准确率、召回率及AUC概念分析
准确率&&召回率
信息检索、分类、识别、翻译等领域两个最基本指标是准确率(precision rate)和召回率(recall rate),准确率也叫查准率,召回率也叫查全率。这些概念非常重要的一个前提是针对特定的分类器和测试集的,即不同的数据集也会导致不同的结果。
- True Positives,TP:预测为正样本,实际也为正样本的特征数
- False Positives,FP:预测为正样本,实际为负样本的特征数(错预测为正样本了,所以叫False)
- True Negatives,TN:预测为负样本,实际也为负样本的特征数
- False Negatives,FN:预测为负样本,实际为正样本的特征数(错预测为负样本了,所以叫False)
- TP+FP+FN+FN:特征总数(样本总数)
- TP+FN:实际正样本数
- FP+TN:实际负样本数
- TP+FP:预测结果为正样本的总数
- TN+FN:预测结果为负样本的总数
通过医生诊病的例子来理解和记忆。 假设下面的场景:
医生为病人看病,病人是否有病与医生是否正确诊断,两个条件两两组合就形成了四种可能性。
- 病人有病并且被医生正确诊断,属于TP,即真阳性;
- 病人有病并且被医生错误诊断,属于FN,即假阴性;
- 病人无病并且被医生正确诊断,属于TN,即真阴性;
- 病人无病并且被医生错误诊断,属于FP,即假阳性;
再举一个最近正在做的一个动作识别的例子。
假定测试集合为100条数据,其中90条数据被模型判定为驾车,10条数据被判定为步行。在被判定为驾车的90条数据中,有80条数据是被正确判断的,10条数据是被错误判断的;在被判定为步行的10条数据中,有6条数据是被正确判断的,4条数据是被错误判断的。那么,我们将这四个数据填写到表格中。
- TP = 80; FP = 10
- FN = 4; TN = 6
这些数据都是针对驾车这一个类别来分类的,也就是准确率和召回率是针对某一个特定的类别来说的。
准确率的计算为 80 / (80 + 10) = 8/9,召回率的计算为80 / (80 + 4) = 20/21。
再举一个例子,这个例子是我最初用来理解准确率和召回率的例子,但是在我真正理解了准确率和召回率之后,这个例子反而具有了迷惑性。下面是网络上传的比较多的版本。
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的。撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 + 200 + 100) = 70%
召回率 = 700 / 1400 = 50%
如果将池子里的所有的鲤鱼、虾和鳖都一网打尽,这些指标则变化为如下:
正确率 = 1400 / (1400 + 300 + 300) = 70%
召回率 = 1400 / 1400 = 100%
之所以说这个例子有迷惑性,是我们应该用什么数据来填写上述的表格呢,也就是如何找到TP、FP、FN、TN呢?其实这个例子,有一些条件被默认了,或者被隐藏了,没有直接写出来。首先,这2000个生物是我们的整体的测试集合,当我们以鲤鱼为目的来进行分类时,将其中的1000个标记为鲤鱼类,剩余的1000个标记为非鲤鱼类,其中标记为鲤鱼类的1000个中,700个是被正确标记的,300个是被错误标记的;标记为非鲤鱼类的1000个中,700个是被错误标记的,300个是被正确标记的。其次,分类器是渔网开始捕捉时的行为,而不是已经捕捉完成之后的分类行为。
- TP = 700; FP = 300
- FN = 700; TN = 300
计算公式
准确率 = 系统检索到的相关文件/系统所有检索到的文件总数 (TP/(TP+FP))
召回率 = 系统检索到的相关文件/系统所有相关的文件总数 (TP/(TP+FN))
F值 = 准确率 * 召回率 * 2 / (正确率 + 召回率),F值即为正确率和召回率的调和平均值
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低;召回率高、准确率就低,当然如果两者都低,那是什么地方出问题了。一般情况下,用不同的阈值(此处可认为是不同的模型),统计出一组不同阈值下的准确率和召回率,如下图:

如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保证准确率的条件下,提升召回。所以,如果在两者要求都高的情况下,可以用F值来衡量。
ROC&&AUC
ROC和AUC是评价分类器的指标,ROC的全名是Receiver Operating Characteristic。
ROC关注两个指标:
True Positive Rate(TPR) = TP / (TP + FN),TPR代表能将正例分对的概率
False Positive Rate(FPR) = FP / (FP + TN),FPR代表将负例错分为正例的概率
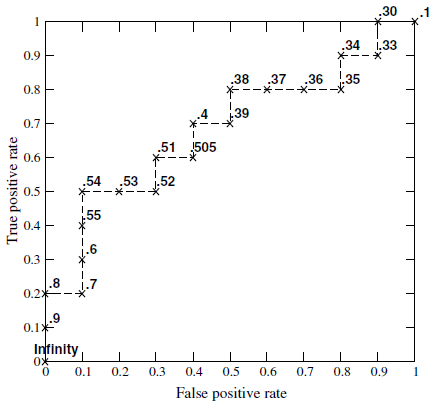
在ROC空间中,每个点的横坐标是FPR,纵坐标是TPR,这也描述了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0),(1,1),实际上(0,0),(1,1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0,0),(1,1)连线的上方。如图所示:
用ROC curve来表示分类器的performance很直观好用。可是,人们总希望能有一个数值来标识分类器的好坏。于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的performance。
从Mann-Whitney U statistic的角度来解释,AUC就是从所有1样本中随机选取一个样本,从所有0样本中随机选取一个样本,然后根据你的分类器对两个随机样本进行预测,把1样本预测为1的概率为p1,把0预测为1的概率为p0,p1 > p0的概率就等于AUC。所以AUC反映的是分类器对样本的排序能力。根据这个解释,如果我们完全随机的对样本分类,那么AUC应该接近0.5。
AUC&&PR
一个分类算法,找个最优的分类效果,对应到ROC空间中的一个点。通常分类器的输出都是Score,比如SVM、神经网络,有如下的预测结果:
TABLE 一般分类器的结果都是Score表
| No. | True | Hyp | Score |
|---|---|---|---|
| 1 | p | y | 0.99999 |
| 2 | p | y | 0.99999 |
| 3 | p | y | 0.99993 |
| 4 | p | y | 0.99986 |
| 5 | p | y | 0.99964 |
| 6 | p | y | 0.99955 |
| 7 | n | y | 0.68139 |
| 8 | n | y | 0.50961 |
| 9 | n | n | 0.48880 |
| 10 | n | n | 0.44951 |
True表示实际样本属性,Hyp表示预测结果样本属性,第4列即是Score,Hyp的结果通常是设定一个阈值,比如上表就是0.5,Score>0.5为正样本,小于0.5为负样本,这样只能算出一个ROC值,为更综合的评价算法的效果,通过取不同的阈值,得到多个ROC空间的值,将这些值描绘出ROC空间的曲线,即为ROC曲线。
有了ROC曲线,更加具有参考意义的评价指标就有了,在ROC空间,算法绘制的ROC曲线越凸向左上方向效果越好,有时不同分类算法的ROC曲线存在交叉,因此很多文章里用AUC(即Area Under Curve曲线下的面积)值作为算法好坏的评判标准。
与ROC曲线左上凸不同的是,PR曲线是右上凸效果越好,下面是两种曲线凸向的简单比较:
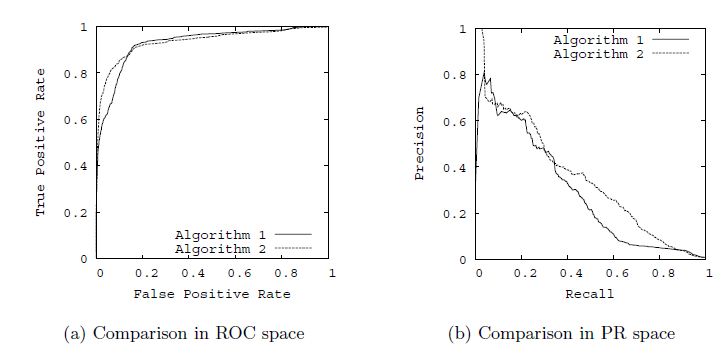
作为衡量指标,选择ROC或PR都是可以的。但是参考资料显示,ROC和PR虽然具有相同的出发点,但并不一定能得到相同的结论,在写论文的时候也只能参考着别人已有的进行选择了。
参考资料:
准确率、召回率及AUC概念分析的更多相关文章
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- 召回率、AUC、ROC模型评估指标精要
混淆矩阵 精准率/查准率,presicion 预测为正的样本中实际为正的概率 召回率/查全率,recall 实际为正的样本中被预测为正的概率 TPR F1分数,同时考虑查准率和查全率,二者达到平衡,= ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 准确率P 召回率R
Evaluation metricsa binary classifier accuracy,specificity,sensitivety.(整个分类器的准确性,正确率,错误率)表示分类正确:Tru ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- fashion_mnist 计算准确率、召回率、F1值
本文发布于 2020-12-27,很可能已经过时 fashion_mnist 计算准确率.召回率.F1值 1.定义 首先需要明确几个概念: 假设某次预测结果统计为下图: 那么各个指标的计算方法为: A ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- 混淆矩阵、准确率、召回率、ROC曲线、AUC
混淆矩阵.准确率.召回率.ROC曲线.AUC 假设有一个用来对猫(cats).狗(dogs).兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结.假设总共 ...
- 准确率、精确率、召回率、F-Measure、ROC、AUC
先理解一下正类(Positive)和负类(Negetive),比如现在要预测用户是否点击了某个广告链接,点击了才是我们要的结果,这时,点击了则表示为正类,没点击则表示为负类. TP(True Posi ...
随机推荐
- datetime 获取当前时间的各种格式(转)
我们可以通过使用DataTime这个类来获取当前的时间.通过调用类中的各种方法我们可以获取不同的时间:如:日期(2008-09-04).时间(12:12:12).日期+时间(2008-09-04 12 ...
- 虚拟机安装windows 7 32位 + sqlserver 2000
安装包网盘地址:(https://pan.baidu.com/s/1ZoC-cTafBi8zZbCkvvmvNA?pwd=x1y2 提取码:x1y2 ) VMware 安装win7 32 位 http ...
- Layui分页与springboots
service.java public List<Menu> listAllMenuPage(PageData pd) throws Exception{ List<Menu> ...
- Spring系列之类路径扫描和注册组件-8
目录 类路径扫描和注册组件 `@Component` 使用元注释和组合注释 自动检测类和注册 Bean 定义 使用过滤器自定义扫描 在组件中定义 Bean 元数据 命名自动检测到的组件 为自动检测的组 ...
- lgb文档学习
1.L1和l2损失是什么意思? 相较于MSE,MAE有个优点,那就是MAE对离群值不那么敏感,可以更好地拟合线性,因为MAE计算的是误差y−f(x)的绝对值,对于任意大小的差值,其惩罚都是固定的. 2 ...
- 面向对象ooDay9
精华笔记: 多态:多种形态 同一个对象被造型为不同的类型时,有不同的功能-------所有对象都是多态的(明天总结详细讲) 对象的多态:水.我.你...... 同一类型的引用在指向不同的对象时,有不同 ...
- element ui 点击选中表头并改变表头样式
前言: header-cell-style 表头单元格的 style 的回调方法,也可以使用一个固定的 Object 为所有表头单元格设置一样的 Style. Function({row, colum ...
- C数列或者C向量以及C矩阵
#include <stdlib.h> #include <stdio.h> #define TP double #define UI unsigned short int # ...
- 【git入门】基于阿里云搭建git
本文旨在说明基本的git使用流程,分为以下几个部分: 1.安装git环境 2.注册 3.git基本操作 一.安装git环境 第一次使用git,需要先安装配置git环境,windows版下载地址http ...
- C/C++命名规范-C语言基础
这一篇文章想要介绍的是编写代码的时候业界比较常用的一些命名规范,以及个人平时的一些命名规范.涉及"驼峰命名法"."下划线命名法"."帕斯卡命名法&qu ...