Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好
那么如何集成selenium到scrapy中呢?
因为每一次request的请求都要经过中间件,所以写在中间件中最为合适
from selenium import webdriver
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
def process_request(self, request, spider):
if spider.name == "xinlang": # 这只是一个示例表示爬虫为新浪,当然可以自定义比如正则表达式对于某一种网址来进行过滤
browser = webdriver.Chrome()
browser.get(request.url)
import time
time.sleep(3)
print("访问:{0}".format(request.url)) # 如何在这里发送完成之后就不发送给scrapy下载器了呢?
return HtmlResponse(url=browser.current_url, body=browser.page_source, encoding="utf-8",request=request)
# 一旦遇到HTMLResponse,scrapy就不会向download发送了,而是直接返回给spider了,上面所有值都是必须的
注意别忘了 将中间件写入到settings中!
是不是可以优化的空间了呢?
每一次请求都要打开一次Chrome,这个就很烦了,因为速度比较慢
from selenium import webdriver
from scrapy.http import HtmlResponse
class JSPageMiddleware(object):
def __init__(self):
self.browser = webdriver.Chrome
super().__init__() def process_request(self, request, spider):
if spider.name == "xinlang": # 这只是一个示例表示爬虫为新浪,当然可以自定义比如正则表达式对于某一种网址来进行过滤
self.browser.get(request.url)
import time
time.sleep(3)
print("访问:{0}".format(request.url)) # 如何在这里发送完成之后就不发送给scrapy下载器了呢?
return HtmlResponse(url=self.browser.current_url, body=self.browser.page_source, encoding="utf-8", request=request)
# 一旦遇到HTMLResponse,scrapy就不会向download发送了,而是直接返回给spider了,上面所有值都是必须的
这样只需要打开一次Chrome了,但是,注意下,这样的话scrapy就不会关闭了,那怎么办?
我们把它放到spider中

那这样的话,中间件中改为
from scrapy.http import HtmlResponse
class JSPageMiddleware(object): def process_request(self, request, spider):
if spider.name == "xinlang":
spider.browser.get(request.url) # 利用spider来进行调用
import time
time.sleep(3)
print("访问:{0}".format(request.url)) # 如何在这里发送完成之后就不发送给scrapy下载器了呢?
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)
但是这样还是有问题,我咋知道什么时间关闭?
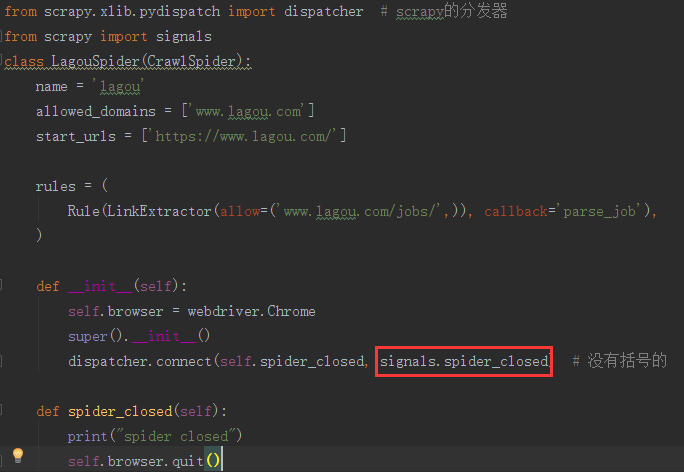
from selenium import webdriver
from scrapy.xlib.pydispatch import dispatcher # scrapy的分发器
from scrapy import signals
class LagouSpider(CrawlSpider):
name = 'lagou'
allowed_domains = ['www.lagou.com']
start_urls = ['https://www.lagou.com/'] rules = (
Rule(LinkExtractor(allow=('www.lagou.com/jobs/',)), callback='parse_job'),
) def __init__(self):
self.browser = webdriver.Chrome
super().__init__()
dispatcher.connect(self.spider_closed, signals.spider_closed) # 没有括号的 def spider_closed(self):
print("spider closed")
self.browser.quit()
是不是和django的用法非常一致?
但是异步处理的时候,则么办,现在是一个同步的请求!
那么重写download
git 搜索scrapy download一搜便知
Scrapy中集成selenium的更多相关文章
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- scrapy中使用selenium来爬取页面
scrapy中使用selenium来爬取页面 from selenium import webdriver from scrapy.http.response.html import HtmlResp ...
- 如何优雅的在scrapy中使用selenium —— 在scrapy中实现浏览器池
1 使用 scrapy 做采集实在是爽,但是遇到网站反爬措施做的比较好的就让人头大了.除了硬着头皮上以外,还可以使用爬虫利器 selenium,selenium 因其良好的模拟能力成为爬虫爱(cai) ...
- scrapy中的selenium
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 爬虫之scrapy框架应用selenium
一.利用selenium 爬取 网易军事新闻 使用流程: ''' 在scrapy中使用selenium的编码流程: 1.在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性) ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
随机推荐
- C#后台接java接口传输字节数组(byte[])
事情是这样的C#t代码之前接的WCF接口,后来那边统一改为java的接口,我是用的HttpClient从后台发请求调用的java接口,其他接口都很顺利,是的....知道遇到一个需要传byte[]类型数 ...
- Three failed attempts of handling non-sequential data
The Progress of Products Classification Cause now we are considering to classify the product by two ...
- pinyin.js
export default { a: "\u554a\u963f\u9515", ai: "\u57c3\u6328\u54ce\u5509\u54c0\u7691\u ...
- SpringBoot+Mybatis+Maven+MySQL逆向工程实现增删改查
SpringBoot+Mybatis+MySQL+MAVEN逆向工程实现增删改查 这两天简单学习了下SpringBoot,发现这玩意配置起来是真的方便,相比于SpringMVC+Spring的配置简直 ...
- charles抓不到APP内的某些接口-解决部分汇总
首先,让我哭会,我竟然自己解决了问题.网上查的解决办法都试过了就是不管用,也问过前辈,就是没招. 果然,自立自强,勇者不息. Top1 问题:charles抓不到接口? 现象:web端的网络请求OK, ...
- IntelliJ IDEA SVN突然没有了
1.在IDEA中找不到 SVN 的选项了,版本控制工具中没有subversion,在setting中也无法查询到对应的svn工具,这是因为我们在idea的svn插件中把svn这个选项禁用了 解决办法: ...
- Kafka(1)--kafka基础知识
Kafka 的简介: Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Ap ...
- vue与dajngo
怎么说,网上找的例子真的不是一般的坑,根本就是少了很多流程让人故意看不懂 第一步,创建好我们的app django-admin startproject weeklyapp 这是创建我们的整个系统ap ...
- python大法好——Python XML解析
Python XML解析 什么是XML? XML 被设计用来传输和存储数据. XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这些部件加以标识. 它也是元标记语言,即定义了用于定义其他与 ...
- C# 拖拽事件
实现一个textBox像另一个TextBox拖拽数据. 一个控件想要被拖入数据的前提是AllowDrop属性为true. 所以,首先需要将被拖入数据的textBox的AllowDrop属性设置为Tru ...