HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货!
我的集群机器情况是 bigdatamaster(192.168.80.10)、bigdataslave1(192.168.80.11)和bigdataslave2(192.168.80.12)
然后,安装目录是在/home/hadoop/app下。
官方建议在master机器上安装Hue,我这里也不例外。安装在bigdatamaster机器上。
Hue版本:hue-3.9.0-cdh5.5.4
需要编译才能使用(联网) 说给大家的话:大家电脑的配置好的话,一定要安装cloudera manager。毕竟是一家人的。
同时,我也亲身经历过,会有部分组件版本出现问题安装起来要个大半天时间去排除,做好心里准备。废话不多说,因为我目前读研,自己笔记本电脑最大8G,只能玩手动来练手。
纯粹是为了给身边没高配且条件有限的学生党看的! 但我已经在实验室机器群里搭建好cloudera manager 以及 ambari都有。
大数据领域两大最主流集群管理工具Ambari和Cloudera Manger
Cloudera安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
Ambari安装搭建部署大数据集群(图文分五大步详解)(博主强烈推荐)
首先,这是官网提供的参考步骤
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.0/manual.html

一、以下是默认的配置文件
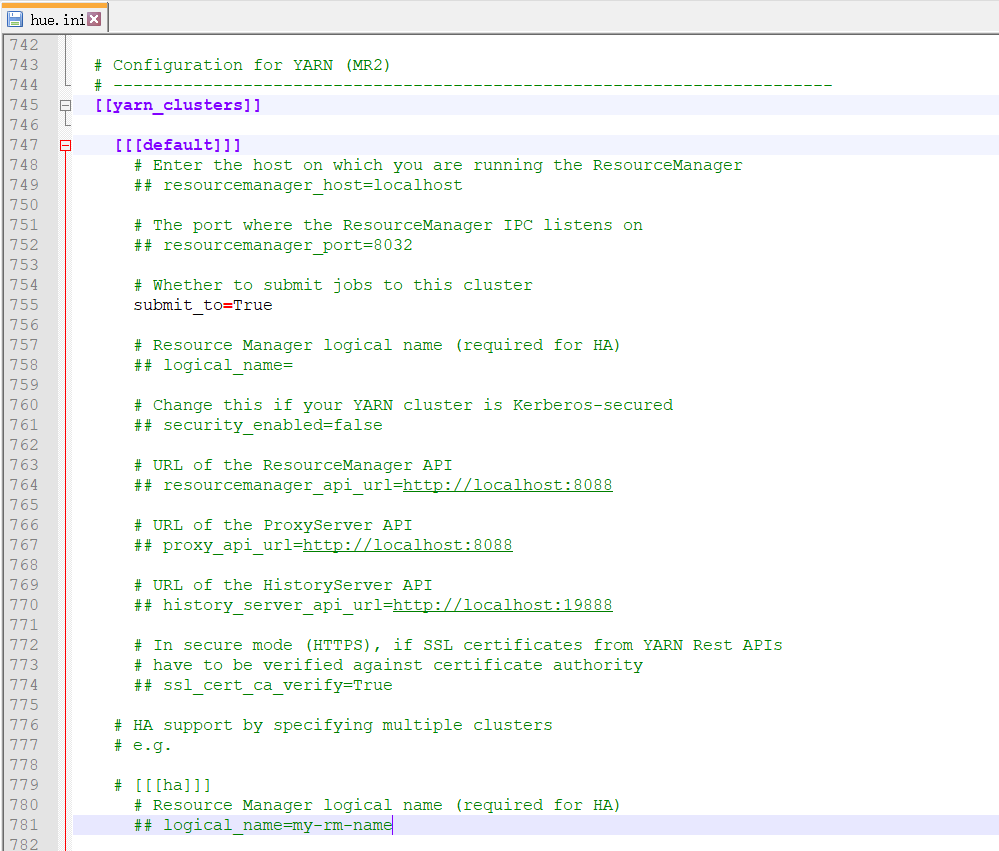
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]] [[[default]]]
# Enter the host on which you are running the ResourceManager
## resourcemanager_host=localhost # The port where the ResourceManager IPC listens on
## resourcemanager_port= # Whether to submit jobs to this cluster
submit_to=True # Resource Manager logical name (required for HA)
## logical_name= # Change this if your YARN cluster is Kerberos-secured
## security_enabled=false # URL of the ResourceManager API
## resourcemanager_api_url=http://localhost:8088 # URL of the ProxyServer API
## proxy_api_url=http://localhost:8088 # URL of the HistoryServer API
## history_server_api_url=http://localhost:19888 # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # HA support by specifying multiple clusters
# e.g. # [[[ha]]]
# Resource Manager logical name (required for HA)
## logical_name=my-rm-name
二、以下是跟我机器集群匹配的配置文件(非HA集群下怎么配置Hue的yarn_clusters模块)


最终我的非HA配置信息如下
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]] [[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=bigdatamaster # The port where the ResourceManager IPC listens on
resourcemanager_port= # Whether to submit jobs to this cluster
submit_to=True # Resource Manager logical name (required for HA)
## logical_name= # Change this if your YARN cluster is Kerberos-secured
## security_enabled=false # URL of the ResourceManager API
resourcemanager_api_url=http://bigdatamaster:8088 # URL of the ProxyServer API
proxy_api_url=http://bigdatamaster:8088 # URL of the HistoryServer API
history_server_api_url=http://bigdatamaster:19888 # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # HA support by specifying multiple clusters
# e.g. # [[[ha]]]
# Resource Manager logical name (required for HA)
## logical_name=my-rm-name
三、以下是跟我机器集群匹配的配置文件(HA集群下怎么配置Hue的yarn_clusters模块)
hadoop-2.6.0.tar.gz的集群搭建(5节点)
这里需要说明一下,[[[default]]] 和 [[ha]]中各配置一个RM。

logical_name名字就是你集群中yarn-site.xml中配置的
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
URL of the ResourceManager API 这里配置资源管理的地址和端口,对应yarn-site.xml中的
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>djt11:</value>
</property> <property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>djt12:</value>
</property>
那么就要如下来配置
# URL of the ResourceManager API
resourcemanager_api_url=djt11:8088,djt12:8088
URL of the HistoryServer API 这里配置历史记录资源管理的地址和端口,对应mapred-site.xml中的
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>djt13:</value>
</property>
所以,我的HA最终如下配置
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]] [[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=cluster1 # The port where the ResourceManager IPC listens on
resourcemanager_port= # Whether to submit jobs to this cluster
submit_to=True # Resource Manager logical name (required for HA)
logical_name=rm1 # Change this if your YARN cluster is Kerberos-secured
## security_enabled=false # URL of the ResourceManager API
resourcemanager_api_url=http://djt11:8088 # URL of the ProxyServer API
proxy_api_url=http://djt13:8088 # URL of the HistoryServer API
history_server_api_url=http://bigdatamaster:19888 # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # HA support by specifying multiple clusters
# e.g. # [[[ha]]]
# Resource Manager logical name (required for HA)
logical_name=rm2
resourcemanager_api_url=http://djt12:23188
history_server_api_url=http://djt13:19888
submit_to=True
成功!
或者,HA集群也可以如下来做
我们首先查看yarn-site.xml

<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rs</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata-pro01.kfk.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata-pro02.kfk.com</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>bigdata-pro01.kfk.com:,bigdata-pro02.kfk.com:,bigdata-pro03.kfk.com:</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata-pro01.kfk.com:,bigdata-pro02.kfk.com:,bigdata-pro03.kfk.com:</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property> <property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
以上,我的yarn-site.xml配置文件。
然后,修改配置hue.ini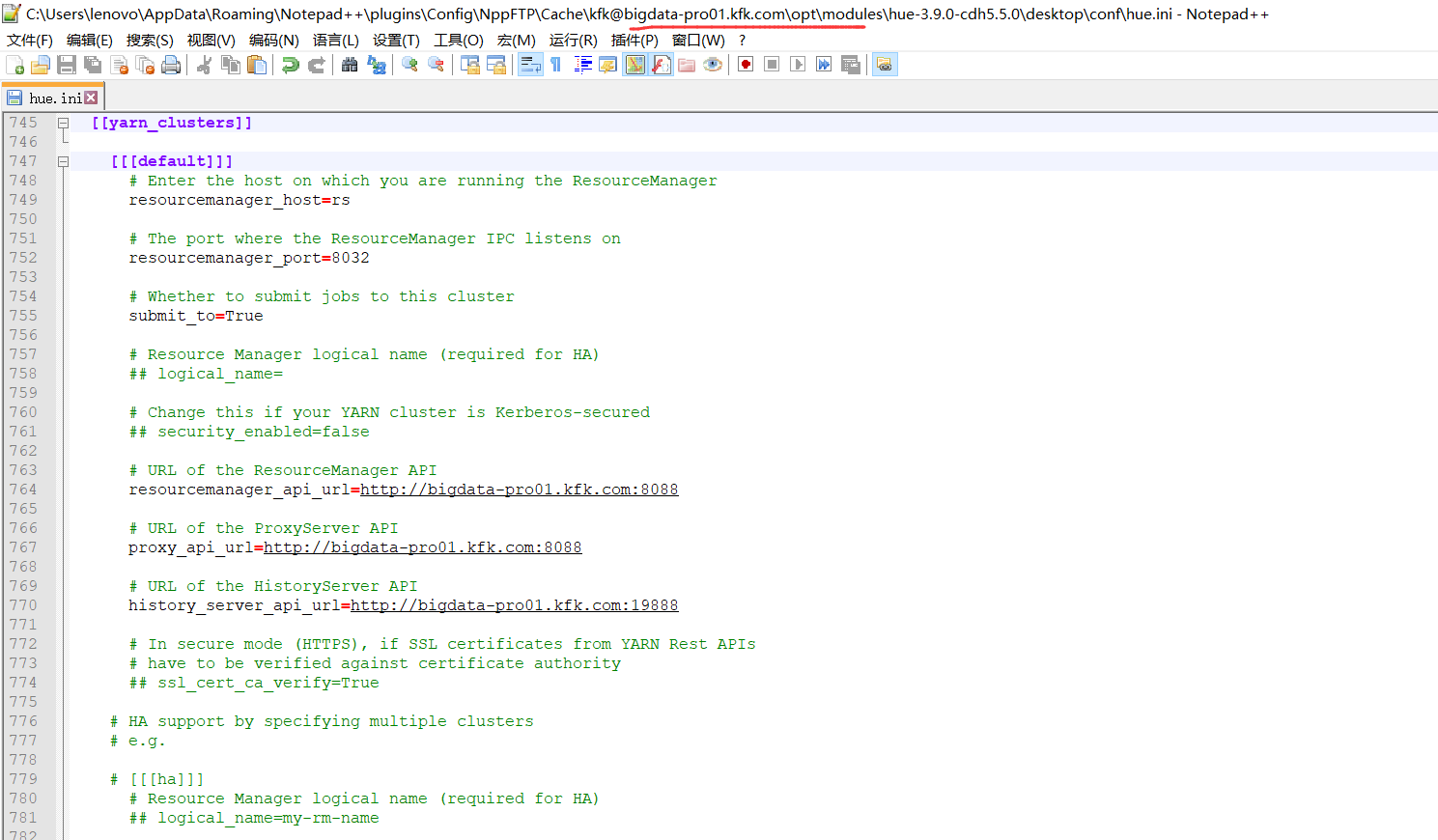
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]] [[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=rs # The port where the ResourceManager IPC listens on
resourcemanager_port= # Whether to submit jobs to this cluster
submit_to=True # Resource Manager logical name (required for HA)
## logical_name= # Change this if your YARN cluster is Kerberos-secured
## security_enabled=false # URL of the ResourceManager API
resourcemanager_api_url=http://bigdata-pro01.kfk.com:8088 # URL of the ProxyServer API
proxy_api_url=http://bigdata-pro01.kfk.com:8088 # URL of the HistoryServer API
history_server_api_url=http://bigdata-pro01.kfk.com:19888 # In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True # HA support by specifying multiple clusters
# e.g. # [[[ha]]]
# Resource Manager logical name (required for HA)
## logical_name=my-rm-name
配置完成后,先停止yarn,再重新启动yarn,再重新启动hue。
参考
http://gethue.com/hadoop-tutorial-yarn-resource-manager-high-availability-ha-in-mr2/
http://www.cloudera.com/content/cloudera/en/documentation/core/latest/topics/cdh_ig_hue_config.html
http://cloudera.github.io/hue/docs-3.8.0/manual.html#_hadoop_configuration

同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)的更多相关文章
- HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hbase模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的impala模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的filebrowser模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的pig模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 一.默认的pig配置文件 ########################################################################### ...
- HUE配置文件hue.ini 的liboozie和oozie模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
随机推荐
- SecureCRT和乱码
示例: # ls /usr/local/r3c/bin/lib /bin/ls: /usr/local/r3c/bin/lib: ????????? 查看系统字符集设置: # locale LANG= ...
- linux上安装tomcat
这里采用离线解压tar.gz的方式安装 下载: wget http://mirror.bit.edu.cn/apache/tomcat/tomcat-8/v8.0.33/bin/apache-tomc ...
- 201709012工作日记--一台电脑创建两个Github账户上传代码
1. 在一台主机上面使用多个GitHub账号 有时候,我们需要将个人账号和公司账号区分,这时候我们就会需要在一台电脑上使用2个不同的git账号. 2. 上传文件 http://blog.csdn.ne ...
- eclipse如何恢复误删文件
刚刚真的要吓死宝宝了,不是说宝宝心里素质差,是因为刚刚误删的文件实在是太重要了,废话不多说了,正题 如何恢复eclipse误删的文件 1,当时被误删了,可立即 Ctrl+z 即可恢复误删文件; 2,时 ...
- KNN和K-Means的区别
KNN和K-Means的区别 KNN K-Means 1.KNN是分类算法 2.监督学习 3.喂给它的数据集是带label的数据,已经是完全正确的数据 1.K-Means是聚类算法 2.非监督学习 3 ...
- SQL Server 2016最值得关注的10大新特性
全程加密技术(Always Encrypted) 全程加密技术(Always Encrypted)支持在SQL Server中保持数据加密,只有调用SQL Server的应用才能访问加密数据.该功能支 ...
- 统一登录中心SSO 单点登录系统的构想
什么是单点登录?我想肯定有一部分人“望文生义”的认为单点登录就是一个用户只能在一处登录,其实这是错误的理解.单点登录指的是多个子系统只需要登录一个,其他系统不需要登录了(一个浏览器内).一个子系统退出 ...
- c#常用的预处理器指令
预处理器指令指导编译器在实际编译开始之前对信息进行预处理.所有的预处理器指令都是以 # 开始. #define 预处理器指令创建符号常量.#define 允许您定义一个符号,这样,通过使用符号作为传递 ...
- C# DataTable导出EXCEL后身份证、银行卡号等长数字信息显示乱码解决
在DataTable导出EXCEL后发现有些格式显示有问题,比如身份证.银行卡号等大于11位的数字显示为科学计数法.13681-1等 带中划线的两段数字显示为日期格式等. 处理方法如下: public ...
- flask源码解析之session
内容回顾 cookie与session的区别: 1. session 是保存在服务端的键值对 2. cookie 只能保存4096个字节的数据,但是session不受限制 3. cookie保存在浏览 ...