pytorch识别CIFAR10:训练ResNet-34(准确率80%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处。联系方式:460356155@qq.com
CNN的层数越多,能够提取到的特征越丰富,但是简单地增加卷积层数,训练时会导致梯度弥散或梯度爆炸。
何凯明2015年提出了残差神经网络,即Reset,并在ILSVRC-2015的分类比赛中获得冠军。
ResNet可以有效的消除卷积层数增加带来的梯度弥散或梯度爆炸问题。
ResNet的核心思想是网络输出分为2部分恒等映射(identity mapping)、残差映射(residual mapping),即y = x + F(x),图示如下:

ResNet通过改变学习目标,即由学习完整的输出变为学习残差,解决了传统卷积在信息传递时存在的信息丢失核损耗问题,通过将输入直接绕道传递到输出,保护了信息的完整性。此外学习目标的简化也降低了学习难度。
常见的ResNet结构有:

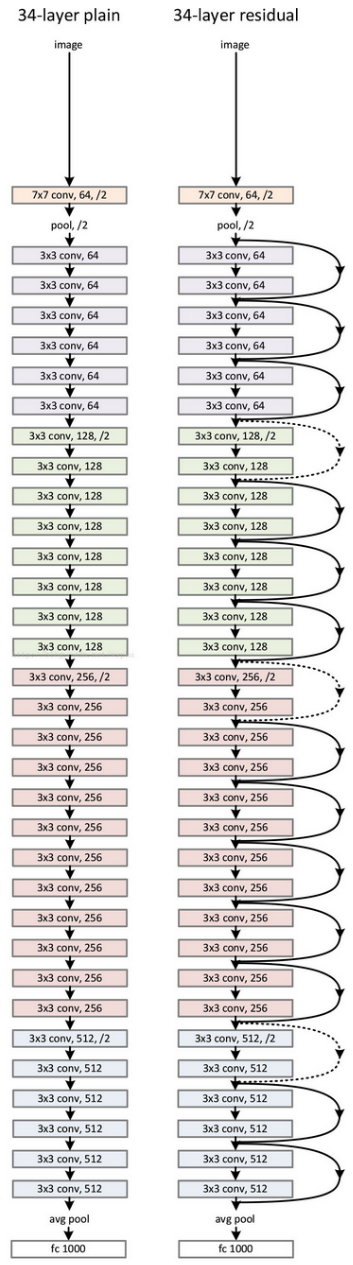
34层的ResNet图示如下:
pytorch实现核训练ResNet-34的代码如下:
# -*- coding:utf-8 -*- u"""ResNet训练学习CIFAR10""" __author__ = 'zhengbiqing 460356155@qq.com' import torch as t
import torchvision as tv
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
import torch.backends.cudnn as cudnn import matplotlib.pyplot as plt import datetime
import argparse # 样本读取线程数
WORKERS = 4 # 网络参赛保存文件名
PARAS_FN = 'cifar_resnet_params.pkl' # minist数据存放位置
ROOT = '/home/zbq/PycharmProjects/cifar' # 目标函数
loss_func = nn.CrossEntropyLoss() # 最优结果
best_acc = 0 # 记录准确率,显示曲线
global_train_acc = []
global_test_acc = [] '''
残差块
in_channels, out_channels:残差块的输入、输出通道数
对第一层,in out channel都是64,其他层则不同
对每一层,如果in out channel不同, stride是1,其他层则为2
'''
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResBlock, self).__init__() # 残差块的第一个卷积
# 通道数变换in->out,每一层(除第一层外)的第一个block
# 图片尺寸变换:stride=2时,w-3+2 / 2 + 1 = w/2,w/2 * w/2
# stride=1时尺寸不变,w-3+2 / 1 + 1 = w
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True) # 残差块的第二个卷积
# 通道数、图片尺寸均不变
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels) # 残差块的shortcut
# 如果残差块的输入输出通道数不同,则需要变换通道数及图片尺寸,以和residual部分相加
# 输出:通道数*2 图片尺寸/2
if in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2),
nn.BatchNorm2d(out_channels)
)
else:
# 通道数相同,无需做变换,在forward中identity = x
self.downsample = None def forward(self, x):
identity = x out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out) out = self.conv2(out)
out = self.bn2(out) if self.downsample is not None:
identity = self.downsample(x) out += identity
out = self.relu(out) return out '''
定义网络结构
'''
class ResNet34(nn.Module):
def __init__(self, block):
super(ResNet34, self).__init__() # 初始卷积层核池化层
self.first = nn.Sequential(
# 卷基层1:7*7kernel,2stride,3padding,outmap:32-7+2*3 / 2 + 1,16*16
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True), # 最大池化,3*3kernel,1stride(32的原始输入图片较小,不再缩小尺寸),1padding,
# outmap:16-3+2*1 / 1 + 1,16*16
nn.MaxPool2d(3, 1, 1)
) # 第一层,通道数不变
self.layer1 = self.make_layer(block, 64, 64, 3, 1) # 第2、3、4层,通道数*2,图片尺寸/2
self.layer2 = self.make_layer(block, 64, 128, 4, 2) # 输出8*8
self.layer3 = self.make_layer(block, 128, 256, 6, 2) # 输出4*4
self.layer4 = self.make_layer(block, 256, 512, 3, 2) # 输出2*2 self.avg_pool = nn.AvgPool2d(2) # 输出512*1
self.fc = nn.Linear(512, 10) def make_layer(self, block, in_channels, out_channels, block_num, stride):
layers = [] # 每一层的第一个block,通道数可能不同
layers.append(block(in_channels, out_channels, stride)) # 每一层的其他block,通道数不变,图片尺寸不变
for i in range(block_num - 1):
layers.append(block(out_channels, out_channels, 1)) return nn.Sequential(*layers) def forward(self, x):
x = self.first(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x) # x.size()[0]: batch size
x = x.view(x.size()[0], -1)
x = self.fc(x) return x '''
训练并测试网络
net:网络模型
train_data_load:训练数据集
optimizer:优化器
epoch:第几次训练迭代
log_interval:训练过程中损失函数值和准确率的打印频率
'''
def net_train(net, train_data_load, optimizer, epoch, log_interval):
net.train() begin = datetime.datetime.now() # 样本总数
total = len(train_data_load.dataset) # 样本批次训练的损失函数值的和
train_loss = 0 # 识别正确的样本数
ok = 0 for i, data in enumerate(train_data_load, 0):
img, label = data
img, label = img.cuda(), label.cuda() optimizer.zero_grad() outs = net(img)
loss = loss_func(outs, label)
loss.backward()
optimizer.step() # 累加损失值和训练样本数
train_loss += loss.item() _, predicted = t.max(outs.data, 1)
# 累加识别正确的样本数
ok += (predicted == label).sum() if (i + 1) % log_interval == 0:
# 训练结果输出 # 已训练的样本数
traind_total = (i + 1) * len(label) # 准确度
acc = 100. * ok / traind_total # 记录训练准确率以输出变化曲线
global_train_acc.append(acc) end = datetime.datetime.now()
print('one epoch spend: ', end - begin) '''
用测试集检查准确率
'''
def net_test(net, test_data_load, epoch):
net.eval() ok = 0 for i, data in enumerate(test_data_load):
img, label = data
img, label = img.cuda(), label.cuda() outs = net(img)
_, pre = t.max(outs.data, 1)
ok += (pre == label).sum() acc = ok.item() * 100. / (len(test_data_load.dataset))
print('EPOCH:{}, ACC:{}\n'.format(epoch, acc)) # 记录测试准确率以输出变化曲线
global_test_acc.append(acc) # 最好准确度记录
global best_acc
if acc > best_acc:
best_acc = acc '''
显示数据集中一个图片
'''
def img_show(dataset, index):
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck') show = ToPILImage() data, label = dataset[index]
print('img is a ', classes[label])
show((data + 1) / 2).resize((100, 100)).show() '''
显示训练准确率、测试准确率变化曲线
'''
def show_acc_curv(ratio):
# 训练准确率曲线的x、y
train_x = list(range(len(global_train_acc)))
train_y = global_train_acc # 测试准确率曲线的x、y
# 每ratio个训练准确率对应一个测试准确率
test_x = train_x[ratio-1::ratio]
test_y = global_test_acc plt.title('CIFAR10 RESNET34 ACC') plt.plot(train_x, train_y, color='green', label='training accuracy')
plt.plot(test_x, test_y, color='red', label='testing accuracy') # 显示图例
plt.legend()
plt.xlabel('iterations')
plt.ylabel('accs') plt.show() def main():
# 训练超参数设置,可通过命令行设置
parser = argparse.ArgumentParser(description='PyTorch CIFA10 ResNet34 Example')
parser.add_argument('--batch-size', type=int, default=128, metavar='N',
help='input batch size for training (default: 128)')
parser.add_argument('--test-batch-size', type=int, default=100, metavar='N',
help='input batch size for testing (default: 100)')
parser.add_argument('--epochs', type=int, default=200, metavar='N',
help='number of epochs to train (default: 200)')
parser.add_argument('--lr', type=float, default=0.1, metavar='LR',
help='learning rate (default: 0.1)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M',
help='SGD momentum (default: 0.9)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status (default: 10)')
parser.add_argument('--no-train', action='store_true', default=False,
help='If train the Model')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args() # 图像数值转换,ToTensor源码注释
"""Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor.
Converts a PIL Image or numpy.ndarray (H x W x C) in the range
[0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0].
"""
# 归一化把[0.0, 1.0]变换为[-1,1], ([0, 1] - 0.5) / 0.5 = [-1, 1]
transform = tv.transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) # 定义数据集
train_data = tv.datasets.CIFAR10(root=ROOT, train=True, download=True, transform=transform)
test_data = tv.datasets.CIFAR10(root=ROOT, train=False, download=False, transform=transform) train_load = t.utils.data.DataLoader(train_data, batch_size=args.batch_size, shuffle=True, num_workers=WORKERS)
test_load = t.utils.data.DataLoader(test_data, batch_size=args.test_batch_size, shuffle=False, num_workers=WORKERS) net = ResNet34(ResBlock).cuda()
print(net) # 并行计算提高运行速度
net = nn.DataParallel(net)
cudnn.benchmark = True # 如果不训练,直接加载保存的网络参数进行测试集验证
if args.no_train:
net.load_state_dict(t.load(PARAS_FN))
net_test(net, test_load, 0)
return optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum) start_time = datetime.datetime.now() for epoch in range(1, args.epochs + 1):
net_train(net, train_load, optimizer, epoch, args.log_interval) # 每个epoch结束后用测试集检查识别准确度
net_test(net, test_load, epoch) end_time = datetime.datetime.now() global best_acc
print('CIFAR10 pytorch ResNet34 Train: EPOCH:{}, BATCH_SZ:{}, LR:{}, ACC:{}'.format(args.epochs, args.batch_size, args.lr, best_acc))
print('train spend time: ', end_time - start_time) # 每训练一个迭代记录的训练准确率个数
ratio = len(train_data) / args.batch_size / args.log_interval
ratio = int(ratio) # 显示曲线
show_acc_curv(ratio) if args.save_model:
t.save(net.state_dict(), PARAS_FN) if __name__ == '__main__':
main()
运行结果:
Files already downloaded and verified
ResNet34(
(first): Sequential(
(0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
)
(layer1): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): ResBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): ResBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
(fc): Linear(in_features=512, out_features=10, bias=True)
)
one epoch spend: 0:00:23.971338
EPOCH:1, ACC:48.54
one epoch spend: 0:00:22.339190
EPOCH:2, ACC:61.06
......
one epoch spend: 0:00:22.023034
EPOCH:199, ACC:79.84
one epoch spend: 0:00:22.057692
EPOCH:200, ACC:79.6
CIFAR10 pytorch ResNet34 Train: EPOCH:200, BATCH_SZ:128, LR:0.1, ACC:80.19
train spend time: 1:18:40.948080
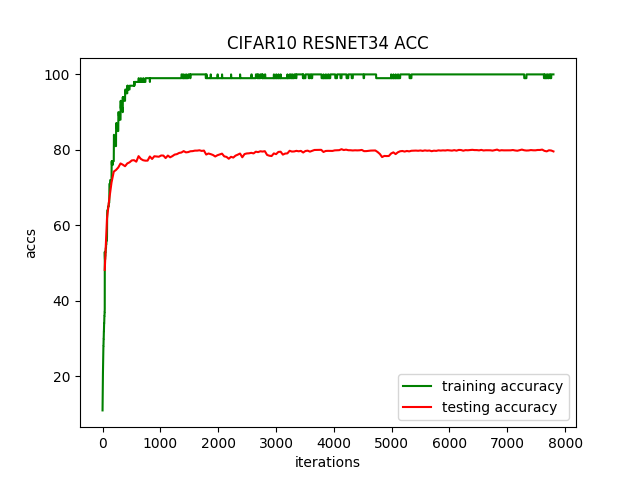
运行200个迭代,每个迭代耗时22秒,准确率不高,只有80%。准确率变化曲线如下:
pytorch识别CIFAR10:训练ResNet-34(准确率80%)的更多相关文章
- pytorch识别CIFAR10:训练ResNet-34(自定义transform,动态调整学习率,准确率提升到94.33%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 前面通过数据增强,ResNet-34残差网络识别CIFAR10,准确率达到了92.6. 这里对训练过程 ...
- pytorch识别CIFAR10:训练ResNet-34(微调网络,准确率提升到85%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过训练准确率只达到80%. 这里对网络做点小修改,在最开始的 ...
- pytorch识别CIFAR10:训练ResNet-34(数据增强,准确率提升到92.6%)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前一篇中的ResNet-34残差网络,经过减小卷积核训练准确率提升到85%. 这里对训练数据集做数据 ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(二)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com AlexNet在2012年ImageNet图像分类任务竞赛中获得冠军.网络结构如下图所示: 对CIFA ...
- 深度学习识别CIFAR10:pytorch训练LeNet、AlexNet、VGG19实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com VGGNet在2014年ImageNet图像分类任务竞赛中有出色的表现.网络结构如下图所示: 同样的, ...
- PyTorch Tutorials 4 训练一个分类器
%matplotlib inline 训练一个分类器 上一讲中已经看到如何去定义一个神经网络,计算损失值和更新网络的权重. 你现在可能在想下一步. 关于数据? 一般情况下处理图像.文本.音频和视频数据 ...
- 【转】CNN+BLSTM+CTC的验证码识别从训练到部署
[转]CNN+BLSTM+CTC的验证码识别从训练到部署 转载地址:https://www.jianshu.com/p/80ef04b16efc 项目地址:https://github.com/ker ...
- Pytorch使用分布式训练,单机多卡
pytorch的并行分为模型并行.数据并行 左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练. 右侧数据并行:多个显卡同时采用数据训练网络的副本. 一.模型并行 二.数据并行 数 ...
- Pytorch多GPU训练
Pytorch多GPU训练 临近放假, 服务器上的GPU好多空闲, 博主顺便研究了一下如何用多卡同时训练 原理 多卡训练的基本过程 首先把模型加载到一个主设备 把模型只读复制到多个设备 把大的batc ...
随机推荐
- springboot~如何去掌握它(新手可以看看)
springboot~如何去掌握它 主讲:仓储大叔 每讲40分钟 架构图 graph LR App-->A Web-->A A(zuul proxy)-->B(eureka serv ...
- 初探Parcel
昨天趁有点时间看了前不久很火的构建工具Parcel,这里说下初步使用的感受,尤其是将其放到实际项目中和Webpack进行比较. 一.前言 首先说下笔者目前的技术栈.最近的前端项目主要以管理后台为主,技 ...
- NodeJs之邮件(email)发送
NodeJs之邮件(email)发送 一,介绍与需求 1.1,介绍 1,Nodemailer简介 Nodemailer是一个简单易用的Node.js邮件发送插件 github地址 Nodemailer ...
- python实现某目录下将多个文件夹内的文件复制到一个文件夹中
现实生活中,我们经常有这样的需求,如下图,有三个文件夹,文件夹1内含有1.txt文件 文件夹2中内含有2.txt文件,文件夹3中含有3.txt文件.我们有时候需要把1.txt, 2.txt, 3.tx ...
- MVC,EF 小小封装
1.项目中经常要用到 EF,有时候大多数的增删改查都是重复性的东西,本次封装就是为了快速开发,期间没有考虑到架构上的各种思想,就感觉到欠缺点什么东西所以这次将这些拉出来,有存在问题的话还请各位多多指导 ...
- ACM字符串输入问题
坑死了..竟然被这个问题困扰了大半个学期,今天搜来翻去终于弄明白了一些,以后固定用这几种用法好了不然总出错QAQ实际测试例子就没放了,死记这里就够用了T-T 概念: gets()函数:用来从标准输入设 ...
- 学JAVA第十二天,今天写java控制台输入流及String的类型转换
今天老师讲了一天狗跳楼的问题,昨天解开始说了,今天都没讲新课, 所以,今天自学了Scanner类及String的类型转换 先来Scanner类实现键盘输入功能: 代码: package pkg1; i ...
- mysql存储过程 带参数 插入 操作
今天再次添补一下小小内容,闲话不多说,直入标题. 先来看下,如何创建带参数的 存储过程(ps:本文只限mysql5及以上版本) CREATE PROCEDURE prSaveFileInfo(Tabl ...
- CSS中盒模型的理解
今天突然看到一篇关于CSS中盒模型的文章,忽然觉得自己竟然遗忘了很多小的地方,所以写一篇文章来记忆一下 (摘抄于千与千寻写的CSS盒子模型理解,并在自己基础上添加了一些东西,希望更完善,对大家有帮助) ...
- SSH实现登陆拦截器
/** * 登录验证拦截器 * */ @SuppressWarnings("serial") public class LoginInteceptor implements Int ...