ML-L1、L2 正则化
出现过拟合时,使用正则化可以将模型的拟合程度降低一点点,使曲线变得缓和。
L1正则化(LASSO)
正则项是所有参数的绝对值的和。正则化不包含theta0,因为他只是偏置,而不影响曲线的摆动幅度。
\]
# 使用pipeline进行封装
from sklearn.linear_model import Lasso
# 使用管道封装lasso
def LassoRegssion(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree = degree)),
("std_scaler", StandardScaler()),
("lasso", Lasso(alpha=alpha))
])
使用\(\alpha=0.01\) 的正则化拟合20阶多项式
lasso_reg = LassoRegssion(20, 0.01)
lasso_reg.fit(X_train, y_train)
y_predict = lasso_reg.predict(X_test)
plot_model(lasso_reg)
MSE 1.149608084325997
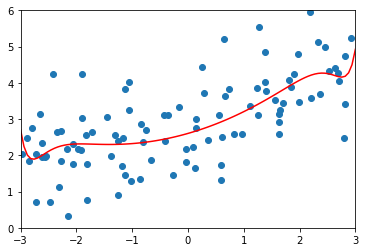
\(\alpha=0.1\)
MSE 1.1213911351818648

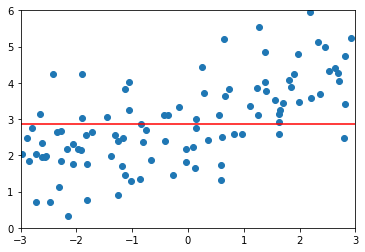
\(\alpha=1\) 时,均方误差又变大了,正则化过度了。模型变成了直线,所有参数都接近0了。因为没有对\(\theta_0\)进行正则化,所以偏置的值没有变化
1.8408939659515595
L2正则化(岭回归)
1/2可加可不加,因为方便求导。对J()求最小值时,也将\(\theta\)的值变小。当\(\alpha\)越大,右边受到的影响就越大,\(\theta\)的值就越小
\]
使用pipeline封装Ridge
from sklearn.linear_model import Ridge
# 使用管道封装岭回归
def RidgeRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree = degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha = alpha))
])
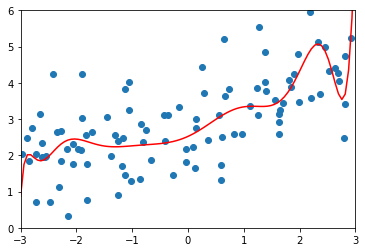
使用20阶多项式拟合,\(\alpha=0\)即没有正则化。
ridge_reg100 = RidgeRegression(20, 0)
ridge_reg100.fit(X_train, y_train)
y_predict = ridge_reg100.predict(X_test)
plot_model(ridge_reg100)
# MSE 167.94010860994555

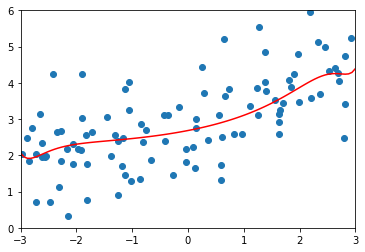
\(\alpha=0.0001\)
ridge_reg100 = RidgeRegression(20, 0.0001)
# MSE 1.3233492754136291
\(\alpha=10\)
ridge_reg100 = RidgeRegression(20, 10)
# MSE 1.1451272194878865
\(\alpha=1000\)
ridge_reg100 = RidgeRegression(20, 10000)
# MSE 1.7967435583384

对比
- LASSO更趋向于将一部分参数变为0,更容易得到直线。Ridge更容易得到曲线。
- \(\alpha\)越大,正则化的效果越明显
两个正则化的不同仅仅在于正则化项的不同:
\]
\]
常见的对比还有:
MSE 和 MAE :
\]
\]
欧拉距离和曼哈顿距离:
\]
还有明可夫斯基距离:
\]
弹性网(待定)
就是将两个范式进行结合。
\]
ML-L1、L2 正则化的更多相关文章
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- L1,L2正则化代码
# L1正则 import numpy as np from sklearn.linear_model import Lasso from sklearn.linear_model import SG ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
随机推荐
- java-修饰词、抽象类、抽象方法
1.final:最终的.不可改变的------单独应用的机率小 1)修饰变量:变量不能被改变 2)修饰方法:方法不能被重写 3)修饰类:类不能被继承 2.static final:常量,应用率高 1) ...
- MySQL-报错:Error when bootstrapping CMake:
在进行MySQL的源码安装的时候,系统上找不到合适的C编译器,GCC忘了装,莫慌,直接 yum命令装上gcc,还有gcc-C++没装的话后面也会提示错误,一起装上,,, [root@localhos ...
- C++中的cout.setf(ios::fixed)是什么意思?
问题描述:在阅读一段代码时,发现代码的最后一部分出现 ... cout.setf(ios::fixed); cout.setf(ios::showpoint); ... 解决: cout.setf() ...
- 【c语言简单算法】1-阶乘
求n的阶乘 算法要求 从键盘输入一个数,求出这个数的阶乘 代码实现 #include main() { double result=1; size_t n; scanf("%d", ...
- AtCoder Beginner Contest 260 (D-E)
AtCoder Beginner Contest 260 - AtCoder D - Draw Your Cards 题意:N张卡牌数字 1-n,以某种顺序排放,每次拿一张,如果这一张比前面某一张小( ...
- 实践分享!GitLab CI/CD 快速入门
用过 GitLab 的同学肯定也对 GitLab CI/CD 不陌生,GitLab CI/CD 是一个内置在 GitLab 中的工具,它可以帮助我们在每次代码推送时运行一系列脚本来构建.测试和验证代码 ...
- 第七十七篇:ref引用(在vue中引用组件实例)
好家伙, 为方便理解, 我们先来写一个经典自增一按钮, 再加上一个count清零按钮, Left.vue组件中: <template> <div > <h1>我是L ...
- 快速生成组件语法模板的插件:Auto Close Tag
好家伙, 这是一个"标签闭合"插件 Auto Close Tag的安装: 来到VScode的拓展 安装后, 在其中输入一个左标签符号"<",随后会出现提示 ...
- mydodo协议
mydodo协议 目录 数据帧结构 命令 协议 代码样例 数据帧结构 帧头1 帧头2 设备号 命令 数据长度 数据 0x4D 0x59 xxx cmd nByte data 例子:设备my01 的继电 ...
- Homework6
1.问:阅读和了解什么是形式化方法? 答:形式化方法在逻辑科学中是指分析.研究思维形式结构的方法.是把各种具有不同内容的思维形式(主要是命题和推理)加以比较,找出各个部分相互联结的方式,抽取出共同的形 ...