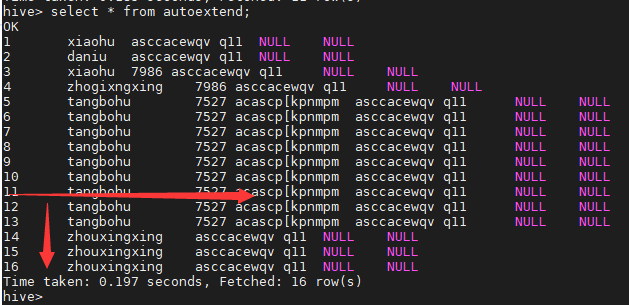
sqoop job 实现自动增量导入
一、测试环境
1、MySQL表结构
CREATE TABLE `autoextend` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(30) DEFAULT NULL,
`remark` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=17 DEFAULT CHARSET=latin1
2、hive表结构
OK
CREATE TABLE `autoextend`(
`id` string,
`name` string,
`remark` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://data0:9000/home/hadoop/hive/data/hdb.db/autoextend'
TBLPROPERTIES (
'transient_lastDdlTime'='1572594915')
二、普通增量导入
# 这个问题在于我们每次再增量导入的时候就要手动去更改--last-value \的值。
# 否则就每次都是全量导入。显得不灵活
sqoop import --connect jdbc:mysql://172.16.100.173:3306/hdb \
--username root --password oracletest \
--table autoextend \
-m 1 \
--incremental append \
--check-column id \
--last-value 11 \
--fields-terminated-by '\t' \
--hive-import --hive-database hdb --hive-table autoextend
三、sqoop job增量导入
1、sqoop job 参数
--create <job-id> Create a new saved job
--delete <job-id> Delete a saved job
--exec <job-id> Run a saved job
--help Print usage instructions
--list List saved jobs
--meta-connect <jdbc-uri> Specify JDBC connect string for the
metastore
--show <job-id> Show the parameters for a saved job
--verbose Print more information while working
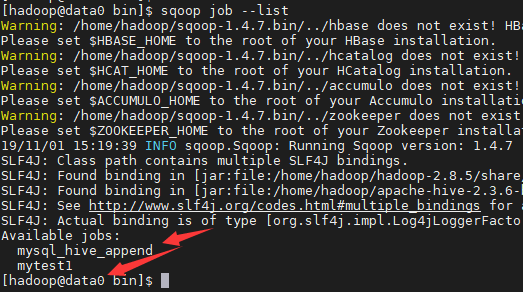
2、查看已经存在的job
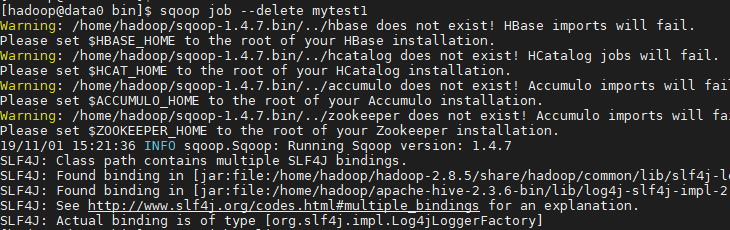
3、删除sqoop job
sqoop job --delete mytest1
4、创建sqoop job
sqoop job每次会为我们维护last-value的值,达到自动增量导入的目的
sqoop job --create myjobsqoop -- import --connect jdbc:mysql://172.16.100.173:3306/hdb --username root --password oracletest --table autoextend -m 1 --incremental append --check-column id --last-value 16 --fields-terminated-by '\t' --hive-import --hive-database hdb --hive-table autoextend

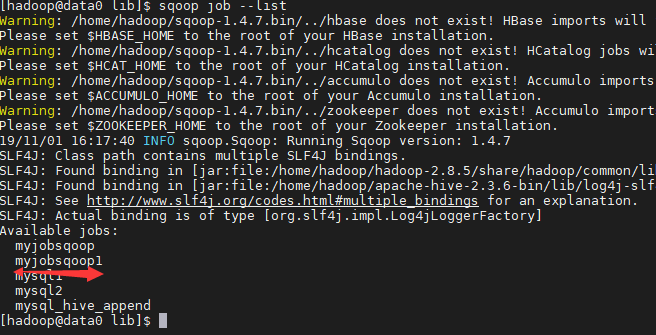
查看job
5、运行job并验证
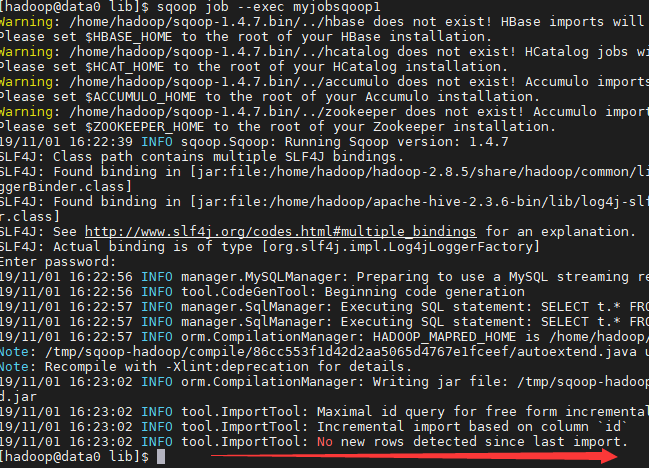
1)无新数据运行
sqoop job --exec myjobsqoop1
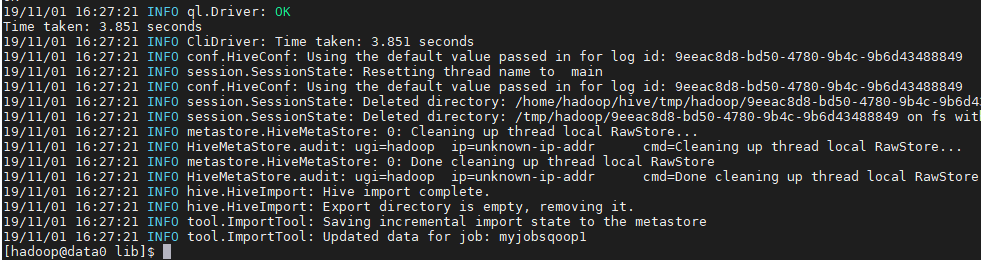
2)有新数据
MySQL新写入

运行sqoop job --exec myjobsqoop1
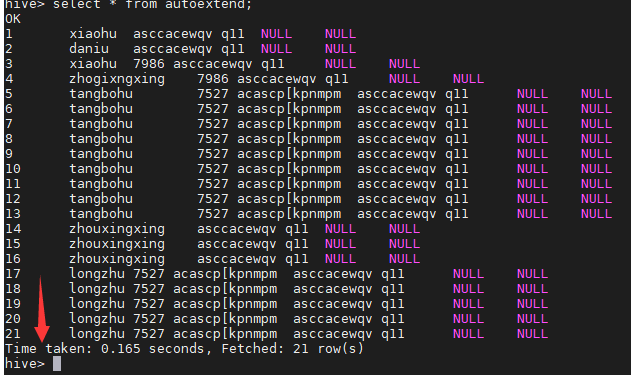
查看hive表
转载内容:
创建job
## -- import 中间有个空格
bin/sqoop job --create mysql_hive_append -- import --connect jdbc:mysql://hadoop001:3306/learn \
--username root --password 123456 \
--table user \
-m 1 \
--incremental append \
--check-column user_id \
--last-value 0 \
--fields-terminated-by ',' \
--hive-import \
--hive-table zzy.test3sqoop.Sqoop: Got exception running Sqoop:
java.lang.NullPointerException,没遇到可以跳过
19/09/20 09:57:47 ERROR sqoop.Sqoop: Got exception running Sqoop:
java.lang.NullPointerException
at org.json.JSONObject.<init>(JSONObject.java:144) ## 缺少的东西
at org.apache.sqoop.util.SqoopJsonUtil.getJsonStringforMap(SqoopJsonUtil.java:43)
at org.apache.sqoop.SqoopOptions.writeProperties(SqoopOptions.java:785)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.createInternal(HsqldbJobStorage.java:399)
at org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage.create(HsqldbJobStorage.java:379)
at org.apache.sqoop.tool.JobTool.createJob(JobTool.java:181)
at org.apache.sqoop.tool.JobTool.run(JobTool.java:294)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)查了半天是缺少java-json.jar这么一个jar包。找了半天大部分CSDN都要钱。下面整理了一些可下载的地址。
如果还是报同样的错误可能还需要下面这些包
百度网盘
运行job
bin/sqoop job --exec mysql_hive_append我这里明明设置了密码。但是还是要求我再输入一次mysql的连接密码。暂时没解决,输入就是了。
[zzy@hadoop001 sqoop-1.4.7]$bin/sqoop job --exec mysql_hive_append
19/09/20 10:20:29 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/moudle/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/moudle/hive-1.2.1/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Enter password:客服论坛400-660-0108
工作时间 8:30-22:00
sqoop job 实现自动增量导入的更多相关文章
- Sqoop(四)增量导入、全量导入、减量导入
增量导入 一.说明 当在生产环境中,我们可能会定期从与业务相关的关系型数据库向Hadoop导入数据,导入数仓后进行后续离线分析.这种情况下我们不可能将所有数据重新再导入一遍,所以此时需要数据增量导入. ...
- Sqoop实现自定义job的增量导入
需求:redis缓存的数据隔段时间往MySQL中写入一次.如果按照job的增量导入,比如上次redis向mysql导入数据时间为8:00,下一次导入时间为9:00,8:20sqoop进行增量导入,导入 ...
- sqoop定时增量导入导出
sqoop定时增量导入 2013-11-06 14:23 4553人阅读 评论(0) 收藏 举报 sqoop使用hsql来存储job信息,开启metastor service将job信息共享,所有no ...
- Sqoop修改sqoop元信息实现job的增量导入
最简单方式是按主键增量导入:http://blog.csdn.net/ggz631047367/article/details/50185319 以下方法只做存档 需求:redis缓存的数据隔段时间往 ...
- sqoop job 增量导入
使用sqoop job做增量导入 在执行导入模式为 incremental 的sqoop job 时,sqoop会获取上次导入操作的 –check-column的value值,也就是说使用sqoop ...
- sqoop的增量导入(increment import)
1.import增量导入的官方说明
- Sqoop增量导入
Argument Description --check-column (col) Specifies the column to be examined when determining which ...
- 大数据之路week07--day07 (Sqoop 从mysql增量导入到HDFS)
我们之前导入的都是全量导入,一次性全部导入,但是实际开发并不是这样,例如web端进行用户注册,mysql就增加了一条数据,但是HDFS中的数据并没有进行更新,但是又再全部导入一次又完全没有必要. 所以 ...
- 第3节 sqoop:6、sqoop的数据增量导入和数据导出
增量导入 在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据全部导入到hive或者hdfs当中去,肯定会出现重复的数据的状况,所以我们一般都是选用一些字段进行增量的导 ...
随机推荐
- Python学习日记(一) String函数使用
s = "abcaDa a" s2 = "123a abc ABCSAa s " s3 = "\tas \t\tb123" s4 = ' & ...
- 48 容器(七)——HashMap底层:哈希表结构与哈希算法
哈希表结构 哈希表是由数组+链表组成的,首先有一个数组,数组的每一个位置都用来存储一个链表,链表的基本节点为:[hash值,key值,value值,next],当存入一个键值对时,首先调用hashco ...
- PAT(B) 1067 试密码(Java)
题目链接:1067 试密码 (20 point(s)) 题目描述 当你试图登录某个系统却忘了密码时,系统一般只会允许你尝试有限多次,当超出允许次数时,账号就会被锁死.本题就请你实现这个小功能. 输入格 ...
- 3. Spark SQL解析
3.1 新的起始点SparkSession 在老的版本中,SparkSQL提供两种SQL查询起始点,一个叫SQLContext,用于Spark自己提供的SQL查询,一个叫HiveContext,用于连 ...
- PB 报表数值列加%
- Vue学习笔记(20190722)
- java之struts2之ajax
1.Ajax 技术在现有开发中使用非常多,大多是做管理类型系统.在servlet中可以使用ajax.在struts2中共还可以使用servlet的方式来实现ajax. 2.案例:用户名检查 publi ...
- java之struts2之数据检验
1.使用struts2时,有时候需要对数据进行相关的验证.如果对数据的要求比较严格,或对安全性要求比较高时,前端 js 验证还不够, 需要在后端再进行一次验证,保证数据的安全性. 2.struts2提 ...
- 命令行获取docker远程仓库镜像列表
命令行获取docker远程仓库镜像列表 获取思路 通过curl获取镜像tag的json串,解析后得到${image}:${tag}的格式 curl获取示例 # curl [:-s] ${API}/${ ...
- VS2017 Git failed with a fatal error. error: open(".vs/xxxxxx/v15/Server/sqlite3/db.lock"): Permission denied fatal: Unable to process path .vs/xxxxxx/v15/Server/sqlite3/db.lock
具体错误信息:Git failed with a fatal error. error: open(".vs/xxxxxx/v15/Server/sqlite3/db.lock") ...