【原创】大数据基础之Kudu(6)kudu tserver内存占用统计分析
kudu tserver占用内存过高后会拒绝部分写请求,日志如下:
19/06/01 13:34:12 INFO AsyncKuduClient: Invalidating location 34b1c13d04664cc8bae6689d39b08b77($kudu_tserver:7050) for tablet 858c055c456549569af77d14eaf997e5: Service unavailable: Soft memory limit exceeded (at 92.36% of capacity). See https://kudu.apache.org/releases/1.7.0-cdh5.16.1/docs/troubleshooting.html
1 查看tserver内存详细占用
http://$kudu_tserver:8050/mem-trackers
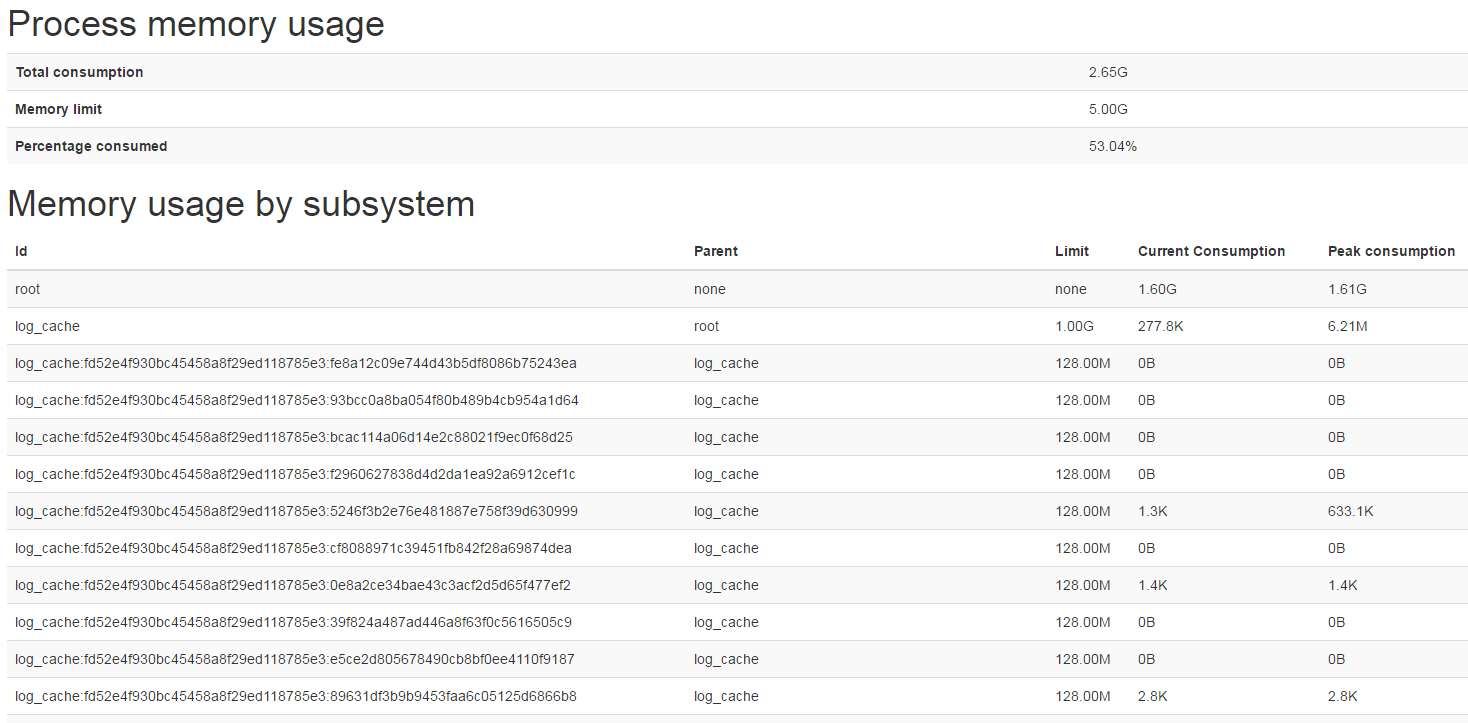
页面分为两个部分:
Process memory usage 为总体占用
Memory usage by subsystem为详细占比,其中乍看比较繁琐,其实是一个树形结构,通过parent来进行级联,
比如root是全部占用为1.6G,root下面logcache占用了277K,再往下看
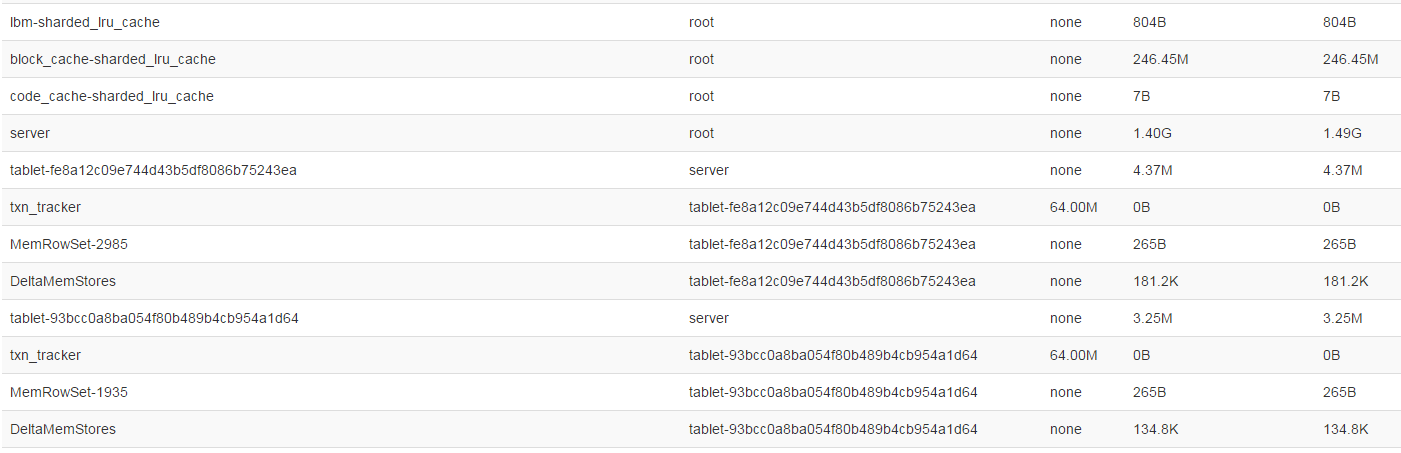
block_cache-sharded_lru_cache占用246M,server占用1.4G,server下面又分为很多个tablet,除了tablet之外,还有

log_block_manager占用438M;
如果发现某些tablet占用内存较多,想看下是在哪个table中,可以通过如下命令:
2 查看tserver上的所有tablet
sudo -u kudu kudu remote_replica list $kudu_tserver
比如:
Tablet id: e064f41775084680ab269b3cb3c21c76
State: RUNNING
Table name: impala::test_db.test_table1
Partition: RANGE (dt) PARTITION 20190531 <= VALUES < 20190532
Estimated on disk size: 30.71M
Schema: Schema [
0:co1[int32 NOT NULL],
1:co2[string NOT NULL],
2:co3[string NOT NULL],
3:co4[string NOT NULL],
4:co5[string NULLABLE]
]
...
关于kudu的内存估算,和数据量大小以及tablet多少以及活跃replica多少都有关系,详见:
https://kudu.apache.org/docs/scaling_guide.html#memory
【原创】大数据基础之Kudu(6)kudu tserver内存占用统计分析的更多相关文章
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Kudu(1)简介、安装、使用
kudu 1.7 官方:https://kudu.apache.org/ 一 简介 kudu有很多概念,有分布式文件系统(HDFS),有一致性算法(Zookeeper),有Table(Hive Tab ...
- 【原创】大数据基础之Kudu(5)kudu增加或删除目录/数据盘
kudu加减数据盘不能直接修改配置fs_data_dirs后重启,否则会报错: Check failed: _s.ok() Bad status: Already present: FS layout ...
- 【原创】大数据基础之Kudu(4)spark读写kudu
spark2.4.3+kudu1.9 1 批量读 val df = spark.read.format("kudu") .options(Map("kudu.master ...
- 【原创】大数据基础之Flume(2)应用之kafka-kudu
应用一:kafka数据同步到kudu 1 准备kafka topic # bin/kafka-topics.sh --zookeeper $zk:2181/kafka -create --topic ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Impala(2)实现细节
一 架构 Impala is a massively-parallel query execution engine, which runs on hundreds of machines in ex ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
随机推荐
- Matlab - Matlab 2016a 安装破解教程
https://blog.csdn.net/u012313335/article/details/73733651/ Matlab 2016a 安装包及破解教程百度云分享链接: 链接:https:// ...
- ycache中redis主备功能设计及使用说明
方案概述: 对于ycache-client,如下图,在一致性hash环上的每个节点都有一个备用的节点.正常情况下slave节点不参与key的分配(冷备).只有当master挂了,ycache clie ...
- mac 安装laravel
安装laravel之前先安装composer 使用 curl 指令下载: curl -sS https://getcomposer.org/installer | php 或是沒有安裝 curl ,也 ...
- bootstrp的datetimepicker插件获取选定日期
碰到一个日期选择,并将日期存储到数据库的需求,需要利用bootstrp的datetimepicker插件获取选定日期,并将其转换为指定字符窜,简单记录下实现的过程. 1. datetimepicker ...
- 解决MySQL5.7输入show databases 不显示内容的问题
当出现输入其他命令不显示内容的时候,请检查输入语句的后面是否带上了英文输入下的分号,同时别忘了database后面还有个s. 5. 删除数据库drop database XX(数据库名);
- 002-tomcat目录简介、应用部署【自动部署 ② 控制台部署 ③ 自定义部署】
一.目录及功能 主目录下有bin,conf,lib,logs,temp,webapps,work 7个文件夹 1.1.bin目录[重要] bin目录主要是用来存放tomcat的命令,主要有两大类,一类 ...
- .NET开发辅助工具-ANTS Performance Profiler【转载】
https://blog.csdn.net/Eye_cng/article/details/50274109
- JAVA 基础编程练习题8 【程序 8 输入数字求和】
8 [程序 8 输入数字求和] 题目:求 s=a+aa+aaa+aaaa+aa...a 的值,其中 a 是一个数字.例如 2+22+222+2222+22222(此时共有 5 个 数相加),几个数相加 ...
- JavaScript之参数传递方式
前言 nodejs项目中遇到此问题了,具体啥需求暂时不说~ 本博文,关于理论部分,主要是摘抄"推荐文献"第一篇:关于实验部分是看该博文之前做的,两者无干系. [结论]对于普通函数, ...
- hostname -i 出现0.0.0.0解决
[root@hostnametest4 ~]# hostname -i 0.0.0.0 原因:是因为四个节点中其中一个节点没有配置hosts解析,必须每个节点写全这四个ip,只要掉一个ip就会出现0. ...