filebeat-kafka日志收集
filebeat-kafka日志收集
由于线上的logstash吃掉大量的CPU,占用较多的系统资源,就想找其它的组件替代.我们的日志需要收集并发送到kafka,生成的日志已经是需要的数据,不用过滤.经过调研发现filebeat也支持发往kafka.
filebeat很轻量,用于转发和收集日志数据.filebeat作为代理安装在服务器上,监视指定的日志文件或位置,收集日志事件,并将他们转发到logstash,elasticsearch,kafka等.架构图如下:
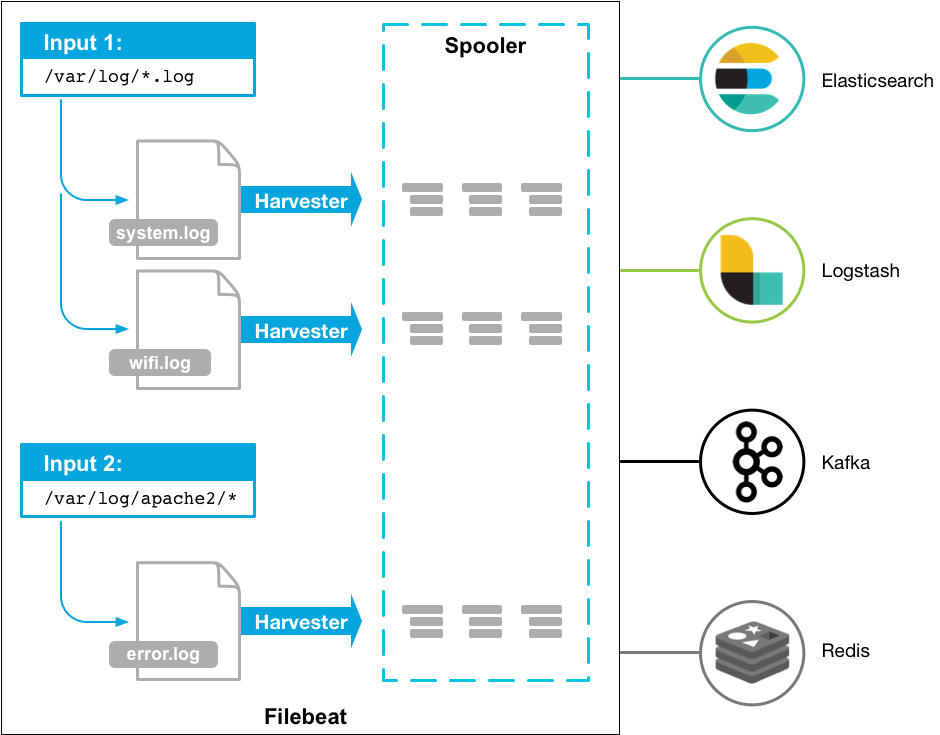
安装
获取安装包并解压
# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.1-linux-x86_64.tar.gz
# tar -xvf filebeat-6.5.1-linux-x86_64.tar.gz
配置
filebeat支持很多种输入和输出.具体可看input,output.
项目中用到的输入是log,输出的kafka.在这只讲这两种配置.
输入配置log
log输入是从文件中按行读取.在paths指定需要监视的文件.
例子:
filebeat.inputs:
- type: log
paths:
- /var/log/messages
- /var/log/*.log
主要有以下几个配置项.
paths
需要监视的文件路径.支持Go Glab的所有模式.例如: /var/log/*.log.这个配置将监视/var/log文件夹下所有以.log结尾的文件.可以用recursive_glob来递归子文件夹.
recursive_glob.enabled
允许扩展 * * 为递归的glob模式.启用此功能后. /foo/* * 扩展到/foo, /foo/* ,/foo/* /* ,等等,它会将单个扩展 * * 为8级深度*模式.
默认情况下启用此功能.设置false禁用.
exclude_lines
正则表达式列表,用于匹配您希望Filebeat排除的行.Filebeat会删除与列表中的正则表达式匹配的所有行.默认情况下,不会删除任何行.空行被忽略.
以下示例将Filebeat配置为删除任何以DBG开头的行:
filebeat.inputs:
- type: log
...
exclude_lines: ['^DBG']
include_lines
正则表达式列表,用于匹配您希望Filebeat包含的行.Filebeat仅导出与列表中的正则表达式匹配的行.默认情况下,将导出所有行.空行被忽略.
以下示例将Filebeat配置为导出以ERR或WARN开头的所有行:
filebeat.inputs:
- type: log
...
include_lines: ['^ERR', '^WARN']
PS: 如果include_lines和exclude_lines两个配置同时出现,优先执行inlcude_lines再执行exclude_lines.和配置项放的位置没有关系.
json
filebeat支持json格式的消息日志.它将逐行处理日志,因此只有每行有一个json对象时,json解码才有效.
配置示例:
json.keys_under_root: true
json.add_error_key: true
json.message_key: log
enabled
输入开关.默认true打开.
输出配置kafka
kafka将输出流发送到Apache Kafka.
配置示例:
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
# message topic selection + partitioning
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
主要以下几个配置项
enabled
是否打开输出配置项.true打开,false关闭.默认是true.
hosts
kafka的broker地址.
topic
kafka的topic.
worker
并发负载均衡Kafka输出工作线程的数量.
timeout
kafka返回应答的等待时间.默认30(秒).
keep_alive
连接的存活时间.如果为0,表示短连,发送完就关闭.默认为0秒.
required_acks
ACK的可靠等级.0=无响应,1=等待本地消息,-1=等待所有副本提交.默认1.
PS: 如果设为0,kafka无应答返回时,消息将丢失.
配置例子
#=========================== Filebeat inputs =============================
#------------------------------log-----------------------------------
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/collect_log/info.*
#=========================== Filebeat outputs =============================
#------------------------------kafka-----------------------------------
output.kafka:
hosts: ["test1:9092","test2:9092"]
topic: test_collect
keep_alive: 10s
收集/data/collect_log目录下以info开头的文件,发送到kafka,kafka的topic是test_collect.
启动
# /home/filebeat -c filebeat-kafka.yml
日志在filebeat下的log目录.想要显示的看日志启动时加 -e 参数.
参考文档: https://www.elastic.co/guide/en/beats/filebeat/current/configuring-howto-filebeat.html
filebeat-kafka日志收集的更多相关文章
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- ELK+kafka日志收集
一.服务器信息 版本 部署服务器 用途 备注 JDK jdk1.8.0_102 使用ELK5的服务器 Logstash 5.1.1 安装Tomcat的服务器 发送日志 Kafka降插件版本 Log ...
- Elasticsearch + Logstash + Kibana +Redis +Filebeat 单机版日志收集环境搭建
1.前置工作 1.虚拟机环境简介 Linux版本:Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:2 ...
- ELK+Kafka学习笔记之搭建ELK+Kafka日志收集系统集群
0x00 概述 关于如何搭建ELK部分,请参考这篇文章,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html. 该篇用户为非root,使用用 ...
- docker容器日志收集方案(方案一 filebeat+本地日志收集)
filebeat不用多说就是扫描本地磁盘日志文件,读取文件内容然后远程传输. docker容器日志默认记录方式为 json-file 就是将日志以json格式记录在磁盘上 格式如下: { " ...
- ELK+kafka日志收集分析系统
环境: 服务器IP 软件 版本 192.168.0.156 zookeeper+kafka zk:3.4.14 kafka:2.11-2.2.0 192.168.0.42 zookeeper+kaf ...
- ELK+Kafka日志收集环境搭建
1.搭建Elasticsearch环境并测试: (1)删除es的容器 (2)删除es的镜像 (3)宿主机调内存: 执行命令:sudo sysctl -w vm.max_map_count=655360 ...
- elk 日志收集 filebeat 集群搭建 php业务服务日志 nginx日志 json 7.12版本 ELK 解决方案
难的不是技术,难的是业务.熟悉业务流程才是最难的. 其实搜索进来的每一个人的需求不一样,希望你能从我的这篇文章里面收获到. 建议还是看官方文档,更全面一些. 一.背景 1,收集nginx acces ...
- 9.3 k8s结合ELK实现日志收集
数据流: logfile -> filebeat > kafka(依赖zookeeper)-> logstash -> elasticsearch -> kibana 1 ...
- docker容器日志收集方案汇总评价总结
docker日志收集方案有太多,下面截图罗列docker官方给的日志收集方案(详细请转docker官方文档).很多方案都不适合我们下面的系列文章没有说. 经过以下5篇博客的叙述简单说下docker容器 ...
随机推荐
- C++ STL stack 用法
Stack(栈)是一种后进先出的数据结构,也就是LIFO(last in first out) ,最后加入栈的元素将最先被取出来,在栈的同一端进行数据的插入与取出,这一段叫做“栈顶”. 使用STL的s ...
- Ping 命令实战小结--TCP/IP协议学习
2011-12-22 22:38:49 图1 图2 一,环境说明 硬件连线.PC与2440开发板直接用网线连接. PC的ip地址:192.168.0.107.2440开发板的ip地址:192.168. ...
- etcd v3 备份恢复
备份数据: # ETCDCTL_API=3 etcdctl --endpoints localhost:2379 snapshot save snapshot.db 恢复数据: # ETCDCTL_A ...
- WSDL文件
WSDL: <!--一次webservice调用,其实并不是方法调用,而是发送SOAP消息 ,即xml片段--> <!--以上一篇中的wsdl文档为例,这里我将注释写到文档中 --& ...
- Mask rcn nanchor部分理解
Anchors Mask 生成锚框本质与SSD一样中心点个数等于特征层像素数框体生成围绕中心点Bbox的坐标是要归一化到0~1之间的,都是相对于输入图片的大小.基本生成方式:H乘np.sqrt(anc ...
- The absolute uri: http://java.sun.com/jsp/jstl/core cannot be resolved in either web.xml or the jar files deployed with this application问题解决方案参考
错误信息:The absolute uri: http://java.sun.com/jsp/jstl/core cannot be resolved in either web.xml or the ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- gitlab 存储仓库目录设置及数据迁移
注:一开始没有考虑到把gitlab划分好存储目录,占用系统磁盘,由于gitlab是默认安装的,随着公司代码越来越多,导致gitlab数据目录空间不足 磁盘空间: [root@gitlab ~]# df ...
- HTML与CSS的一些知识(三)
CSS: 1.三大样式:行内(内嵌).内部(内联).外部(外联):基本都知道. 2.三大特性: a.继承性:父级样式会被子级继承(!important不会被继承,<a></a> ...
- Python线程模块threading
线程,程序执行的最小单元,单线程处理多个任务只能一个处理完后继续处理下一个直到全部处理完,多线程处理任务会比单线程处理起来快吗?在python程序里得看情况,首先有GIL锁的存在导致同一时刻只能有一个 ...