es之分词器和分析器
Elasticsearch这种全文搜索引擎,会用某种算法对建立的文档进行分析,从文档中提取出有效信息(Token)
对于es来说,有内置的分析器(Analyzer)和分词器(Tokenizer)
1:分析器
ES内置分析器
| standard | 分析器划分文本是通过词语来界定的,由Unicode文本分割算法定义。它删除大多数标点符号,将词语转换为小写(就是按照空格进行分词) |
|---|---|
| simple | 分析器每当遇到不是字母的字符时,将文本分割为词语。它将所有词语转换为小写。 |
| keyword | 可以接受任何给定的文本,并输出与单个词语相同的文本 |
| pattern | 分析器使用正则表达式将文本拆分为词语,它支持小写和停止字 |
| language | 语言分析器 |
| whitespace | (空白)分析器每当遇到任何空白字符时,都将文本划分为词语。它不会将词语转换为小写 |
| custom | 自定义分析器 |
测试simple Analyzer:
POST _analyze
{
"analyzer": "simple",
"text": "today is 2018year 5month 1day."
}
custom(自定义)分析器接受以下的参数:
tokenizer |
内置或定制的标记器(也就是需要使用哪种分析器)。<br/>(需要) |
|---|---|
char_filter |
内置或自定义字符过滤器的可选阵列。 |
filter |
可选的内置或定制token过滤器阵列。 |
position_increment_gap |
在索引文本值数组时,Elasticsearch会在一个词的最后一个位置和下一个词的第一个位置之间插入“间隙”,以确保短语查询与不同数组元素的两个术语不匹配。 默认为100.有关更多信息 |
测试:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
做一下普通查询:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
然后删除索引,重新添加:
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"names": {
"type": "text",
"position_increment_gap": 0
}
}
}
}
}
然后倒入数据:
PUT /my_index/groups/1
{
"names": [ "John Abraham", "Lincoln Smith"]
}
在做查询操作:
GET /my_index/groups/_search
{
"query": {
"match_phrase": {
"names": "Abraham Lincoln"
}
}
}
2:更新分析器
1:要先关闭索引
2:添加分析器
3:打开索引
1、 关闭索引
POST my_index/_close
2、 添加分析器
PUT my_index/_settings
{
"analysis": {
"analyzer": {
"my_custom_analyzer3": {
"type": "custom",
"tokenizer": "standard",
"char_filter": [
"html_strip"
],
"filter": [
"lowercase",
"asciifolding"
]
}
}
}
}
3、打开索引
POST my_index/_open
4、测试:
POST my_index/_analyze
{
"analyzer": "my_custom_analyzer",
"text": "Is this <b>网页 </b>?"
}
3:分词器
Es中也支持非常多的分词器
| Standard | 默认的分词器根据 Unicode 文本分割算法,以单词边界分割文本。它删除大多数标点符号。<br/>它是大多数语言的最佳选择 |
|---|---|
| Letter | 遇到非字母时分割文本 |
| Lowercase | 类似 letter ,遇到非字母时分割文本,同时会将所有分割后的词元转为小写 |
| Whitespace | 遇到空白字符时分割位文本 |
Standard例子:
POST _analyze
{
"tokenizer": "standard",
"text": "this is standard tokenizer!!!!."
}
Letter例子:
POST _analyze
{
"tokenizer": "letter",
"text": "today is 2018year-05month"
}
Whitespace例子:
POST _analyze
{
"tokenizer": "whitespace",
"text": "this is t es t."
}
4:更新分词器
我们在创建索引之后可以添加分词器,比如想要按照空格的方式进行分词
【注意】
添加分词器步骤:
1:要先关闭索引
2:添加分词器
3:打开索引
POST school/_close
PUT school/_settings
{
"analysis" :
{
"analyzer" :
{
"content" : {"type" : "custom" , "tokenizer" : "whitespace"}
}
}
}
POST school/_open
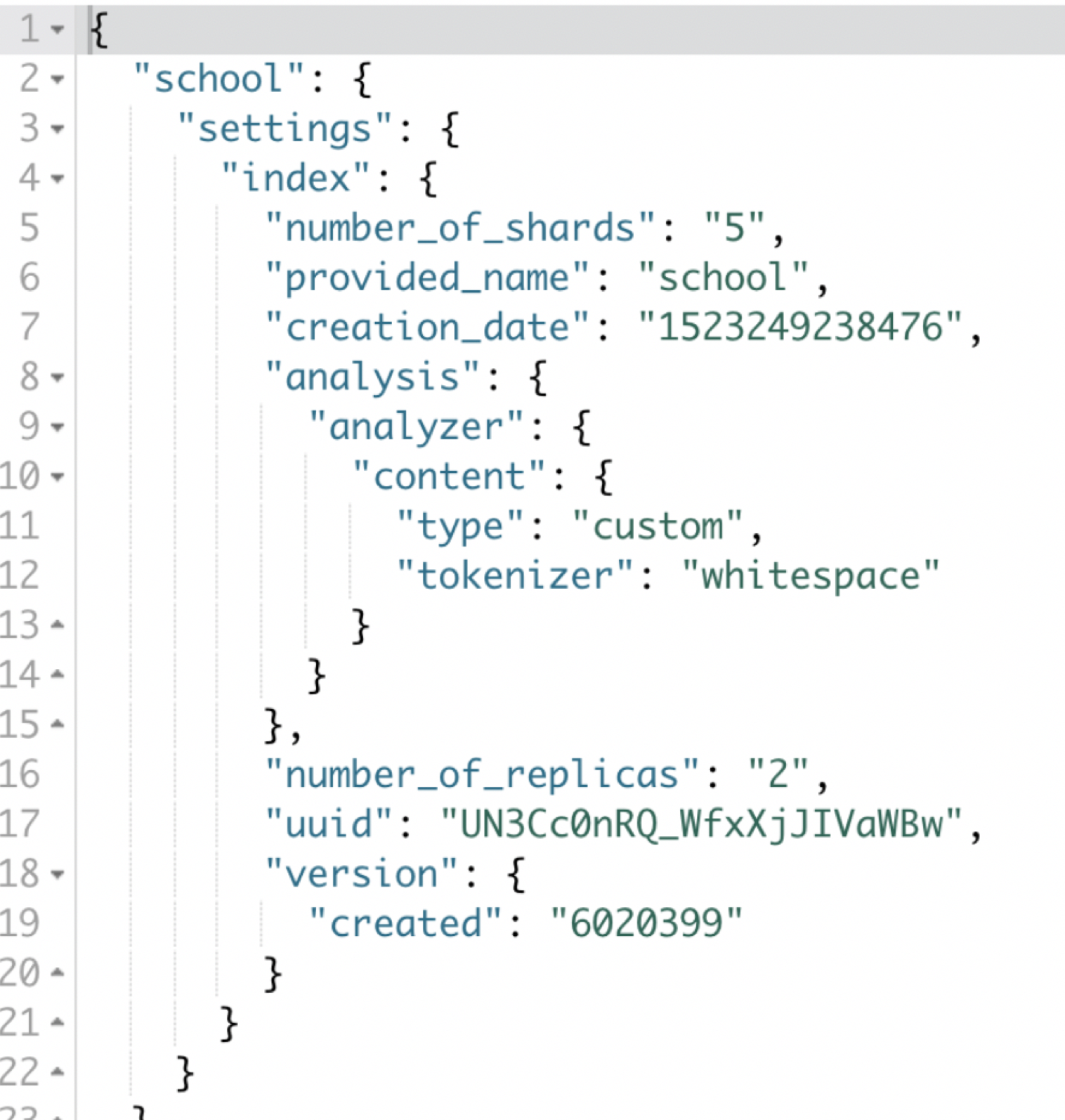
获取索引的配置:
索引中包含了非常多的配置参数,我们可以通过命令进行查询
GET school/_settings
es之分词器和分析器的更多相关文章
- Elasticsearch(ES)分词器的那些事儿
1. 概述 分词器是Elasticsearch中很重要的一个组件,用来将一段文本分析成一个一个的词,Elasticsearch再根据这些词去做倒排索引. 今天我们就来聊聊分词器的相关知识. 2. 内置 ...
- es的分词器analyzer
analyzer 分词器使用的两个情形: 1,Index time analysis. 创建或者更新文档时,会对文档进行分词2,Search time analysis. 查询时,对查询语句 ...
- ES中文分词器安装以及自定义配置
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. ik分词 ...
- ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询. 然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只 ...
- Elasticsearch(10) --- 内置分词器、中文分词器
Elasticsearch(10) --- 内置分词器.中文分词器 这篇博客主要讲:分词器概念.ES内置分词器.ES中文分词器. 一.分词器概念 1.Analysis 和 Analyzer Analy ...
- ElasticSearch最全分词器比较及使用方法
介绍:ElasticSearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elasticsearch 是用 Java 开 ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- ElasticSearch中文分词器-IK分词器的使用
IK分词器的使用 首先我们通过Postman发送GET请求查询分词效果 GET http://localhost:9200/_analyze { "text":"农业银行 ...
- Elasticsearch系列---倒排索引原理与分词器
概要 本篇主要讲解倒排索引的基本原理以及ES常用的几种分词器介绍. 倒排索引的建立过程 倒排索引是搜索引擎中常见的索引方法,用来存储在全文搜索下某个单词在一个文档中存储位置的映射.通过倒排索引,我们输 ...
随机推荐
- 使用logstash收集java、nginx、系统等常见日志
目录 1.使用codec的multiline插件收集java日志... 1 2.收集nginx日志... 2 3.收集系统syslog日志... 3 4.使用fliter的grok模块收集mysql日 ...
- 【烦人的字符集】linux字符集问题,中文乱码
[1]快速修改命令 [2]locale 查看现在服务器的字符 [root@Master ~]# localeLANG=en_US.UTF-8LC_CTYPE="zh_CN.UTF-8&quo ...
- Spring框架学习总结
一.Spring概述 1.什么是Spring? Spring是一个优秀轻量级的框架,是Java中使用最多的框架,Spring框架具有轻量.控制反转.面向切面.容器.框架.MVC的特点. 2.Sprin ...
- 索引之----mysql联合索引
重要概念: 1.对于mysql来说,一条sql中,一个表无论其蕴含的索引有多少,但是有且只用一条. 2.对于多列索引来说(a,b,c)其相当于3个索引(a),(a,b),(a,b,c)3个索引,又由于 ...
- STM32 晶振 系统时钟8MHZ和72Mhz的原因
首先问题描述: 1.自己画的板子和淘宝买的最小系统板 系统时钟不一致,自己画的是8Mhz,HSE失败:最小系统板72Mhz 2.最小系统板在程序1运行仿真的时候,查看peripherals->P ...
- MySQL服务意外停止
先说一下,发现MySQL服务停了,启动就又好了,但是好奇服务意外停止的原因,所以看了一下MySQL的错误日志. 但是到底是哪个错误导致MySQL服务意外终止,还没有定论,故有了此篇文章,还望知道原因的 ...
- [BZOJ 4025]二分图(线段树分治+带边权并查集)
[BZOJ 4025]二分图(线段树分治+带边权并查集) 题面 给出一个n个点m条边的图,每条边会在时间s到t出现,问每个时间的图是否为一个二分图 \(n,m,\max(t_i) \leq 10^5\ ...
- python中输入某年某月某日,判断这一天是这一年的第几天?
输入某年某月某日,判断这一天是这一年的第几天?程序分析 特殊情况,闰年时需考虑二月多加一天: 直接上代码 #定义一个函数,判断是否为闰年 def leapyear(y): return (y % 40 ...
- vscode 将本地项目上传到码云
**************************************************************************************************** ...
- UITableViewCell选中后子View背景色被Clear
在TableView中,当cell 处于Hightlighted(高亮)或者Selected(选中)状态下,Cell上的子控件的背景颜色会被 Clear. 解决方法:(4种) 1. 直接设置子控件的 ...