ML-L1、L2 正则化
出现过拟合时,使用正则化可以将模型的拟合程度降低一点点,使曲线变得缓和。
L1正则化(LASSO)
正则项是所有参数的绝对值的和。正则化不包含theta0,因为他只是偏置,而不影响曲线的摆动幅度。
\]
# 使用pipeline进行封装
from sklearn.linear_model import Lasso
# 使用管道封装lasso
def LassoRegssion(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree = degree)),
("std_scaler", StandardScaler()),
("lasso", Lasso(alpha=alpha))
])
使用\(\alpha=0.01\) 的正则化拟合20阶多项式
lasso_reg = LassoRegssion(20, 0.01)
lasso_reg.fit(X_train, y_train)
y_predict = lasso_reg.predict(X_test)
plot_model(lasso_reg)
MSE 1.149608084325997
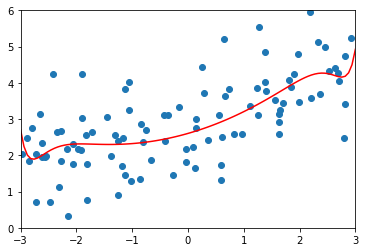
\(\alpha=0.1\)
MSE 1.1213911351818648

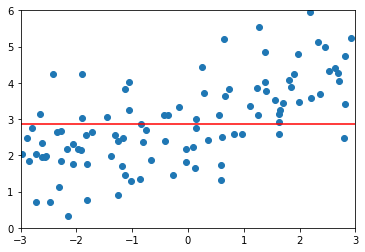
\(\alpha=1\) 时,均方误差又变大了,正则化过度了。模型变成了直线,所有参数都接近0了。因为没有对\(\theta_0\)进行正则化,所以偏置的值没有变化
1.8408939659515595
L2正则化(岭回归)
1/2可加可不加,因为方便求导。对J()求最小值时,也将\(\theta\)的值变小。当\(\alpha\)越大,右边受到的影响就越大,\(\theta\)的值就越小
\]
使用pipeline封装Ridge
from sklearn.linear_model import Ridge
# 使用管道封装岭回归
def RidgeRegression(degree, alpha):
return Pipeline([
("poly", PolynomialFeatures(degree = degree)),
("std_scaler", StandardScaler()),
("ridge_reg", Ridge(alpha = alpha))
])
使用20阶多项式拟合,\(\alpha=0\)即没有正则化。
ridge_reg100 = RidgeRegression(20, 0)
ridge_reg100.fit(X_train, y_train)
y_predict = ridge_reg100.predict(X_test)
plot_model(ridge_reg100)
# MSE 167.94010860994555

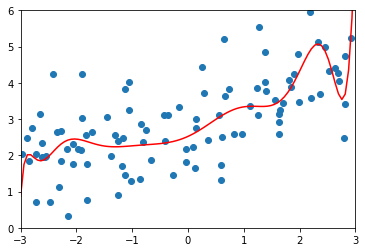
\(\alpha=0.0001\)
ridge_reg100 = RidgeRegression(20, 0.0001)
# MSE 1.3233492754136291
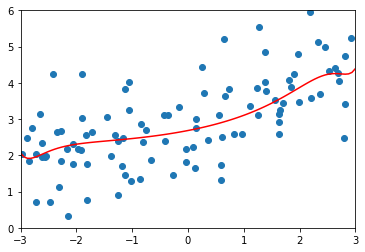
\(\alpha=10\)
ridge_reg100 = RidgeRegression(20, 10)
# MSE 1.1451272194878865
\(\alpha=1000\)
ridge_reg100 = RidgeRegression(20, 10000)
# MSE 1.7967435583384

对比
- LASSO更趋向于将一部分参数变为0,更容易得到直线。Ridge更容易得到曲线。
- \(\alpha\)越大,正则化的效果越明显
两个正则化的不同仅仅在于正则化项的不同:
\]
\]
常见的对比还有:
MSE 和 MAE :
\]
\]
欧拉距离和曼哈顿距离:
\]
还有明可夫斯基距离:
\]
弹性网(待定)
就是将两个范式进行结合。
\]
ML-L1、L2 正则化的更多相关文章
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- L1,L2正则化代码
# L1正则 import numpy as np from sklearn.linear_model import Lasso from sklearn.linear_model import SG ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 4.机器学习——统计学习三要素与最大似然估计、最大后验概率估计及L1、L2正则化
1.前言 之前我一直对于“最大似然估计”犯迷糊,今天在看了陶轻松.忆臻.nebulaf91等人的博客以及李航老师的<统计学习方法>后,豁然开朗,于是在此记下一些心得体会. “最大似然估计” ...
随机推荐
- 275. H 指数 II--Leetcode_二分
来源:力扣(LeetCode) 链接:https://leetcode.cn/problems/h-index-ii 著作权归领扣网络所有.商业转载请联系官方授权,非商业转载请注明出处. 题目的大意是 ...
- Hadoop的由来、Block切分、进程详解
Hadoop的由来.Block切分.进程详解 一.hadoop的由来 Google发布了三篇论文: GFS(Google File System) MapReduce(数据计算方法) BigTable ...
- 【BZOJ2658】[Zjoi2012]小蓝的好友(mrx) (扫描线,平衡树,模拟)
题面 终于到达了这次选拔赛的最后一题,想必你已经厌倦了小蓝和小白的故事,为了回馈各位比赛选手,此题的主角是贯穿这次比赛的关键人物--小蓝的好友. 在帮小蓝确定了旅游路线后,小蓝的好友也不会浪费这个难得 ...
- Python自学教程8-数据类型有哪些注意事项
不知不觉,python自学教程已经更新到第八篇了,再有几篇,基本的语法就介绍完了. 今天来总结一下数据类型有哪些需要注意的地方. 元组注意事项 元组是另一种经常使用到的数据类型,看上去和列表差不多.它 ...
- [WPF] 使用 HandyControl 的 CirclePanel 画出表盘刻度
1. 前言 最近需要一个 WPF 的表盘控件,之前 Cyril-hcj 写过一篇不错的博客 <WPF在圆上画出刻度线>,里面介绍了一些原理及详细实现的代码: double radius = ...
- SCP远程传输文件
今天想用SCP通过局域网传输文件到服务器,但却发生了下面这种事情: 上面描述 连接主机端口22被拒绝,失去连接 后发现因为没有指定端口,我服务器这边改了端口,所以根据自己情况改一下命令 scp -29 ...
- 播放器之争:VLC还是martPlayer
好多开发者跟我们交流的时候提到,为什么有了VLC这种开源播放器,大牛直播SDK还要开发SmartPlayer?以下就针对VLC和SmartPlayer功能支持和涉及侧重,做个大概的比较: VLC VL ...
- 手撸Router,还要啥Router框架?react-router/vue-router躺一边去
有没有发现,在大家使用React/Vue的时候,总离不开一个小尾巴,到哪都得带着他,那就是react-router/vue-router,而基于它们的第三方框架又出现很多个性化约定和扩展,比如nuxt ...
- 《Java编程思想》读书笔记(五)
前言:本文是<Java编程思想>读书笔记系列的最后一章,本章的内容很多,需要细读慢慢去理解,文中的示例最好在自己电脑上多运行几次,相关示例完整代码放在码云上了,码云地址:https://g ...
- Windows Server体验之应用兼容性按需功能
Windows Server默认仅能支持几个有图形界面的应用包括注册表编辑器regedit.记事本notepad.任务管理器taskmgr.时间设置control timedate.cpl.区域设置c ...