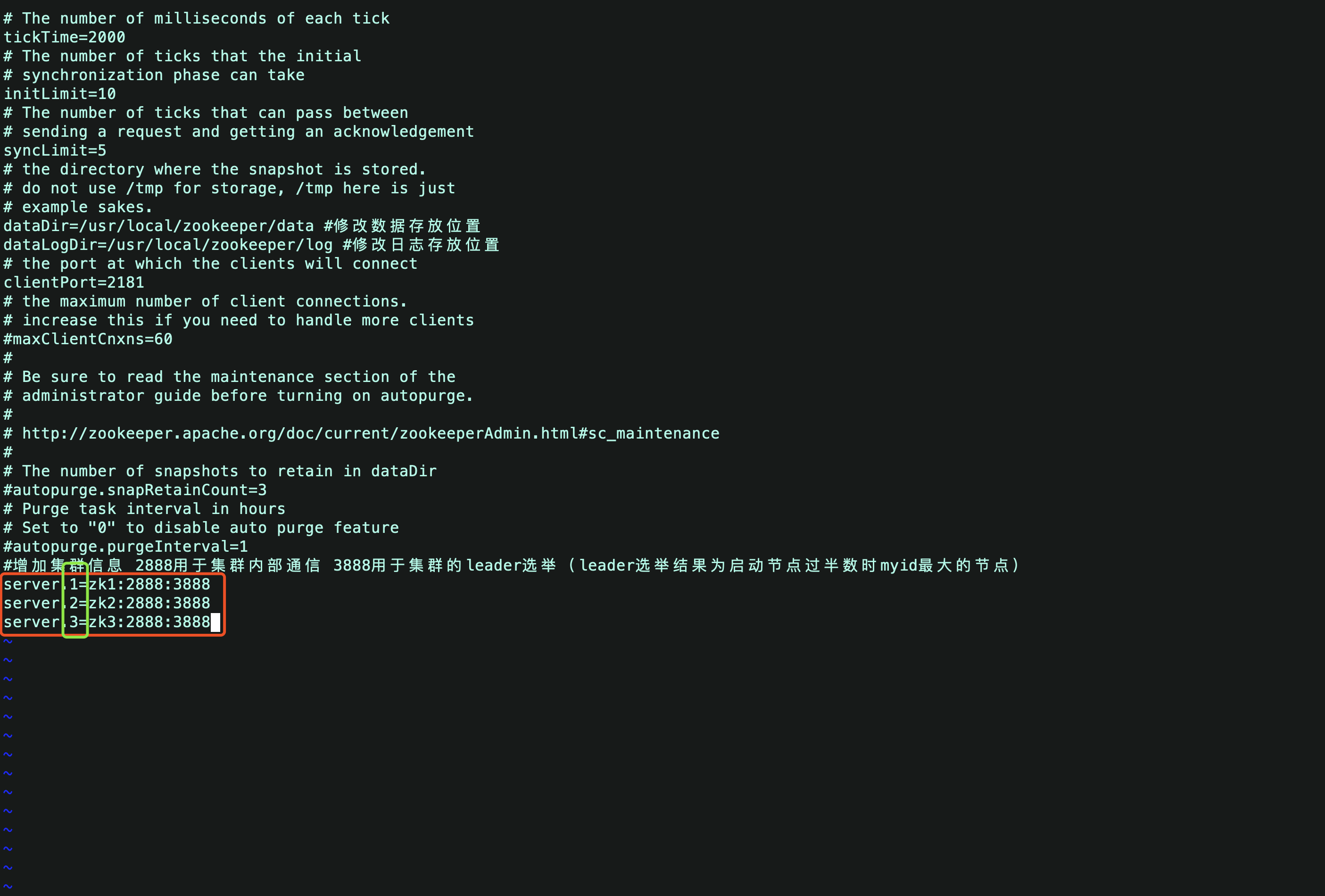
在zoo.cfg中添加如下内容:增加集群信息 2888用于集群内部通信 3888用于集群的leader选举(leader选举结果为启动节点过半数时myid最大的节点)
server.myid!!!
server.1=zk1:2888:3888
server.2=zk2:2888:3888
server.3=zk3:2888:3888
7.关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
firewall-cmd --state #查看默认防火墙状态(关闭后显示notrunning,开启后显示running)
8.把zk目录添加到环境变量
vi /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
export PATH
9.启动zk
zkServer.sh start

10.查看zk状态
zkServer.sh status

11.在另外两台机器执行以上命令
最终查看集群状态
zk1:

zk2:

zk3:

二、安装kakfa
1.下载kakfa压缩包并移动到/usr/local目录
tar -zxvf kafka_2.13-2.4.0.tgz
mv kafka_2.13-2.4.0 kafka
2.创建kafka数据存储目录
cd kafka
mkdir data
3.修改配置文件
cd config
vi server.properties
添加如下配置:
broker.id=0
delete.topic.enable=true
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/kafka/data
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
listeners=PLAINTEXT://zk1:9092
4.添加环境变量
vi /etc/profile
添加
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
使配置生效
source /etc/profile
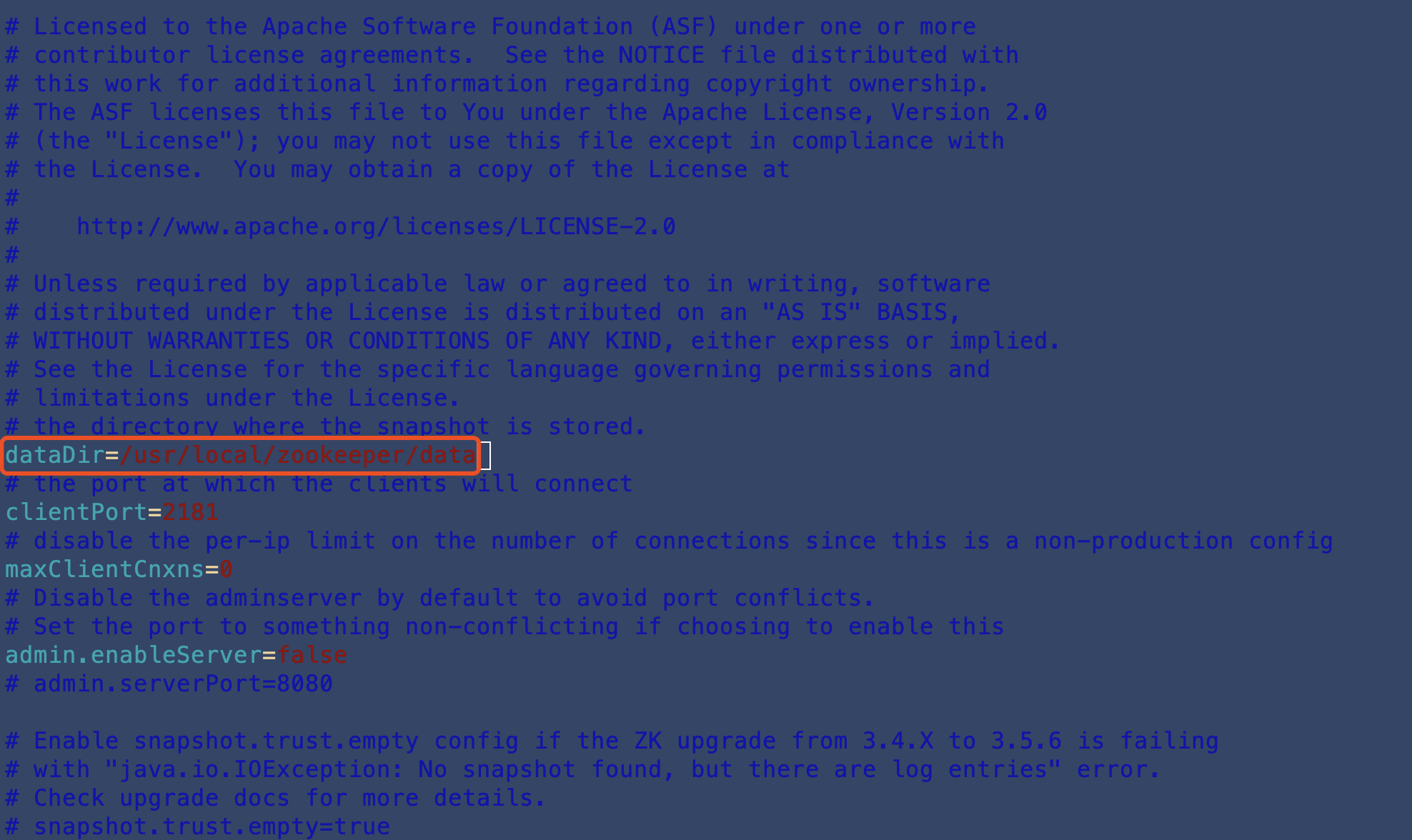
5.修改zk路径为zk存储data的路径
vi zookeeper.properties
/usr/local/zookeeper/data
6.在其余两台机器执行上述命令(broker.id 不得重复)
7.启动broker
三台机器的kafka目录下执行
bin/kafka-server-start.sh -daemon config/server.properties
四、kafka启动完成检查
1.jps

zk和kafka集群已经启动成功
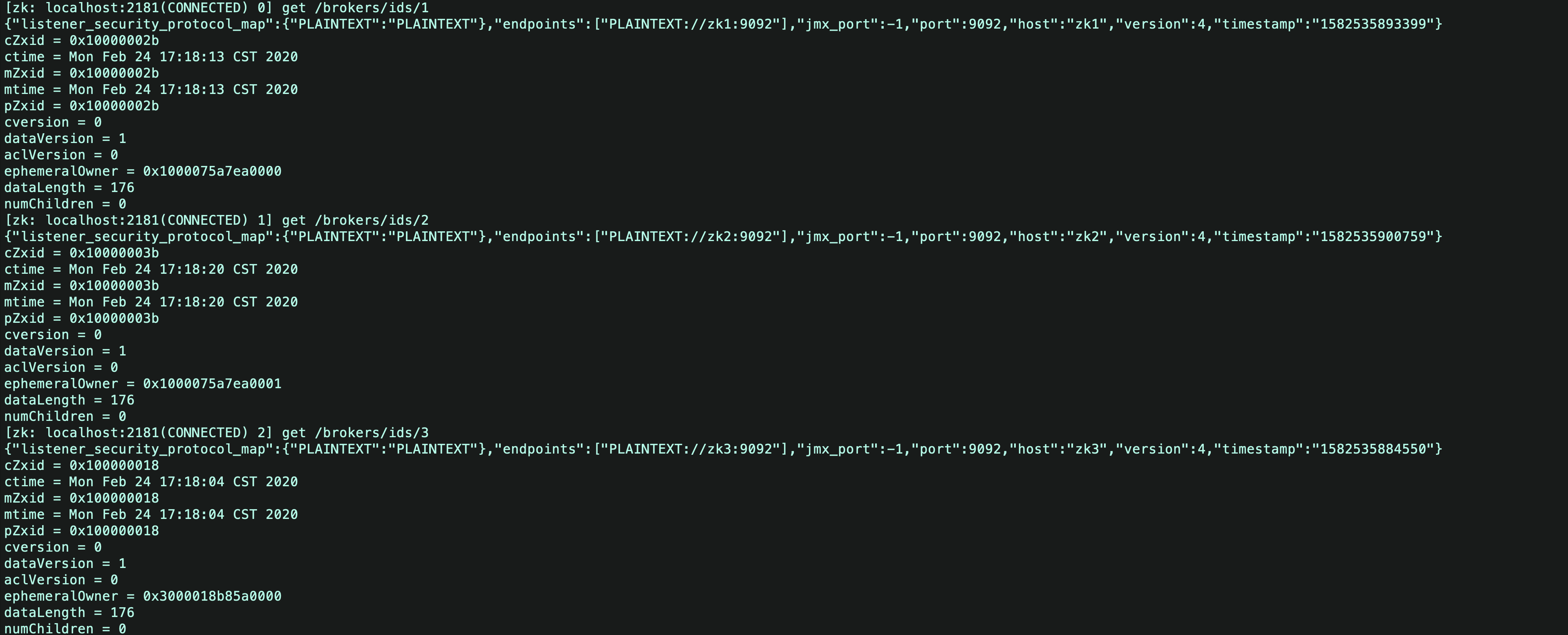
2.登录zk验证
cd /usr/local/zookeeper/bin
zkCli.sh
get /brokers/ids/${broker.id}
可以看到三个kafka的broker均已经注册到zk中
centos7搭建kafka集群的更多相关文章
- centos7搭建kafka集群-第二篇
好了,本篇开始部署kafka集群 Zookeeper集群搭建 注:Kafka集群是把状态保存在Zookeeper中的,首先要搭建Zookeeper集群(也可以用kafka自带的ZK,但不推荐) 1.软 ...
- centos7搭建kafka集群-第一篇
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- Kafka学习之(六)搭建kafka集群
想要搭建kafka集群,必须具备zookeeper集群,关于zookeeper集群的搭建,在Kafka学习之(五)搭建kafka集群之Zookeeper集群搭建博客有说明.需要具备两台以上装有zook ...
- 什么是kafka以及如何搭建kafka集群?
一.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. Kafka场景比喻 接下来我大概比喻下Kafka的使用场景 消息中间件:生产者和消费者 妈妈:生产 ...
- 利用新版本自带的Zookeeper搭建kafka集群
安装简要说明新版本的kafka自带有zookeeper,其实自带的zookeeper完全够用,本篇文章以记录使用自带zookeeper搭建kafka集群.1.关于kafka下载kafka下载页面:ht ...
- Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装
Centos7.4 kafka集群安装与kafka-eagle1.3.9的安装 集群规划: hostname Zookeeper Kafka kafka-eagle kafka01 √ √ √ kaf ...
- docker-compose 搭建kafka集群
docker-compose搭建kafka集群 下载镜像 1.wurstmeister/zookeeper 2.wurstmeister/kafka 3.sheepkiller/kafka-manag ...
- 搭建Kafka集群(3-broker)
Apache Kafka是一个分布式消息发布订阅系统,而Kafka环境往往是在集群中配置的.本篇就对配置3个broker的Kafka集群进行介绍. Zookeeper集群 Kafka本身提供了启动了z ...
随机推荐
- centos 访问win共享
yum install samba 安装samba (其实我们只用到samba里面的winbind以便我们能够用windows机器的名称找到该机器的网络地址,在下面叙述的过程会用到.而且也要确定在 w ...
- mybatis注解中写SQL语句
参考: https://blog.csdn.net/gebitan505/article/details/54929287/https://blog.csdn.net/KingBoyWorld/art ...
- c++ char* 与LPCTSTR相互转化
] = "wo shi ni baba"; , , ch, -, NULL, ); wchar_t *wide = new wchar_t[num]; MultiByteToWid ...
- Android 如何从系统图库中选择图片
转:http://blog.csdn.net/tody_guo/article/details/7560270 这几天我都在做Android的App,同时学习它的API,我将分享一些我学到的东西,比如 ...
- JS链接转换为二维码
这里用到一个JQ插件 qrcode.js 下载地址https://github.com/jeromeetienne/jquery-qrcode 先引入 <script src="j ...
- bootloader 详细介绍
Bootloader 对于计算机系统来说,从开机上电到操作系统启动需要一个引导过程.嵌入式Linux系统同样离不开引导程序,这个引导程序就叫作Bootloader. 6.1.1 Bootloader ...
- netcore webCache缓存
NetCoreCacheService.dll public IActionResult Index() { //存入字符串 MemoryCacheService.SetChacheValue(&qu ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 辅助类:"text-primary" 类的文本样式
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 无需重新编译安装PHP扩展的方法
转自:https://www.jianshu.com/p/ae3c17b0f126 PHP扩展模块通常有两种: PHP官方扩展.如果php通过源码安装(php7),安装的时候未开启,而后来需要开启某个 ...
- mysql 安装完以后没有mysql服务
用管理员身份打开命令控制台(cmd),然后将mysql的安装文件的路径打开(bin文件的路径),然后再路径下打上mysqld.exe -install, 会出现提示 Service successf ...