爬取拉勾网python工程师的岗位信息并生成csv文件
转载自:https://www.cnblogs.com/sui776265233/p/11146969.html
代码写得很好,但是目前只看得懂前一部分
一、爬取和分析相关依赖包
- Python版本: Python3.6
- requests: 下载网页
- math: 向上取整
- time: 暂停进程
- pandas:数据分析并保存为csv文件
二、分析网页结构
在拉勾网搜索'python工程师',然后右键点击检查或者F12,,使用检查功能查看网页源代码,当我们点击下一页观察浏览器的搜索栏的url并没有改变,这是因为拉勾网做了反爬虫机制, 职位信息并不在源代码里,而是保存在JSON的文件里,因此我们直接下载JSON,并使用字典方法直接读取数据.即可拿到我们想要的python职位相关的信息
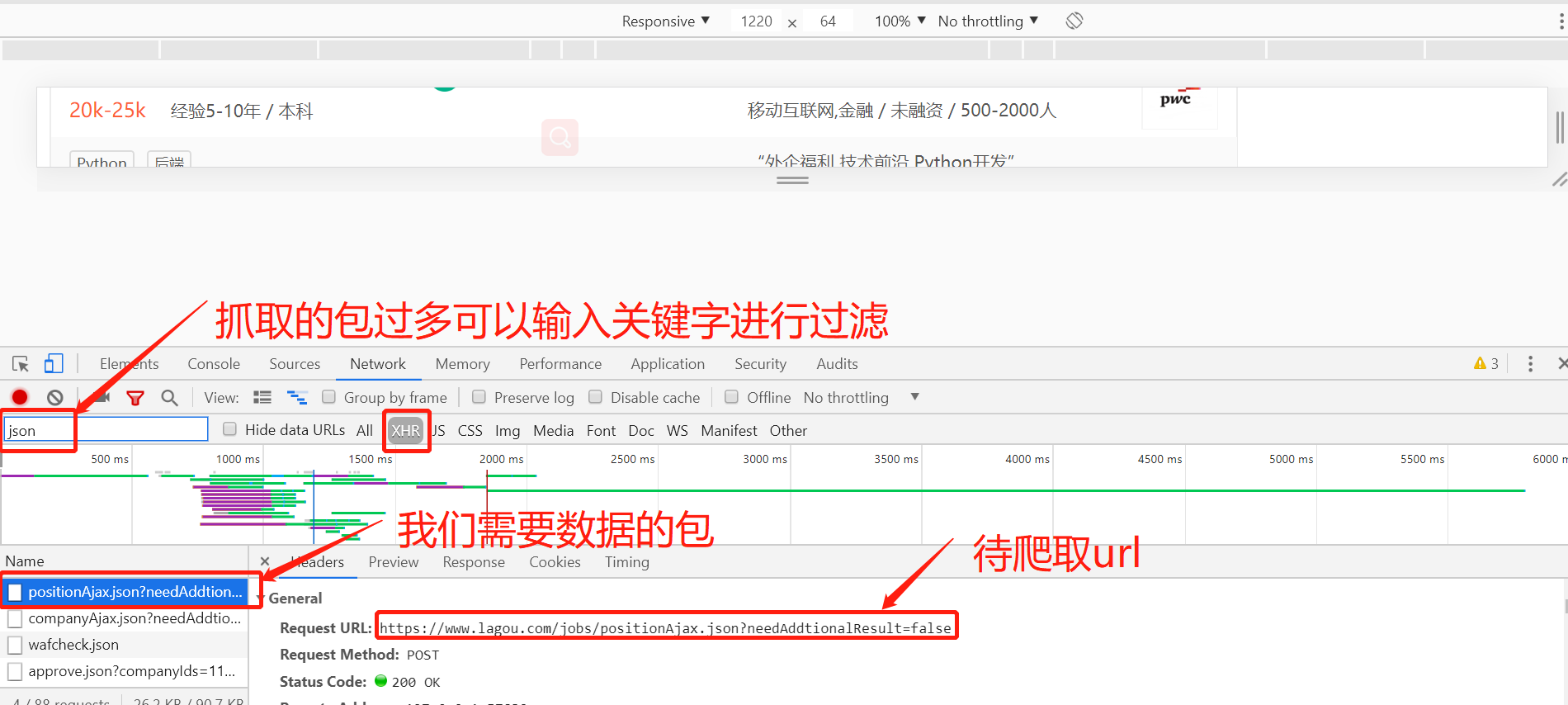
待爬取的python工程师职位信息如下:
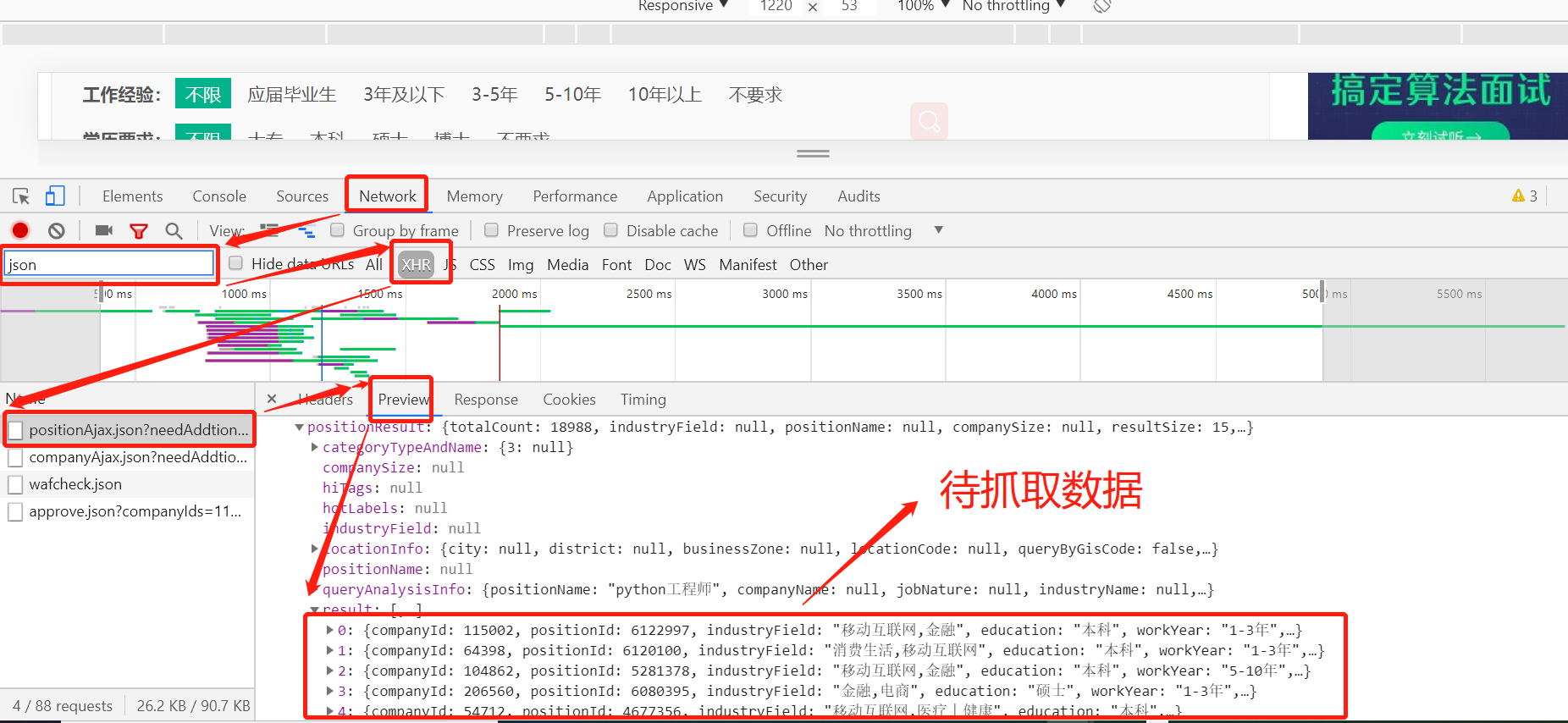
为了能爬到我们想要的数据,我们要用程序来模拟浏览器来查看网页,所以我们在爬取的过程中会加上头信息,头信息也是我们通过分析网页获取到的,通过网页分析我们知道该请求的头信息,以及请求的信息和请求的方式是POST请求,这样我们就可以该url请求拿到我们想的数据做进一步处理
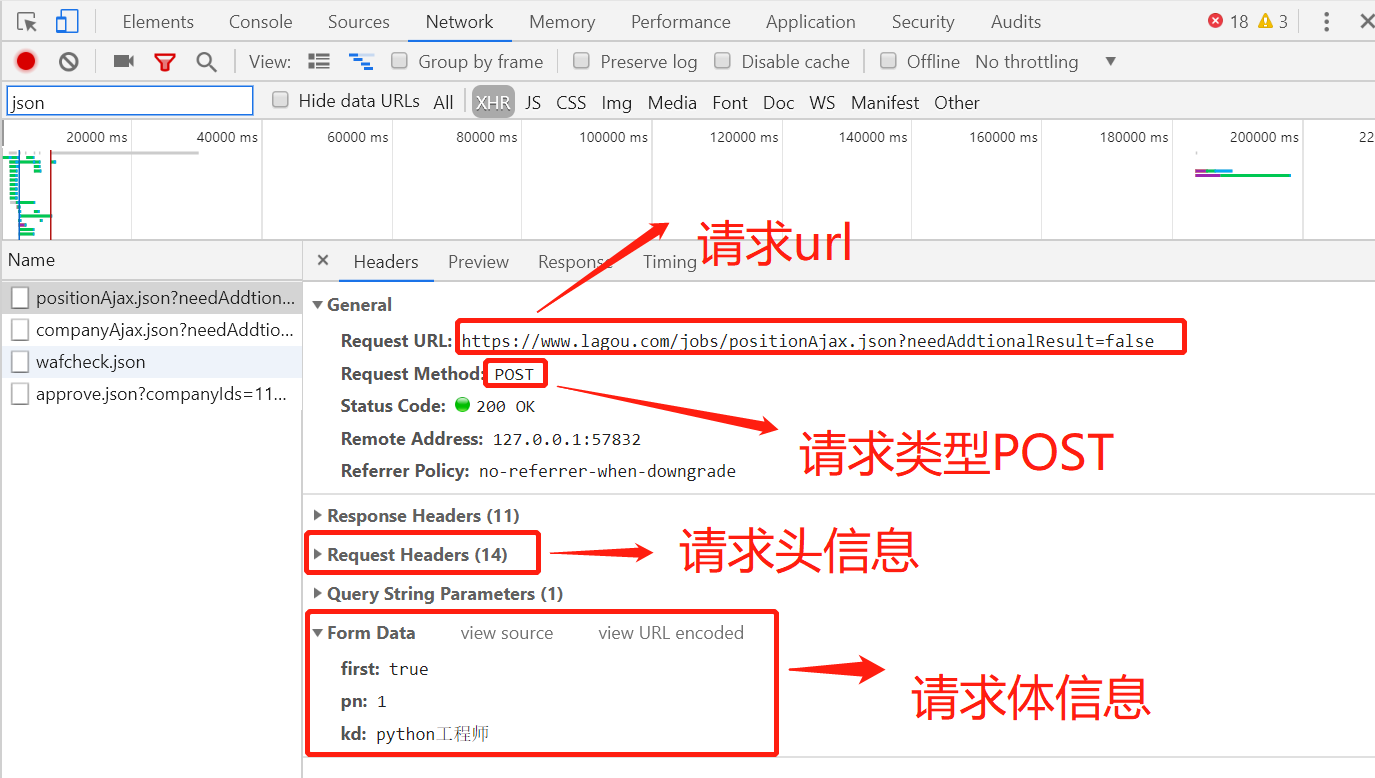
爬取网页信息代码如下:
import requests
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
def get_json(url, num):
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'first': 'true',
'pn': num,
'kd': 'python工程师'}
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
print(get_json(url, 1))
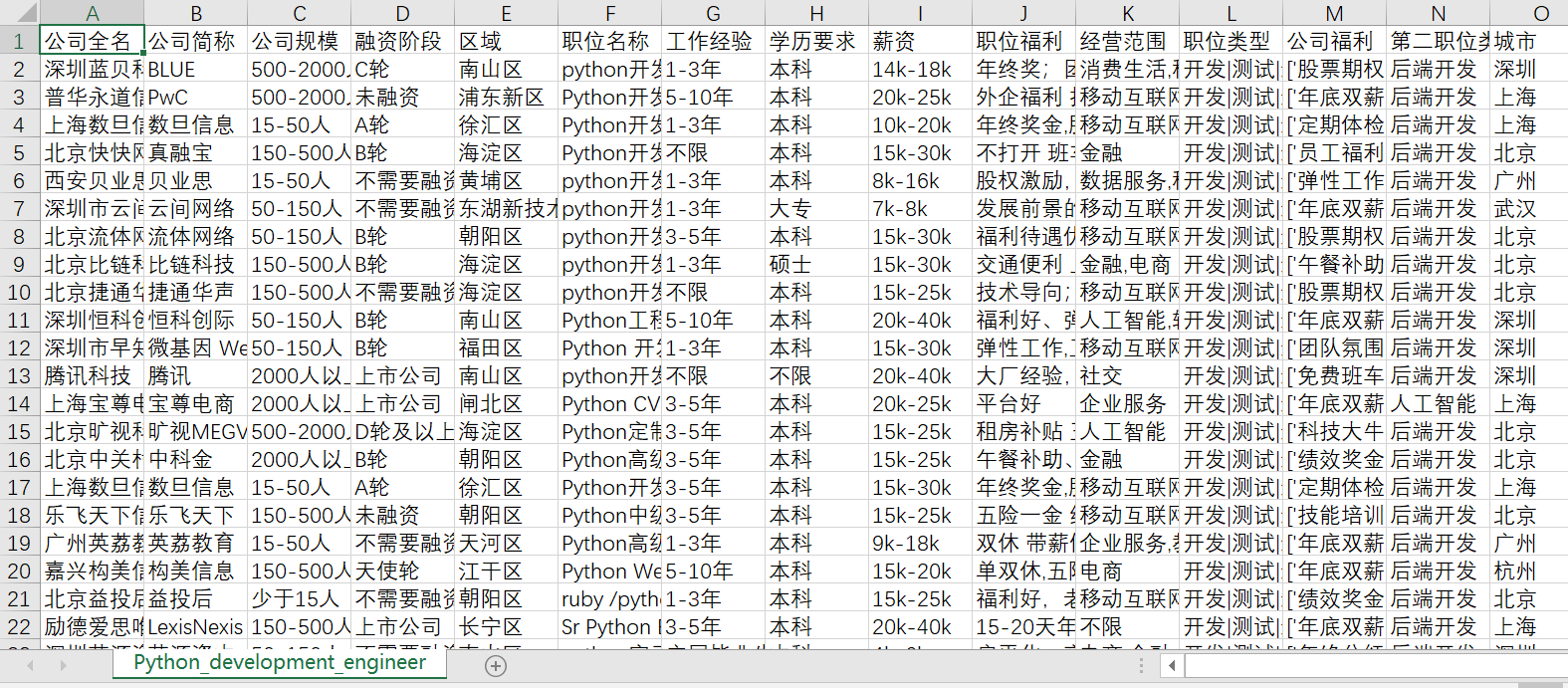
通过搜索我们知道每页显示15个职位,最多显示30页,通过分析网页源代码知道,可以通过JSON里读取总职位数,通过总的职位数和每页能显示的职位数.我们可以计算出总共有多少页,然后使用循环按页爬取, 最后将职位信息汇总, 写入到CSV格式的文件中.
程序运行结果如图:

完整代码如下:
import requests
import math
import time
import pandas as pd
def get_json(url, num):
"""
从指定的url中通过requests请求携带请求头和请求体获取网页中的信息,
:return:
"""
url1 = 'https://www.lagou.com/jobs/list_python%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'first': 'true',
'pn': num,
'kd': 'python工程师'}
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
def get_page_num(count):
"""
计算要抓取的页数,通过在拉勾网输入关键字信息,可以发现最多显示30页信息,每页最多显示15个职位信息
:return:
"""
page_num = math.ceil(count / 15)
if page_num > 30:
return 30
else:
return page_num
def get_page_info(jobs_list):
"""
获取职位
:param jobs_list:
:return:
"""
page_info_list = []
for i in jobs_list: # 循环每一页所有职位信息
job_info = []
job_info.append(i['companyFullName'])
job_info.append(i['companyShortName'])
job_info.append(i['companySize'])
job_info.append(i['financeStage'])
job_info.append(i['district'])
job_info.append(i['positionName'])
job_info.append(i['workYear'])
job_info.append(i['education'])
job_info.append(i['salary'])
job_info.append(i['positionAdvantage'])
job_info.append(i['industryField'])
job_info.append(i['firstType'])
job_info.append(i['companyLabelList'])
job_info.append(i['secondType'])
job_info.append(i['city'])
page_info_list.append(job_info)
return page_info_list
def main():
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
num = get_page_num(total_page_count)
total_info = []
time.sleep(10)
print("python开发相关职位总数:{},总页数为:{}".format(total_page_count, num))
for num in range(1, num + 1):
# 获取每一页的职位相关的信息
page_data = get_json(url, num) # 获取响应json
jobs_list = page_data['content']['positionResult']['result'] # 获取每页的所有python相关的职位信息
page_info = get_page_info(jobs_list)
print("每一页python相关的职位信息:%s" % page_info, '\n\n')
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
time.sleep(20)
# 将总数据转化为data frame再输出,然后在写入到csv各式的文件中
df = pd.DataFrame(data=total_info,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '薪资', '职位福利', '经营范围',
'职位类型', '公司福利', '第二职位类型', '城市'])
df.to_csv('Python_development_engineer.csv', index=False)
print('python相关职位信息已保存')
if __name__ == '__main__':
main()
爬取拉勾网python工程师的岗位信息并生成csv文件的更多相关文章
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- 爬取某网站景区列表并保存为csv文件
网址:http://www.halehuo.com/jingqu.html 经过查看可以发现,该景区页面没有分页,不停的往下拉,页面会进行刷新显示后面的景区信息 通过使用浏览器调试器,发现该网站使用的 ...
- 04爬取拉勾网Python岗位分析报告
# 导入需要的包import requestsimport time,randomfrom openpyxl import Workbookimport pymysql.cursors#@ 连接数据库 ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- Python爬虫实战(一) 使用urllib库爬取拉勾网数据
本笔记写于2020年2月4日.Python版本为3.7.4,编辑器是VS code 主要参考资料有: B站视频av44518113 Python官方文档 PS:如果笔记中有任何错误,欢迎在评论中指出, ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
- 兴奋与沮丧并存spider爬取拉勾网
兴奋的开发除了爬取拉勾网的爬虫信息,可是当调试都成功了的那一刻,我被拉钩封IP了. 下面是spider的主要内容 import reimport scrapy from bs4 import Beau ...
随机推荐
- [暑假集训Day3T1]小木棍
经典搜索题. 考虑以下9种优化 1)按木棍长度排序,使得较大长度的木棍被较早的选出. 2)只找能够整除的木棍长度,因为不能被sum整除一定不会出整数根,自然也就不是最优解. 3)枚举木棍长度时只需从最 ...
- 修改DbVisualizer的默认快捷键 .
修改SQL提示的步骤如下:1, 编辑dbvis.jar包下的dbvis-actions.xml文件(解压或直接修改)2, 找到以下的代码<actionidref="show-auto- ...
- ASE Alpha Sprint - backend scrum 4
本次scrum于2019.11.8再sky garden进行,持续10分钟. 参与人: Zhikai Chen, Jia Ning, Hao Wang 请假: Xin Kang, Lihao Ran, ...
- c#同时验证手机号和座机号正则
string strPatern2= @"(^(\d{3,4}-)?\d{6,8}$)"; string strPatern = @"(^1[3-8]\d{9}$|^\d ...
- shell分析nginx access log日志
统计访问最多的ip1. tail -n 10000 xxaccess_log | cut -d " " -f 1 |sort|uniq -c|sort -rn|head -10 | ...
- vue 字符串长度控制显示的字数超出显示省略号
1. html <p class="index__Feature-list-itemlist-title newline"> {{item.name| ellipsis ...
- Python3.5-20190529-自动登录百度
- Java Web 之HttpServletRequest对象初识
通过request对象获得请求行 获得客户端请求方式:String getMethod(); 获得请求的资源: String getRequestURL(); String getQueryStrin ...
- 25.Java锁的深度化
Java锁的深度化 悲观锁.乐观锁.排他锁 场景 当多个请求同时操作数据库时,首先将订单状态改为已支付,在金额加上200,在同时并发场景查询条件下,会造成重复通知. SQL: Update 悲观锁与乐 ...
- Eclipse中 Run as --->Maven build 命令详解
Maven Build Goals: clean 清除编译,compile 编译,test 编译并测试,install 打包并发送到本地仓库,package 只是打成jar包,并不会发送到本地 ...