python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念
网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
只要浏览器能够做的事情,原则上,爬虫都能够做到。
2.网络爬虫的功能
 图2
图2
网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这些新闻网站进行浏览,比较麻烦。此时可以利用网络爬虫,将这多个新闻网站中的新闻信息爬取下来,集中进行阅读。
有时,我们在浏览网页上的信息的时候,会发现有很多广告。此时同样可以利用爬虫将对应网页上的信息爬取过来,这样就可以自动的过滤掉这些广告,方便对信息的阅读与使用。
有时,我们需要进行营销,那么如何找到目标客户以及目标客户的联系方式是一个关键问题。我们可以手动地在互联网中寻找,但是这样的效率会很低。此时,我们利用爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方式等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行分析,比如分析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时,可以利用爬虫轻松将这些数据采集到,以便进行进一步分析,而这一切爬取的操作,都是自动进行的,我们只需要编写好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现很多强大的功能。总之,爬虫的出现,可以在一定程度上代替手工访问网页,从而,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。
3.安装第三方库
在进行爬取数据和解析数据前,需要在Python运行环境中下载安装第三方库requests。
在Windows系统中,打开cmd(命令提示符)界面,在该界面输入pip install requests,按回车键进行安装。(注意连接网络)如图3
图3
安装完成,如图4
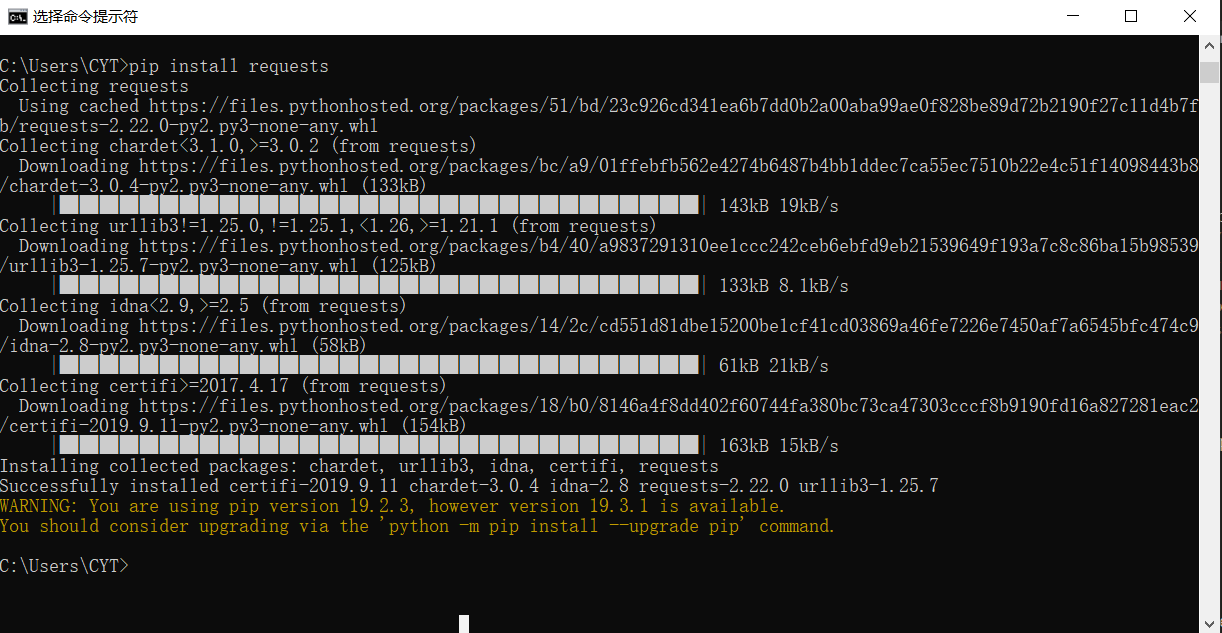
图4
4.爬取淘宝首页
# 请求库
import requests
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
运行结果,如图5
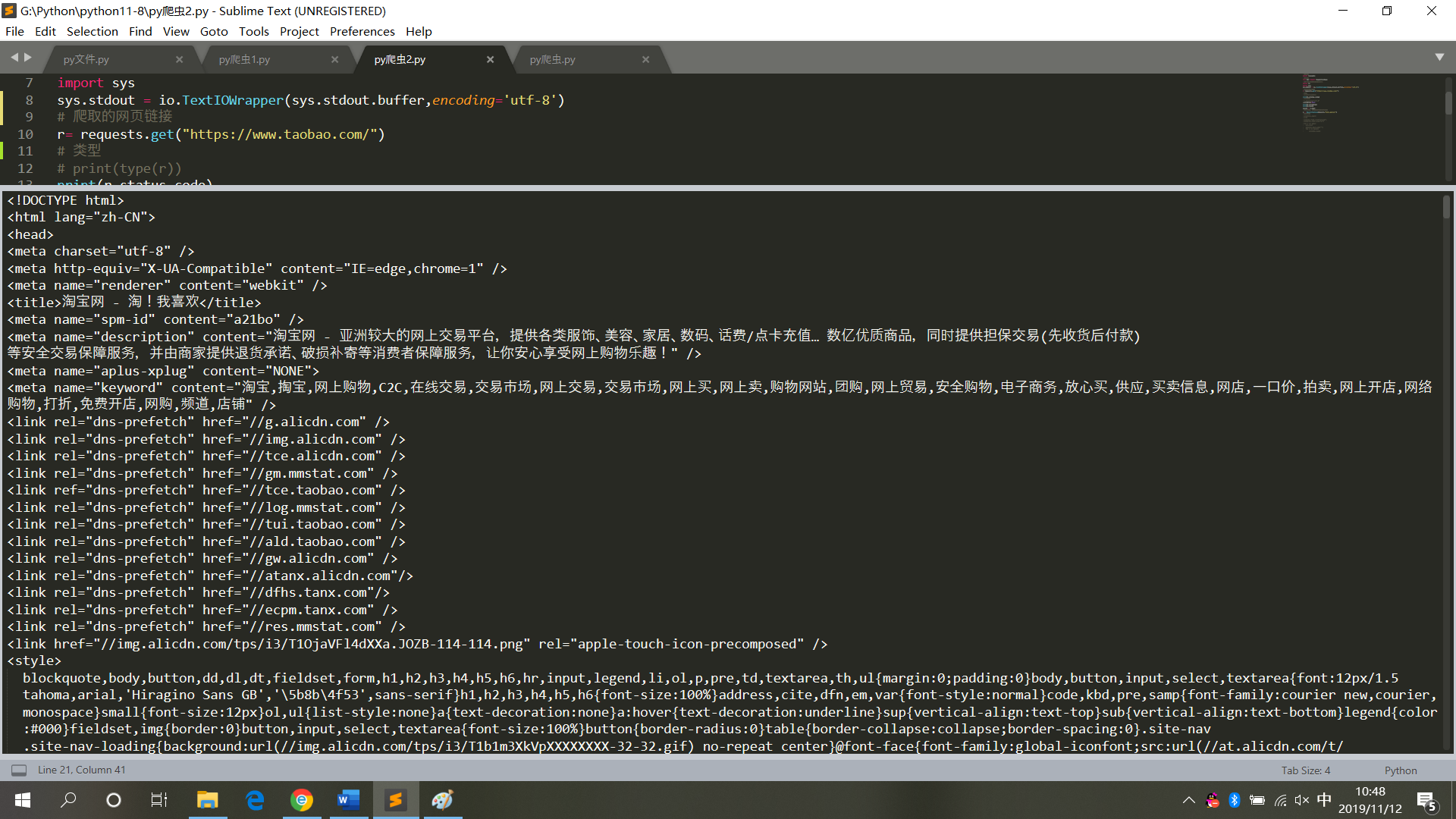
图5
5.爬取和解析淘宝网首页
# 请求库
import requests
# 解析库
from bs4 import BeautifulSoup
# 用于解决爬取的数据格式化
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')
# 爬取的网页链接
r= requests.get("https://www.taobao.com/")
# 类型
# print(type(r))
print(r.status_code)
# 中文显示
# r.encoding='utf-8'
r.encoding=None
print(r.encoding)
print(r.text)
result = r.text
# 再次封装,获取具体标签内的内容
bs = BeautifulSoup(result,'html.parser')
# 具体标签
print("解析后的数据")
print(bs.span)
a={}
# 获取已爬取内容中的script标签内容
data=bs.find_all('script')
# 获取已爬取内容中的td标签内容
data1=bs.find_all('td')
# 循环打印输出
for i in data:
a=i.text
print(i.text,end='')
for j in data1:
print(j.text)
运行结果,如图6
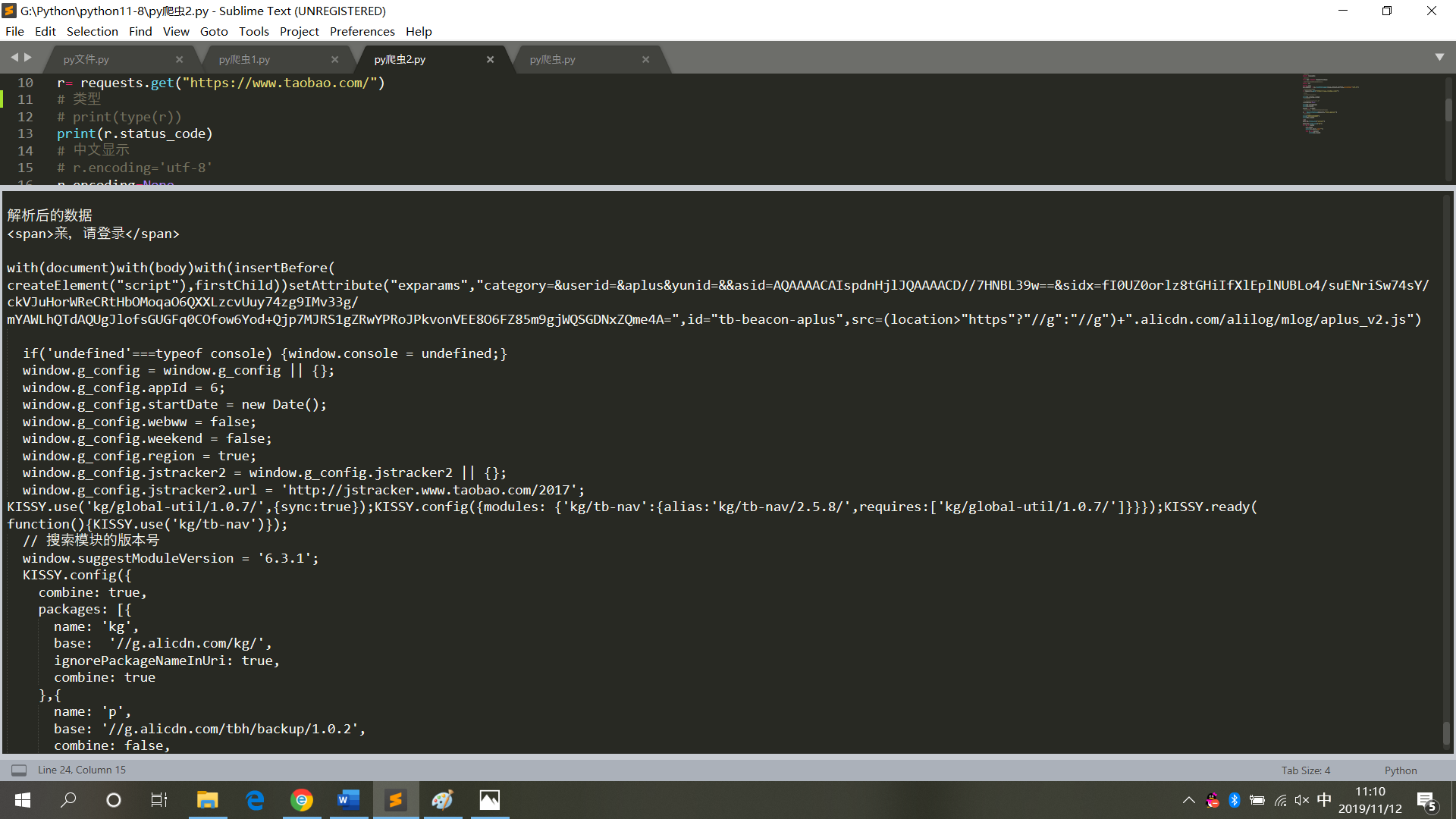
图6
7.小结
在对网页代码进行爬取操作时,不能频繁操作,更不要将其设置成死循环模式(每一次爬取则为对网页的访问,频繁操作会导致系统崩溃,会追究其法律责任)。
所以在获取网页数据后,将其保存为本地文本模式,再对其进行解析(不再需要访问网页)。
python爬虫——爬取网页数据和解析数据的更多相关文章
- python爬虫爬取get请求的页面数据代码样例
废话不多说,上代码 #!/usr/bin/env python # -*- coding:utf-8 -*- # 导包 import urllib.request import urllib.pars ...
- Python爬虫爬取异步加载的数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:努力努力再努力 爬取qq音乐歌手数据接口数据 https://y.qq ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- 1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by reco ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
随机推荐
- TCP/IP学习笔记3--传输方式的分类
网络通信中有多中分类方法: )分组较短.出错几率降低,每次重发的数据量也降低,不仅提高了可靠性,也降低了时延.缺点:(1)因为数据进入交换节点后要经历存储转发这一过程,从而引起的转发时延(包含接受分组 ...
- 开源之路2--SSH
SSH 为 Secure Shell (安全外壳协议)的缩写,由 IETF 的网络小组(Network Working Group)所制定:SSH是每一台Linux电脑的标准配置. SSH 是建立在应 ...
- Linux下创建Oracle19C的数据库实例
接上一篇博客,安装 Oracle19chttps://www.cnblogs.com/xuzhaoyang/p/11264557.html 切换到root用户下,切换目录到db_1,执行,遇到选择路径 ...
- [转帖]Merkle树
Merkle树 https://www.jianshu.com/p/fc439a8fd0de 所谓比特币交易就是从一个比特币钱包向另一个中转账,每笔交易都有数字签名来保证安全.一个交易一旦发生那么就是 ...
- fatal: unable to auto-detect email address (got 'CC@LAPTOP-UPQ1N1VQ.(none)')
git 提交问题出现小解决: 在输入 git commit -m "输入的是对这个版本的描述信息" 然后报错:fatal: unable to auto-detect email ...
- python列表生成式、键盘输入及类型转换、字符串翻转、字母大小写、数组广播、循环语句等基础问题
Python知识总结 1.列表生成式 在实际开发过程中,当需要获取一个连续列表时,可直接使用range(3,10),但是如果获取该列表中每个数据的平方时,通常可以通过for循环来解决这个问题,如下 ...
- 继承 多态 封装 Python面向对象的三大特性
1. 封装: 把很多数据封装到⼀个对象中. 把固定功能的代码封装到⼀个代码块, 函数, 对象, 打包成模块. 这都属于封装的思想. 具体的情况具体分析. 那这个也可以被称为封装. 2. 继承: 两个 ...
- Windows 10部署教程
1. 获取主板密钥 在powershell中执行: (Get-WmiObject -query 'select * from softwareLicensingService').OA3xOrigin ...
- leetcode整数反转
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转. 示例 1: 输入: 123输出: 321 示例 2: 输入: -123输出: -321 示例 3: 输入: 120输出: 21 ...
- Android--卸载应用
获取应用列表: List<PackageInfo> packages = getPackageManager().getInstalledPackages(0); for (Package ...