14.2-ELK 经典用法—企业自定义日志收集切割和mysql模块
本文收录在Linux运维企业架构实战系列
一、收集切割公司自定义的日志
很多公司的日志并不是和服务默认的日志格式一致,因此,就需要我们来进行切割了。
1、需切割的日志示例
2018-02-24 11:19:23,532 [143] DEBUG performanceTrace 1145 http://api.114995.com:8082/api/Carpool/QueryMatchRoutes 183.205.134.240 null 972533 310000 TITTL00 HUAWEI 860485038452951 3.1.146 HUAWEI 5.1 113.552344 33.332737 发送响应完成 Exception:(null)
2、切割的配置
在logstash 上,使用fifter 的grok 插件进行切割
input {
beats {
port => "5044"
}
}
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:timestamp} \[%{NUMBER:thread:int}\] %{DATA:level} (?<logger>[a-zA-Z]+) %{NUMBER:executeTime:int} %{URI:url} %{IP:clientip} %{USERNAME:UserName} %{NUMBER:userid:int} %{NUMBER:AreaCode:int} (?<Board>[0-9a-zA-Z]+[-]?[0-9a-zA-Z]+) (?<Brand>[0-9a-zA-Z]+[-]?[0-9a-zA-Z]+) %{NUMBER:DeviceId:int} (?<TerminalSourceVersion>[0-9a-z\.]+) %{NUMBER:Sdk:float} %{NUMBER:Lng:float} %{NUMBER:Lat:float} (?<Exception>.*)"
}
remove_field => "message"
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
geoip {
source => "clientip"
target => "geoip"
database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts => ["http://192.168.10.101:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "apache_logs"
}
}
3、切割解析后效果
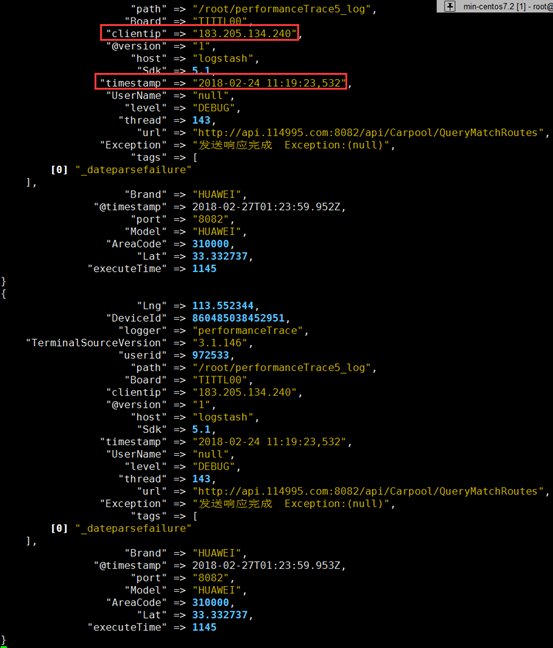
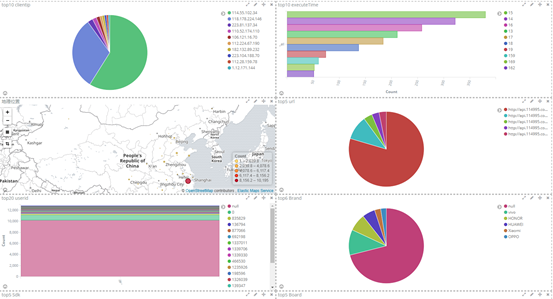
4、最终kibana 展示效果
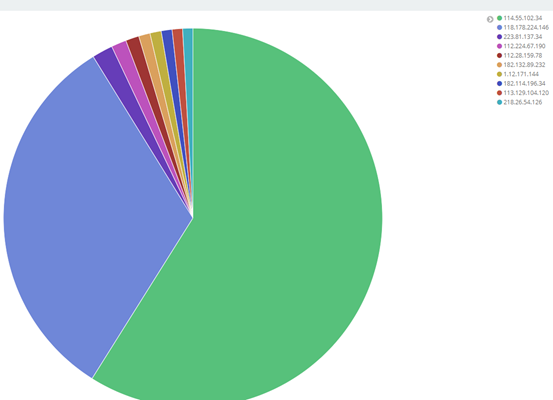
① top10 clientip
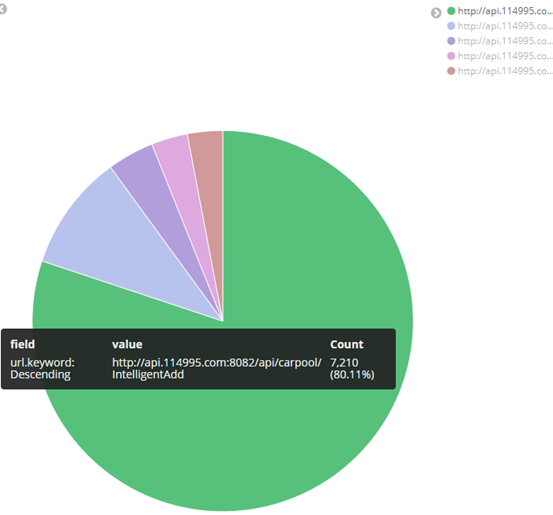
② top5 url
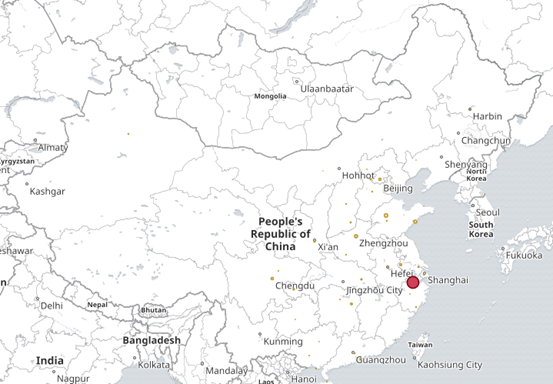
③ 根据ip 显示地理位置
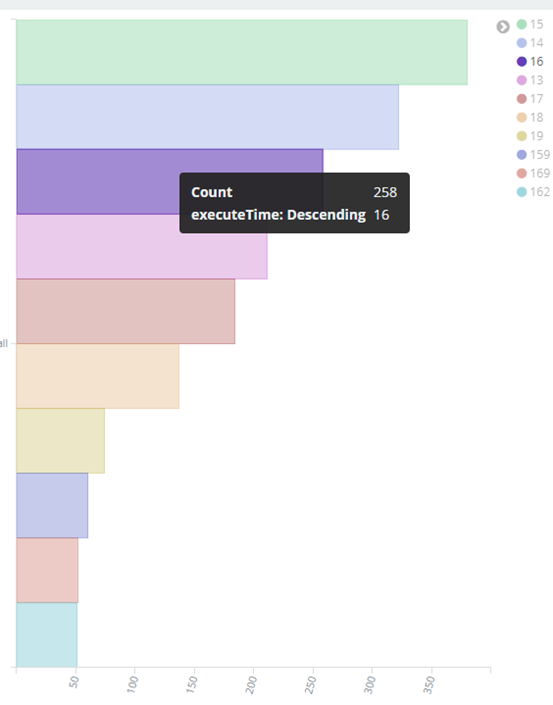
⑤ top10 executeTime
⑥ 其他字段都可进行设置,多种图案,也可将多个图形放在一起展示
二、grok 用法详解
1、简介
Grok是迄今为止使蹩脚的、无结构的日志结构化和可查询的最好方式。Grok在解析 syslog logs、apache and other webserver logs、mysql logs等任意格式的文件上表现完美。
Grok内置了120多种的正则表达式库,地址:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns。
2、入门例子
① 示例
55.3.244.1 GET /index.html 15824 0.043
② 分析
这条日志可切分为5个部分,IP(55.3.244.1)、方法(GET)、请求文件路径(/index.html)、字节数(15824)、访问时长(0.043),对这条日志的解析模式(正则表达式匹配)如下:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
③ 写到filter中
filter { grok { match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"} } }
④ 解析后效果
client: 55.3.244.1
method: GET
request: /index.html
bytes: 15824
duration: 0.043
3、解析任意格式日志
(1)解析任意格式日志的步骤:
① 先确定日志的切分原则,也就是一条日志切分成几个部分。
② 对每一块进行分析,如果Grok中正则满足需求,直接拿来用。如果Grok中没用现成的,采用自定义模式。
③ 学会在Grok Debugger中调试。
(2)grok 的分类
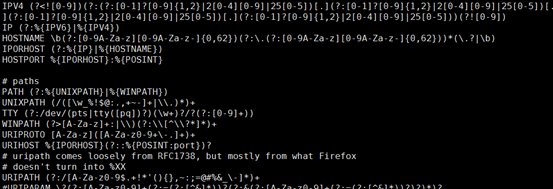
- 满足自带的grok 正则 grok_pattern
① 可以查询
# less /usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns/grok-patterns
② 使用格式
grok_pattern 由零个或多个 %{SYNTAX:SEMANTIC}组成
例: %{IP:clientip}
其中SYNTAX 是表达式的名字,是由grok提供的:例如数字表达式的名字是NUMBER,IP地址表达式的名字是IP
SEMANTIC 表示解析出来的这个字符的名字,由自己定义,例如IP字段的名字可以是 client
- 自定义SYNTAX
使用格式:(?<field_name>the pattern here)
例:(?<Board>[0-9a-zA-Z]+[-]?[0-9a-zA-Z]+)
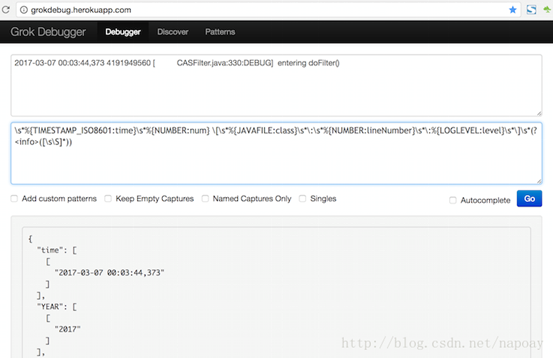
(3)正则解析容易出错,强烈建议使用Grok Debugger调试,姿势如下(我打开这个网页不能用)
三、使用mysql 模块,收集mysql 日志
1、官方文档使用介绍
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-mysql.html
2、配置filebeat ,使用mysql 模块收集mysql 的慢查询
# vim filebeat.yml
#=========================== Filebeat prospectors =============================
filebeat.modules:
- module: mysql
error:
enabled: true
var.paths: ["/var/log/mariadb/mariadb.log"] slowlog:
enabled: true
var.paths: ["/var/log/mariadb/mysql-slow.log"]
#----------------------------- Redis output --------------------------------
output.redis:
hosts: ["192.168.10.102"]
password: "ilinux.io"
key: "httpdlogs"
datatype: "list"
db: 0
timeout: 5
3、elk—logstash 切割mysql 的慢查询日志
① 切割配置
# vim mysqllogs.conf
input {
redis {
host => "192.168.10.102"
port => "6379"
password => "ilinux.io"
data_type => "list"
key => "httpdlogs"
threads => 2
}
}
filter {
if [fields][type] == "pachongmysql" {
grok {
match => {
"message" => "^#\ Time:\ (?<Time>.*)"
}
match => {
"message" => "^#\ User\@Host:\ (?<User>.*)\[exiuapp\]\ \@\ \ \[%{IP:hostip}\]\ \ Id:\ \ \ \ %{NUMBER:Id:int}"
}
match => {
"message" => "^#\ Query_time:\ %{NUMBER:Query_time:float}\ \ Lock_time:\ %{NUMBER:Lock_time:float}\ Rows_sent:\ %{NUMBER:Rows_sent:int}\ \ Rows_examined:\ %{NUMBER:Rows_examined:int}"
}
match => {
"message" => "^use\ (?<database>.*)"
}
match => {
"message" => "^SET\ timestamp=%{NUMBER:timestamp:int}\;"
}
match => {
"message" => "(?<sql>.*);"
}
remove_field => "message"
}
}
}
output {
elasticsearch {
hosts => ["http://192.168.10.101:9200/"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "mysql_logs"
}
}
② 切割后显示结果
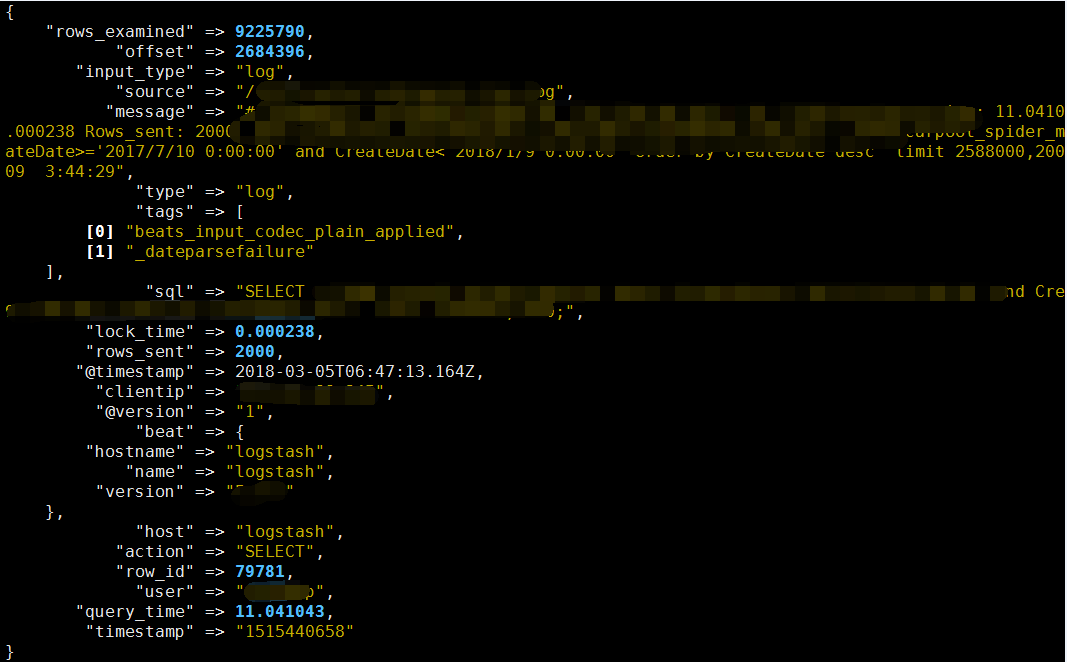
4、kibana 最终显示效果
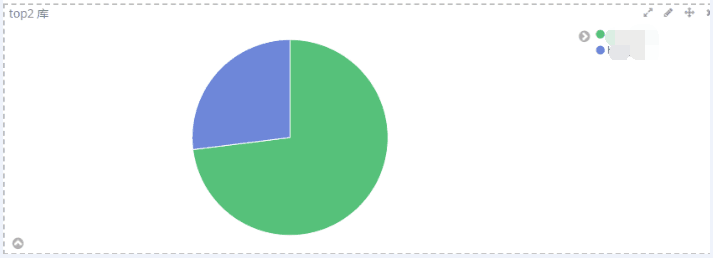
① 哪几个的数据库最多,例:top2 库
表无法显示,因为有些语句不涉及表,切割不出来
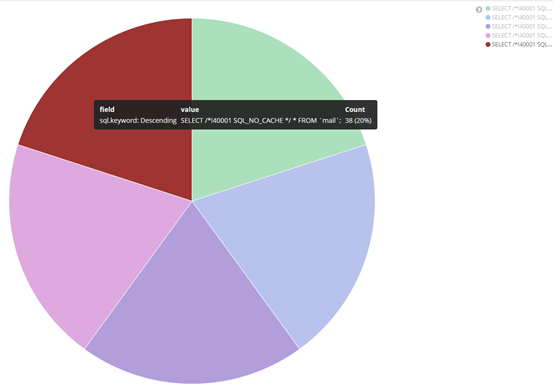
② 哪几个sql语句出现的最多,例:top5 sql语句
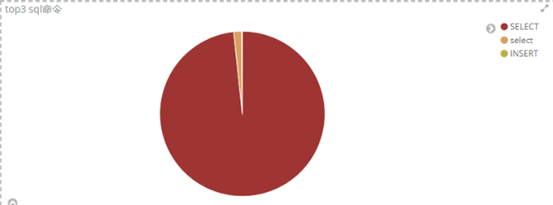
③ 哪几个sql语句出现的最多,例:top5 sql语句
④ 哪几台服务器慢查询日志生成的最多,例:top5 服务器
⑤ 哪几个用户慢查询日志生成的最多,例:top2 用户
可以合并显示
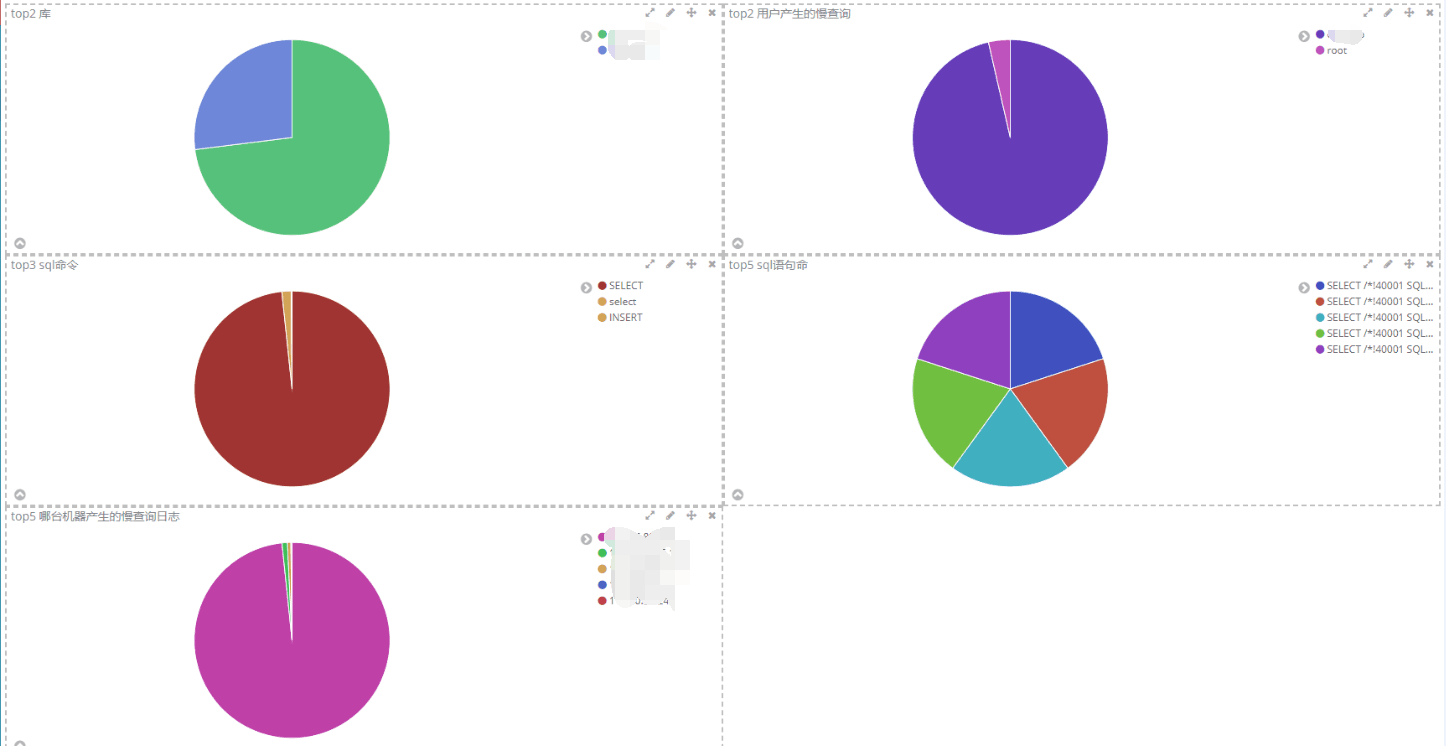
5、使用mysql 模块收集mysql 的慢查询
(1)filebeat 配置和上边一样
(2)elk—logstash 切割mysql 的错误日志
# vim mysqllogs.conf
filter {
grok {
match => { "message" => "(?<timestamp>\d{4}-\d{2}-\d{2}\s+\d{2}:\d{2}:\d{2}) %{NUMBER:pid:int} \[%{DATA:level}\] (?<content>.*)" }
}
date {
match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
remove_field => "timestamp"
}
}
(3)就不在展示结果了
四、ELK 收集多实例日志
很多情况下,公司资金不足,不会一对一收集日志;因此,一台logstash 使用多实例收集处理多台agent 的日志很有必要。
1、filebeat 的配置
主要是output 的配置,只需不同agent 指向不同的端口即可
① agent 1 配置指向5044 端口
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.10.107:5044"]
② agent 2 配置指向5045 端口
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.10.107:5045"]
2、logstash 的配置
针对不同的agent ,input 指定对应的端口
① agent 1
input {
beats {
port => "5044"
}
}
output { #可以在output 加以区分
elasticsearch {
hosts => ["http://192.168.10.107:9200/"]
index => "logstash-apache1-%{+YYYY.MM.dd}"
document_type => "apache1_logs"
}
}
② agent 1
input {
beats {
port => "5045"
}
}
output { #可以在output 加以区分
elasticsearch {
hosts => ["http://192.168.10.107:9200/"]
index => "logstash-apache2-%{+YYYY.MM.dd}"
document_type => "apache2_logs"
}
}
开启对应的服务就ok 了。
转自https://www.cnblogs.com/along21/
14.2-ELK 经典用法—企业自定义日志收集切割和mysql模块的更多相关文章
- ELK 经典用法—企业自定义日志收集切割和mysql模块
本文收录在Linux运维企业架构实战系列 一.收集切割公司自定义的日志 很多公司的日志并不是和服务默认的日志格式一致,因此,就需要我们来进行切割了. 1.需切割的日志示例 2018-02-24 11: ...
- ELK 经典用法—企业自定义日志手机切割和mysql模块
本文收录在Linux运维企业架构实战系列 一.收集切割公司自定义的日志 很多公司的日志并不是和服务默认的日志格式一致,因此,就需要我们来进行切割了. 1.需切割的日志示例 2018-02-24 11: ...
- ELK 6安装配置 nginx日志收集 kabana汉化
#ELK 6安装配置 nginx日志收集 kabana汉化 #环境 centos 7.4 ,ELK 6 ,单节点 #服务端 Logstash 收集,过滤 Elasticsearch 存储,索引日志 K ...
- 利用ELK构建一个小型的日志收集平台
利用ELK构建一个小型日志收集平台 伴随着应用以及集群的扩展,查看日志的方式总是不方便,我们希望可以有一个便于我们查询及提醒功能的平台:那么首先需要剖析有几步呢? 格式定义 --> 日志收集 - ...
- 项目实战14—ELK 企业内部日志分析系统
一.els.elk 的介绍 1.els,elk els:ElasticSearch,Logstash,Kibana,Beats elk:ElasticSearch,Logstash,Kibana ① ...
- 项目实战14.1—ELK 企业内部日志分析系统
本文收录在Linux运维企业架构实战系列 一.els.elk 的介绍 1.els,elk els:ElasticSearch,Logstash,Kibana,Beats elk:ElasticSear ...
- 日志收集系统ELK搭建
一.ELK简介 在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下.因此我们需要集中化的管理 ...
- 【Spring Cloud & Alibaba全栈开源项目实战】:SpringBoot整合ELK实现分布式登录日志收集和统计
一. 前言 其实早前就想计划出这篇文章,但是最近主要精力在完善微服务.系统权限设计.微信小程序和管理前端的功能,不过好在有群里小伙伴的一起帮忙反馈问题,基础版的功能已经差不多,也在此谢过,希望今后大家 ...
- kubernets轻量 contain log 日志收集技巧
首先这里要收集的日志是容器的日志,而不是集群状态的日志 要完成的三个点,收集,监控,报警,收集是基础,监控和报警可以基于收集的日志来作,这篇主要实现收集 不想看字的可以直接看代码,一共没几行,尽量用调 ...
随机推荐
- Helvetic Coding Contest 2016 online mirror D1
Description "The zombies are lurking outside. Waiting. Moaning. And when they come..." &qu ...
- Shell编程中的条件判断(条件测试)
Shell中的条件判断(测试)类型: 1) 整数测试 2) 字符测试 3) 文件测试 条件测试的表达式: (注: expression 与 [] 之间空格不能省略) [ expressi ...
- 使用tortoise git将一个现有项目推送到远程仓库
一.安装文件: 1.git https://git-scm.com/downloads 2.tortoise git https://tortoisegit.org/download/ 二.将一个现有 ...
- Flume NG部署
本次配置单节点的Flume NG 1.下载flume安装包 下载地址:(http://flume.apache.org/download.html) apache-flume-1.6.0-bin.ta ...
- 《从0到1学习Flink》—— Flink 中几种 Time 详解
前言 Flink 在流程序中支持不同的 Time 概念,就比如有 Processing Time.Event Time 和 Ingestion Time. 下面我们一起来看看这几个 Time: Pro ...
- FormsAuthentication IsAuthenticated一直为false
解决办法: 在Web.Config中添加一下红框的内容
- 洛谷P1397 [NOI2013]矩阵游戏(十进制矩阵快速幂)
题意 题目链接 Sol 感觉做这题只要对矩阵乘法理解的稍微一点就能做出来对于每一行构造一个矩阵A = a 1 0 b列与列之间的矩阵为B = c 1 0 d最终答案为$A^{n - ...
- thinkphp简易搜索
需求: 用户输入关键词,选项卡的每个选项输出一个分类的列表内容,分类有文章.ppt.学习. 实现过程: 视图中用户输入的关键词post给控制器,控制器对这个关键词做三次模糊查询处理,因为是三个分类对应 ...
- pure响应式布局
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- [转]c语言宏定义#define的理解与资料整理
原文地址:http://www.cnblogs.com/haore147/p/3646934.html 1. 利用define来定义 数值宏常量 #define 宏定义是个演技非常高超的替身演员,但也 ...