Batch Normalization&Dropout浅析
一. Batch Normalization
对于深度神经网络,训练起来有时很难拟合,可以使用更先进的优化算法,例如:SGD+momentum、RMSProp、Adam等算法。另一种策略则是高改变网络的结构,使其更加容易训练。Batch Normalization就是这个思想。
为什么要做Normalization?
神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低;另外一方面,一旦每批训练数据的分布各不相同(batch梯度下降),那么网络就要在每次迭代都去学习适应不同的分布,这样将会大大降低网络的训练速度。
机器学习方法在输入数据为0均值和单位方差的不相关特征时效果更好,所以在我们训练网络的时候,可以人为与处理数据,使其满足这样的分布。然而即使我们在输入端处理好数据,经过更深层次的非线性激活后,数据可能不再是不相关的,也不是0均值单位方差了,这样对于后面网络层的拟合就造成了困难。更糟糕的是,在训练过程中,每个层的特征分布随着每一层的权重更新而改变。
深度神经网络中的特征分布变化会使神网络的训练变得更加困难,为了克服这种问题,在网络中加入Batch Normalization层。在训练时,BN层计算批数据每个特征的均值和标准差。这些均值和标准差的平均值在训练期间被记录下来,在测试阶段,使用这些信息进行标准化测试集特征。
实现方法:

代码实现:
def batchnorm_forward(x, gamma, beta, bn_param):
"""
Forward pass for batch normalization.
During training the sample mean and (uncorrected) sample variance are
computed from minibatch statistics and used to normalize the incoming data.
During training we also keep an exponentially decaying running mean of the
mean and variance of each feature, and these averages are used to normalize
data at test-time.
At each timestep we update the running averages for mean and variance using
an exponential decay based on the momentum parameter:
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
Note that the batch normalization paper suggests a different test-time
behavior: they compute sample mean and variance for each feature using a
large number of training images rather than using a running average. For
this implementation we have chosen to use running averages instead since
they do not require an additional estimation step; the torch7
implementation of batch normalization also uses running averages.
Input:
- x: Data of shape (N, D)
- gamma: Scale parameter of shape (D,)
- beta: Shift paremeter of shape (D,)
- bn_param: Dictionary with the following keys:
- mode: 'train' or 'test'; required
- eps: Constant for numeric stability
- momentum: Constant for running mean / variance.
- running_mean: Array of shape (D,) giving running mean of features
- running_var Array of shape (D,) giving running variance of features
Returns a tuple of:
- out: of shape (N, D)
- cache: A tuple of values needed in the backward pass
"""
mode = bn_param['mode']
eps = bn_param.get('eps', 1e-5)
momentum = bn_param.get('momentum', 0.9)
N, D = x.shape
running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))
running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))
out, cache = None, None
if mode == 'train':
#######################################################################
# TODO: Implement the training-time forward pass for batch norm. #
# Use minibatch statistics to compute the mean and variance, use #
# these statistics to normalize the incoming data, and scale and #
# shift the normalized data using gamma and beta. #
# #
# You should store the output in the variable out. Any intermediates #
# that you need for the backward pass should be stored in the cache #
# variable. #
# #
# You should also use your computed sample mean and variance together #
# with the momentum variable to update the running mean and running #
# variance, storing your result in the running_mean and running_var #
# variables. #
#######################################################################
sample_mean = x.mean(axis = 0)
sample_var = x.var(axis = 0)
x_hat = (x-sample_mean)/(np.sqrt(sample_var+eps))
out = gamma*x_hat+beta
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
#cache = (x,gamma,beta)
cache = (gamma, x, sample_mean, sample_var, eps, x_hat)
#######################################################################
# END OF YOUR CODE #
#######################################################################
elif mode == 'test':
#######################################################################
# TODO: Implement the test-time forward pass for batch normalization. #
# Use the running mean and variance to normalize the incoming data, #
# then scale and shift the normalized data using gamma and beta. #
# Store the result in the out variable. #
#######################################################################
x_h = (x-bn_param["running_mean"])/(np.sqrt(bn_param["running_var"]+eps))
out = gamma*x_h+beta
#######################################################################
# END OF YOUR CODE #
#######################################################################
else:
raise ValueError('Invalid forward batchnorm mode "%s"' % mode)
# Store the updated running means back into bn_param
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return out, cache
def batchnorm_backward(dout, cache):
"""
Backward pass for batch normalization.
For this implementation, you should write out a computation graph for
batch normalization on paper and propagate gradients backward through
intermediate nodes.
Inputs:
- dout: Upstream derivatives, of shape (N, D)
- cache: Variable of intermediates from batchnorm_forward.
Returns a tuple of:
- dx: Gradient with respect to inputs x, of shape (N, D)
- dgamma: Gradient with respect to scale parameter gamma, of shape (D,)
- dbeta: Gradient with respect to shift parameter beta, of shape (D,)
"""
dx, dgamma, dbeta = None, None, None
###########################################################################
# TODO: Implement the backward pass for batch normalization. Store the #
# results in the dx, dgamma, and dbeta variables. #
###########################################################################
gamma, x, sample_mean, sample_var, eps, x_hat = cache
N = x.shape[0]
D = x.shape[1]
dgamma = np.sum(dout * x_hat,axis = 0)#(D,)
dbeta = dout.sum(axis = 0)#(D,)
dx_hat = dout * gamma#(N,D)
std = np.sqrt(sample_var.reshape(1,D) + eps)#(1,D)
dx = dx_hat / std#(N,D)
dstd = np.sum(-dx_hat*(x_hat/std),axis = 0).reshape(1,D)#(1,D)
dm = np.sum(-dx_hat / std,axis = 0).reshape(1,D)#(1,D)
dvar = dstd/(2*std)#(1,D)
dm += dvar*(-2/N)*((x-sample_mean).sum(axis = 0).reshape(1,D))#(1,D)
dx += dvar * (2/N)*(x-sample_mean)#(N,D)
dx += dm / N#(N,D)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dgamma, dbeta
二. Dropout
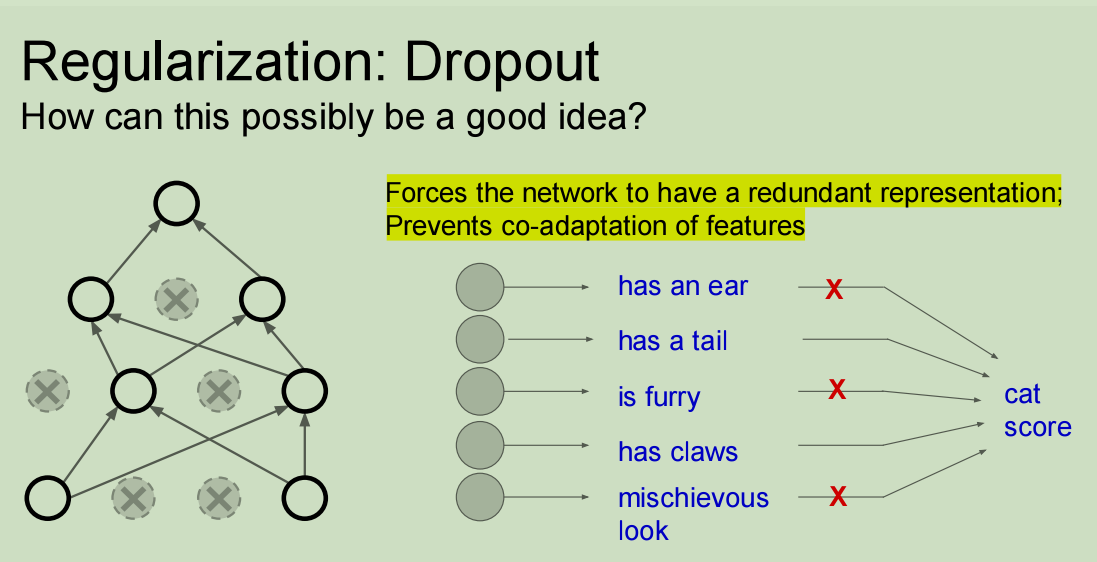
过拟合一直是深度神经网络(DNN)所要面临的一个问题:模型只是在训练数据上学习分类,使其适应训练样本,而不是去学习一个能够对通用数据进行分类的完全决策边界。这些年,提出了很多的方案去解决过拟合问题。其中一种方法就是Dropout,由于这种方法非常简单,但是在实际使用中又具有很好的效果,所以被广泛使用。
Dropout 背后的思想其实就是把DNN当做一个集成模型来训练,之后取所有值的平均值,而不只是训练单个DNN。
DNN网络将Dropout率设置为 p,也就是说,一个神经元被保留的概率是 1-p。当一个神经元被丢弃时,无论输入或者相关的参数是什么,它的输出值就会被设置为0。
丢弃的神经元在训练阶段,对BP算法的前向和后向阶段都没有贡献。因为这个原因,所以每一次训练,它都像是在训练一个新的网络。
简而言之:Dropout 可以在实际工作中发挥很好的效果,因为它能防止神经网络在训练过程中产生共适应。
实现方法:


代码实现1:

代码实现2:

- Inverted Dropout(Dropout 改进版)
优点:使得我们只需要在训练阶段缩放激活函数的输出值,而不用在测试阶段改变什么。
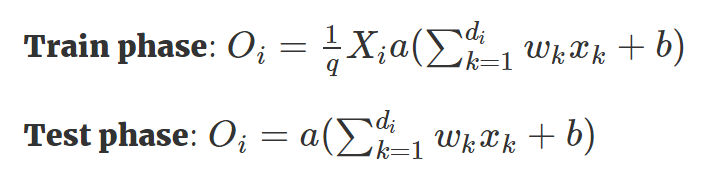
在各种深度学习框架的实现中,我们都是用 Inverted Dropout 来代替 Dropout,因为这种方式有助于模型的完整性,我们只需要修改一个参数(保留/丢弃概率),而整个模型都不用修改。
代码实现:
def dropout_forward(x, dropout_param):
"""
Performs the forward pass for (inverted) dropout.
Inputs:
- x: Input data, of any shape
- dropout_param: A dictionary with the following keys:
- p: Dropout parameter. We drop each neuron output with probability p.
- mode: 'test' or 'train'. If the mode is train, then perform dropout;
if the mode is test, then just return the input.
- seed: Seed for the random number generator. Passing seed makes this
function deterministic, which is needed for gradient checking but not
in real networks.
Outputs:
- out: Array of the same shape as x.
- cache: tuple (dropout_param, mask). In training mode, mask is the dropout
mask that was used to multiply the input; in test mode, mask is None.
"""
p, mode = dropout_param['p'], dropout_param['mode']
if 'seed' in dropout_param:
np.random.seed(dropout_param['seed'])
mask = None
out = None
if mode == 'train':
#######################################################################
# TODO: Implement training phase forward pass for inverted dropout. #
# Store the dropout mask in the mask variable. #
#######################################################################
#musk = np.random.rand(*x.shape) >= p
mask = (np.random.rand(*x.shape) >= p) / (1 - p)
out =x * mask
#######################################################################
# END OF YOUR CODE #
#######################################################################
elif mode == 'test':
#######################################################################
# TODO: Implement the test phase forward pass for inverted dropout. #
#######################################################################
out = x
#######################################################################
# END OF YOUR CODE #
#######################################################################
cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False)
return out, cache
def dropout_backward(dout, cache):
"""
Perform the backward pass for (inverted) dropout.
Inputs:
- dout: Upstream derivatives, of any shape
- cache: (dropout_param, mask) from dropout_forward.
"""
dropout_param, mask = cache
mode = dropout_param['mode']
dx = None
if mode == 'train':
#######################################################################
# TODO: Implement training phase backward pass for inverted dropout #
#######################################################################
dx = dout * mask
#######################################################################
# END OF YOUR CODE #
#######################################################################
elif mode == 'test':
dx = dout
return dx
Batch Normalization&Dropout浅析的更多相关文章
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- 【转载】 深度学习总结:用pytorch做dropout和Batch Normalization时需要注意的地方,用tensorflow做dropout和BN时需要注意的地方,
原文地址: https://blog.csdn.net/weixin_40759186/article/details/87547795 ------------------------------- ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 激活函数,Batch Normalization和Dropout
神经网络中还有一些激活函数,池化函数,正则化和归一化函数等.需要详细看看,啃一啃吧.. 1. 激活函数 1.1 激活函数作用 在生物的神经传导中,神经元接受多个神经的输入电位,当电位超过一定值时,该神 ...
- Feature Extractor[batch normalization]
1 - 背景 摘要:因为随着前面层的参数的改变会导致后面层得到的输入数据的分布也会不断地改变,从而训练dnn变得麻烦.那么通过降低学习率和小心地参数初始化又会减慢训练过程,而且会使得具有饱和非线性模型 ...
- 深度学习网络层之 Batch Normalization
Batch Normalization Ioffe 和 Szegedy 在2015年<Batch Normalization: Accelerating Deep Network Trainin ...
- 使用TensorFlow中的Batch Normalization
问题 训练神经网络是一个很复杂的过程,在前面提到了深度学习中常用的激活函数,例如ELU或者Relu的变体能够在开始训练的时候很大程度上减少梯度消失或者爆炸问题.但是却不能保证在训练过程中不出现该问题, ...
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
随机推荐
- linux_文件权限
权限贯穿linux整个系统 创建文件或目录,属主和组都是当前用户 linux权限位? 9位基础权限位, 3位一组,总共12位权限 用户对文件权限,相当于你的笔记本 r 读 4 w ...
- Django_xadmin_应用外键搜索功能错误
问题: 当我在给某一张表加上外键搜索的时候,会出现 TypeError: Related Field got invalid lookup: icontains 问题原因: a 表关联 b表,也就是说 ...
- python_7_列表
什么是列表? --一种数据类型 -- 形式:[值1,值2,[值a,值b],值3] --可以嵌套 #!/usr/bin/python3 list_a = [1, 2, [3, 'a']] 对于 ...
- strstr()与find()
- 基于Controller接口的控制器及简单应用
DispatcherServlet在Spring当中充当一个前端控制器的角色,它的核心功能是分发请求.请求会被分发给对应处理的Java类,Spring MVC中称为Handle.在Spring 2.5 ...
- 细数Python Flask微信公众号开发中遇到的那些坑
最近两三个月的时间,断断续续边学边做完成了一个微信公众号页面的开发工作.这是一个快递系统,主要功能有用户管理.寄收件地址管理.用户下单,订单管理,订单查询及一些宣传页面等.本文主要细数下开发过程中遇到 ...
- Django中模板的用法简介
1. 模板系统的介绍 Django作为一个Web框架,其模板所需的HTML输出静态部分以及动态内容插入 模板由HTML代码和逻辑控制代码构成 Django框架的模板语言的语法格式: {{var_nam ...
- CSS选择器之通配符选择器和多元素选择器
1.通配符选择器 如果希望所有的元素都符合某一种样式,可以使用通配符选择器. 基本语法: *{margin:0; padding:0} 可以让所有的html元素的外边距和内边距都默认为0. 写一段ht ...
- java重定向
package com.sn.servlet; import java.io.IOException; import javax.servlet.ServletException; import ja ...
- 弥补wxpython无背景图片缺陷
思路: 通过设置Panel的背景样式为wx.BG_STYLE_CUSTOM: self.SetBackgroundStyle(wx.BG_STYLE_CUSTOM) 绑定Panel的背景事情: sel ...