hbase实践之协处理器Coprocessor
HBase客户端查询存在的问题
- Scan
用Get/Scan查询数据, - Filter
用Filter查询特定数据
以上情况只适合几千行数据以及不是很多的列的“小数据”。
当表扩展为亿万行及百万列时,在通过网络传递移动大量的数据导致网络拥堵,且客户端需要足够多内存来处理这么大量数据的计算操作,另外,客户端代码也会变的大而复杂。
解决方案
移动计算比移动数据更划算
Coprocessor将运算移动到数据所处的节点。
什么是Coprocessor?
简单来说,Coprocessor是一个框架,这个框架可以让你很容易地在Region Server运行你的业务逻辑代码。
Coprocessor类比
- Triggers and Stored Procedure
- Observer Coprocessor –> RDBMS 中的触发器
- EndPoint Coprocessor –> RDBMS中的存储过程
- MapReduce
MapReduce 和 Coprocessor有一样的操作原则,计算向数据靠拢。
- AOP
类似面向切面编程,Coprocessor就像应用Advice,在传递请求到最终的目的地之前,通过拦截一个请求后运行相同的代码。
Coprocessor分类
Observer Coprocessor
在一个特定的事件发生前或发生后触发。
- 在事件发生前触发的Coprocessor需要重写以pre作为前缀的方法,比如prePut。
- 在事件发生后触发的Coprocessor使用方法以post作为前缀,比如postPut。
Endpoint
是一个远程rpc调用,类似于webservice形式调用,但他不适用xml,而是使用的序列化框架是protobuf(序列化后数据更小).
区别:Observer像是个触发器,到某个条件Region就去执行用户代码,用户从主观来说是无法控制的;EndPoint就是远程调用,用户可以在客户端远程调用执行自己的代码。
Observer Coprocessor使用场景与实现
Observer Coprocessor的使用场景如下:
安全性:在执行Get或Put操作前,通过preGet或prePut方法检查是否允许该操作;
引用完整性约束:HBase并不直接支持关系型数据库中的引用完整性约束概念,即通常所说的外键。但是我们可以使用Coprocessor增强这种约束。比如根据业务需要,我们每次写入user表的同时也要向user_daily_attendance表中插入一条相应的记录,此时我们可以实现一个Coprocessor,在prePut方法中添加相应的代码实现这种业务需求。
二级索引:可以使用Coprocessor来维持一个二级索引。这里暂不展开,有时间会单独说明。
Observer在Hbase中主要分为四类,均继承Coprocessor接口:
- RegionObserver 针对于Region的观察者(Region打开、关闭、刷新、合并等工作)
- RegionServerObserver 针对RegionServer的观察者(Region合并、分裂、日志回滚等)
- MasterObserver 针对Master的观察者(表创建、删除、Region移动、拆分等工作)
- WALObserver 针对WAL的观察者(日志写)
EndPoint使用场景与实现
Endpoint允许定义自己的动态RPC协议,用于客户端与region servers通讯。Coprocessor 与region server在相同的进程空间中,因此您可以在region端定义自己的方法(endpoint),将计算放到region端,减少网络开销,常用于提升hbase的功能,如:count,sum等。
工作过程如下图所示过程:
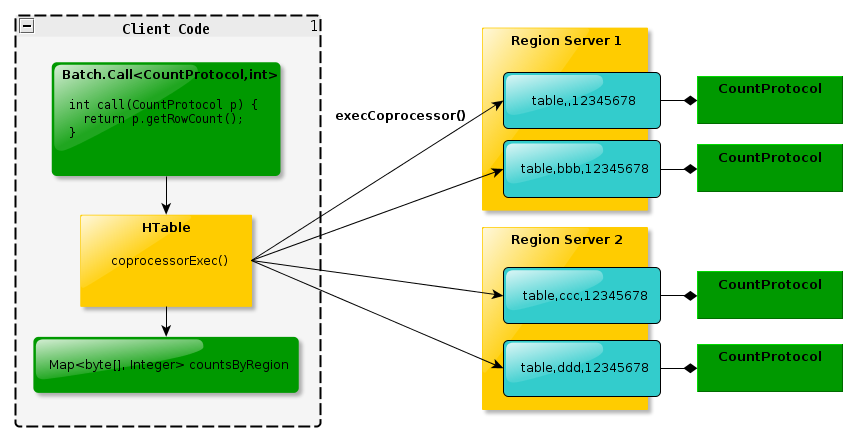
- 不管是通过配置还是表描述加载了EndPoint协处理器
- 在Client执行CoprocessorExec()调用对应的RPC方法
- 在对应的每个region中都会执行该方法后返回结果
- EndPoint实现
- 创建一个“.proto”文件定义服务
- 执行protoc命令,通过“.proto”文件生成Java代码
- 编写一个Coprocessor类,实现Coprocessor和CoprocessorService两个接口,并实现接口中定义的方法:
- 加载Coprocessor
- 编写客户端代码调用Coprocessor
装载Coprocessor
装载Coprocessor分为静态装载和动态装载。
静态装载Coprocessor
- 静态装载过程:
- hbase-site.xml中创建记录
- 将代码放到HBase的类路径下。一个简单的方法是将封装好的jar(包括代码和依赖)放到HBase安装路径下的/lib目录中。
- 重启HBase。
- 静态卸载的步骤如下:
- 移除在hbase-site.xml中的配置。
- 重启HBase。
- 这一步是可选的,将上传到HBase类路径下的jar包移除。
动态装载Coprocessor
动态装载Coprocessor的一个优势就是不需要重启HBase。不过动态装载的Coprocessor只是针对某个表有效。因此,动态装载的Coprocessor又被称为表级Coprocessor。
此外,动态装载Coprocessor是对表的一次schema级别的调整,因此在动态装载Coprocessor时,目标表需要离线。
动态装载Coprocessor有两种方式:通过HBase Shell和通过Java API。
- 通过HBase Shell动态装载
- 使用Java API动态装载和卸载
http://www.zhyea.com/2017/04/13/using-hbase-coprocessor.html#Observer-Coprocessors
达摩克利斯之剑
Coprocessor是HBase的高级功能,本来是只为HBase系统开发人员准备的。因为Coprocessor的代码直接在RegionServer上运行,并直接接触数据,这样就带来了数据破坏的风险,比如“中间人攻击(Man-in-the-MiddleAttack,简称“MITM攻击”,见百度词条)”以及其他类型的恶意入侵。目前还没有任何机制来屏蔽Coprocessor导致的数据破坏。此外,因为没有资源隔离,一个即使不是恶意设计的但表现不佳的Coprocessor也会严重影响集群的性能和稳定性。
其他公司实践
二级索引设计
Phoenix的Salting功能非常有效,但对延迟影响较大,因此若延迟要求较高,那么Salting则并不合适,所以这里在主表与索引表中不使用Salting功能,而是采用reverse将主键列散列。索引中使用Function Index和Function Index减少查询延迟。
参考文献
- Hbase Coprocesor 浅析(一)
- 使用HBase Coprocessor
- Apache HBase Coprocessors
- 使用HBase协处理器---基本概念和regionObserver的简单实现
- HBase 协处理器之 EndPoint 简单示例
- https://zhuanlan.zhihu.com/p/38030330
- 移动计算比移动数据更划算 - 大数据技术源起
- Hbase使用Coprocessor构建二级索引
- 使用solr构建hbase二级索引
- Solr+Hbase多条件查(优劣互补)
hbase实践之协处理器Coprocessor的更多相关文章
- Hadoop生态圈-Hbase的协处理器(coprocessor)应用
Hadoop生态圈-Hbase的协处理器(coprocessor)应用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- HBase 二级索引与Coprocessor协处理器
Coprocessor简介 (1)实现目的 HBase无法轻易建立“二级索引”: 执行求和.计数.排序等操作比较困难,必须通过MapReduce/Spark实现,对于简单的统计或聚合计算时,可能会因为 ...
- Hadoop生态圈-注册并加载协处理器(coprocessor)的三种方式
Hadoop生态圈-注册并加载协处理器(coprocessor)的三种方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 到目前为止,大家已经掌握了如何使用过滤器来减少服务器端通过 ...
- hbase(三)coprocessor
介绍 coprocessor这个单词看起来很神秘,直译为协处理器,其实可以理解成依赖于regionserver进程的辅助处理接口. hbae在0.92版本之后提供了coprocessor接口.目前hb ...
- Sqoop导入HBase,并借助Coprocessor协处理器同步索引到ES
1.环境 Mysql 5.6 Sqoop 1.4.6 Hadoop 2.5.2 HBase 0.98 Elasticsearch 2.3.5 2.安装(略过) 3.HBase Coprocessor实 ...
- HBase实践案例:车联网监控系统
项目背景 本项目为车联网监控系统,系统由车载硬件设备.云服务端构成.车载硬件设备会定时采集车辆的各种状态信息,并通过移动网络上传到服务器端.服务器端接收到硬件设备发送的数据首先需要将数据进行解析,校验 ...
- hbase实践之Rowkey设计之道
笔者从一开始接触hbase就在思考rowkey设计,希望rowkey设计得好,能够支持查询的需求.使用hbase一段时间后,再去总结一些hbase的设计方法,无外乎以下几种: reverse salt ...
- hbase实践之rowkey设计
rowkey设计的重要性 rowkeys是HBase表设计中唯一重要的一点. rowkey设计要求 唯一性 存储特性 按照字典顺序排序存储 查询特性 由于其存储特性导致查询特性: 查询单个记录: 查定 ...
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
随机推荐
- 查看Linux是CentOS还是Ubuntu
lsb_release -a
- 一起来学Spring Cloud | 第八章:消息总线(Spring Cloud Bus)
上一章节,我们讲解了分布式配置中心spring cloud config,我们把配置项存放在git或者本地,当我们修改配置时,需要重新启动服务才能生效.但是在生产上,一个服务部署了多台机器,重新启动比 ...
- 深入浅出JVM(一):运行时数据区域
程序计数器 线程私有 指向了正在执行的虚拟机字节码指令的地址:如果是本地方法,数值为空 没有 OutOfMemoryError 错误的区域 Java虚拟机栈 线程私有: 生命周期与线程相同: 代表着 ...
- 解决Jupyter notebook安装后不自动跳转网页的方法
在安装完Jupyter notebook后,有童鞋说出现了各种不友好的问题,鉴于此情况,个人先随手写出以下三种情况,并给出解决方法: 题外建议:请使用谷歌浏览器为默认浏览器 一.对于弹不出浏览器的解决 ...
- pychram 中 Terminal 中 git log 中文乱码解决办法
添加环境变量 set LESSCHARSET=utf-8 执行以下命令 git config --global core.quotepath false 不成功执行以下命令 git config -- ...
- Python简介及开发环境搭建
Python简介 Python是一门动态解释性的强类型定义的计算机程序设计语言,是一种完全面向对象的语言,由荷兰人"龟叔"-Guido van Rossum于1989年开发,于19 ...
- fastjson框架如何处理boolean?CURRENT_TIMESTAMP使用报错?什么是 ONLINE DDL 及 pt-online-schema-change ? getBytes引起的乱码问题?
一.使用fastjson框架进行序列化时,若莫个参数为Boolean类型,而json里的值是其它类型时,框架如何处理? 1.true, false,正常赋值2.int类型,若为1,则为true,否则为 ...
- web API .net - .net core 对比学习-使用Swagger
根据前两篇的介绍,我们知道.net web api 和 .net core web api在配置方面的不同如下: 1. .net web api的配置是在 App_Stat文件夹里面添加对应的配置类, ...
- JS基础_强制类型转换-Number
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 微信小程序 image组件坑
远程图片 在真机上测试时 image组件只能显示http请求的图片, 对https 与 //xxx.xxx.xx 之类的不能显示. 可显示 'http://img.alicdn.com/i2/8323 ...