Event Recommendation Engine Challenge分步解析第一步
一、简介
此项目来自kaggle:https://www.kaggle.com/c/event-recommendation-engine-challenge/
数据集的下载需要账号,并且需要手机验证(之前如果kaggle账号已经验证过,就不需要验证了),验证的时候手机号前面需要加上860:
这里我已经将数据下载,并上传到百度云盘,链接:https://pan.baidu.com/s/1KDZN313XkbhkRDZX4dLYNA 提取码:ino3
背景介绍
根据user actions, event metadata, and demographic information(社交信息)预测用户对哪个event感兴趣
桌面新建文件夹:推荐比赛->进入推荐比赛文件夹->shift + 右键->在此处新建命令窗口->jupyter notebook->新建recommend脚本,将上面下载的数据解压到推荐比赛文件夹
1)第一步:统计user和event相关信息
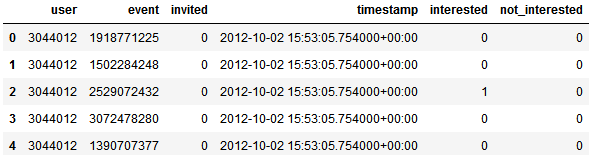
我们先看看train.csv:
import pandas as pd
df_train = pd.read_csv('train.csv')
df_train.head()
结果如下:前两列是用户ID和对应的event ID
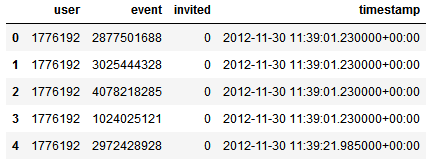
而test.csv中用户缺少了标签:
让我们来看看第一步的完整代码:
from collections import defaultdict
import scipy.sparse as ss
import scipy.io as sio
import itertools
#import cPickle
#From python3, cPickle has beed replaced by _pickle
import _pickle as cPickle class ProgramEntities:
"""
我们只关心train和test中出现的user和event,因此重点处理这部分关联数据,
经过统计:train和test中总共3391个users和13418个events
"""
def __init__(self):
#统计训练集中有多少独立的用户的events
uniqueUsers = set()#uniqueUsers保存总共多少个用户:3391个
uniqueEvents = set()#uniqueEvents保存总共多少个events:13418个
eventsForUser = defaultdict(set)#字典eventsForUser保存了每个user:所对应的event
usersForEvent = defaultdict(set)#字典usersForEvent保存了每个event:哪些user点击
for filename in ['train.csv', 'test.csv']:
f = open(filename)
f.readline()#跳过第一行
for line in f:
cols = line.strip().split(',')
uniqueUsers.add( cols[0] )
uniqueEvents.add( cols[1] )
eventsForUser[cols[0]].add( cols[1] )
usersForEvent[cols[1]].add( cols[0] )
f.close() self.userEventScores = ss.dok_matrix( ( len(uniqueUsers), len(uniqueEvents) ) )
self.userIndex = dict()
self.eventIndex = dict()
for i, u in enumerate(uniqueUsers):
self.userIndex[u] = i
for i, e in enumerate(uniqueEvents):
self.eventIndex[e] = i ftrain = open('train.csv')
ftrain.readline()
for line in ftrain:
cols = line.strip().split(',')
i = self.userIndex[ cols[0] ]
j = self.eventIndex[ cols[1] ]
self.userEventScores[i, j] = int( cols[4] ) - int( cols[5] )
ftrain.close()
sio.mmwrite('PE_userEventScores', self.userEventScores) #为了防止不必要的计算,我们找出来所有关联的用户或者关联的event
#所谓关联用户指的是至少在同一个event上有行为的用户user pair
#关联的event指的是至少同一个user有行为的event pair
self.uniqueUserPairs = set()
self.uniqueEventPairs = set()
for event in uniqueEvents:
users = usersForEvent[event]
if len(users) > 2:
self.uniqueUserPairs.update( itertools.combinations(users, 2) )
for user in uniqueUsers:
events = eventsForUser[user]
if len(events) > 2:
self.uniqueEventPairs.update( itertools.combinations(events, 2) )
#rint(self.userIndex)
cPickle.dump( self.userIndex, open('PE_userIndex.pkl', 'wb'))
cPickle.dump( self.eventIndex, open('PE_eventIndex.pkl', 'wb') ) print('第1步:统计user和event相关信息...')
pe = ProgramEntities()
print('第1步完成...\n')
其中PE_userEventScores.mtx是所有users和events的矩阵,但是里面的值只有train.csv的值,值是1或者-1
scipy.sparse.dok_matrix()函数是产生一个稀疏矩阵,这样PE_userEventScores.mtx只保存了非0值
针对该步使用的变量作简单介绍:
uniqueUsers:集合,保存train.csv和test.csv中的所有user ID
uniqueEvents:集合,保存train.csv和test.csv中的所有event ID
eventsForUser:字典,key为每个用户,value为该用户对应的event集合
usersForEvent:字典,key为每个event,value为该event对应的user集合
userIndex:字典,每个用户有个Index
eventIndex:字典,每个event有个Index
userEventScores:稀疏矩阵3391 * 13418,use vs event,矩阵元素为train.csv中每个user对某个event的兴趣分(1, 0 or -1)即interested - not_interested
import pandas as pd
pd.DataFrame(userEventScores)
代码示例结果:

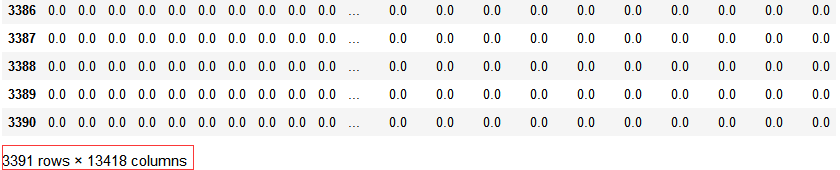
userEventScores:每个user对每个event的兴趣分(1, 0 or -1)
uniqueUserPairs:集合,如果对于同一个event来说,关联上3个及3个以上users,则该event关联上的users进行两两配对,保存在uniqueUserPairs中,注意保存的是userId,而不是user对应的索引:
import pandas as pd
df_train = pd.read_csv('train.csv')
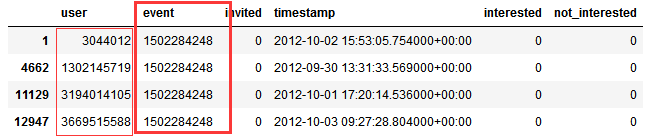
df_train[df_train['event']==1502284248] import itertools
for each in itertools.combinations(set([3044012,1302145719,3194014105,3669515588]), 2):
print(each)
代码结果示例:

uniqueEventPairs:集合,对于同一个用户,如果其关联的events大于等于3,则这些关联的events保存在uniqueEventPairs中,注意保存的是event id,而不是event对应的索引:
import pandas as pd
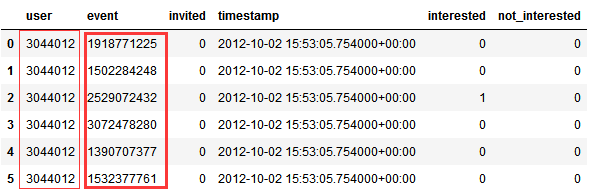
df_train = pd.read_csv('train.csv')
df_train[df_train['user']==3044012] import itertools
for each in itertools.combinations(set([1918771225,1502284248,2529072432, 3072478280, 1390707377, 1532377761 ]), 2):
print(each)
代码结果示例:

cPickle模块(python3为pickle或者_pickle模块):请参考pickle详解
至此,第一步完成,哪里有不明白的请留言
我们继续看Event Recommendation Engine Challenge分步解析第二步
Event Recommendation Engine Challenge分步解析第一步的更多相关文章
- Event Recommendation Engine Challenge分步解析第七步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第六步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第五步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第四步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第三步
一.请知晓 本文是基于: Event Recommendation Engine Challenge分步解析第一步 Event Recommendation Engine Challenge分步解析第 ...
- Event Recommendation Engine Challenge分步解析第二步
一.请知晓 本文是基于Event Recommendation Engine Challenge分步解析第一步,需要读者先阅读上篇文章解析 二.用户相似度计算 第二步:计算用户相似度信息 由于用到:u ...
- Comprehensive Guide to build a Recommendation Engine from scratch (in Python) / 从0开始搭建推荐系统
https://www.analyticsvidhya.com/blog/2018/06/comprehensive-guide-recommendation-engine-python/, 一篇详细 ...
- UE4蓝图编程的第一步
认识UE4蓝图中颜色与变量类型: UE4中各个颜色对应着不同的变量,连接点和连线的颜色都在表示此处是什么类型的变量.对于初学者来说一开始看到那么多连接点, 可能会很茫然,搞不清还怎么连,如果知道了颜色 ...
- 重制AdvanceWars第一步 -- 搞定地图
首先来聊下高级战争吧Advance Wars,由任天堂旗下的Intelligent Systems开发的战棋游戏.初作诞生于GBA上,后来继续跟进了高战2黑洞崛,而后在下一代掌机DS上也出了三代续作高 ...
随机推荐
- Django通用视图APIView和视图集ViewSet的介绍和使用
原 Django通用视图APIView和视图集ViewSet的介绍和使用 2018年10月21日 14:42:14 不睡觉假扮古尔丹 阅读数:630 1.APIView DRF框架的视图的基类是 ...
- oracle的用户账号密码设置
1. 可以用sqlplus system/你输入的密码 可以用sqlplus /nolog 可以用sqlplus /as sysdba2. @你scott.sql的路径3. 修改你的账号 alter ...
- Git——简说.git目录【五】
我们都知道初始化项目时,会生成一个.git的隐藏目录,那么这个目录究竟放了那些东西呢,又有什么作用呢?现在我们就来看看. HEAD HEAD指向的是当前工作所在的分支 $ cat HEAD ref: ...
- Codeforces1073E Segment Sum 【数位DP】
题目分析: 裸的数位DP,注意细节. #include<bits/stdc++.h> using namespace std; ; int k; ][],sz[][],cnt[][]; ] ...
- BZOJ5296 [CQOI2018] 破解D-H协议 【数学】【BSGS】
题目分析: 裸题. 代码: #include<bits/stdc++.h> using namespace std; typedef long long ll; ; #define mp ...
- 一个有关FWT&FMT的东西
这篇文章在讲什么 相信大家都会FWT和FMT. 如果你不会,推荐你去看一下VFK的2015国家集训队论文. 设全集为\(U=\{1,2,\ldots,n\}\),假设我们关心的\(f_S\)中的集合\ ...
- tp5命令行基础介绍
查看指令 生成模块 生成文件 生成类库映射文件 生成路由缓存文件 生成数据表字段缓存文件 指令扩展示例 命令行调试 命令行颜色支持 调用命令 查看指令 命令行工具需要在命令行下面执行,请先确保你的ph ...
- MT【310】均值不等式
(2014北约自主招生)已知正实数$x_1,x_2,\cdots,x_n$满足$x_1x_2\cdots x_n=1,$求证:$(\sqrt{2}+x_1)(\sqrt{2}+x_2)\cdots(\ ...
- Min_25 筛小结
Min_25 筛这个东西,完全理解花了我很长的时间,所以写点东西来记录一些自己的理解. 它能做什么 对于某个数论函数 \(f\),如果满足以下几个条件,那么它就可以用 Min_25 筛来快速求出这个函 ...
- android ViewStub简单介绍
ViewStub是一种非常灵活的视图,主要用于布局资源的实时加载. ViewStub 的继承类关系如下: public final class ViewStubextends View java.la ...