Hadoop学习之路(5)Mapreduce程序完成wordcount
程序使用的测试文本数据:
Dear River
Dear River Bear Spark
Car Dear Car Bear Car
Dear Car River Car
Spark Spark Dear Spark
1编写主要类
(1)Maper类
首先是自定义的Maper类代码
public class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//fields:代表着文本一行的的数据: dear bear river
String[] words = value.toString().split("\t");
for (String word : words) {
// 每个单词出现1次,作为中间结果输出
context.write(new Text(word), new IntWritable(1));
}
}
}
这个Map类是一个泛型类型,它有四个形参类型,分别指定map()函数的输入键、输入值、输出键和输出值的类型。LongWritable:输入键类型,Text:输入值类型,Text:输出键类型,IntWritable:输出值类型.
String[] words = value.toString().split("\t");,words 的值为Dear River Bear River
输入键key是一个长整数偏移量,用来寻找第一行的数据和下一行的数据,输入值是一行文本Dear River Bear River,输出键是单词Bear ,输出值是整数1。
Hadoop本身提供了一套可优化网络序列化传输的基本类型,而不直接使用Java内嵌的类型。这些类型都在org.apache.hadoop.io包中。这里使用LongWritable类型(相当于Java的Long类型)、Text类型(相当于Java中的String类型)和IntWritable类型(相当于Java的Integer类型)。
map()方法的参数是输入键和输入值。以本程序为例,输入键LongWritable key是一个偏移量,输入值Text value是Dear Car Bear Car ,我们首先将包含有一行输入的Text值转换成Java的String类型,之后使用substring()方法提取我们感兴趣的列。map()方法还提供了Context实例用于输出内容的写入。
(2)Reducer类
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
/*
(River, 1)
(River, 1)
(River, 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
key: River
value: List(1, 1, 1)
key: Spark
value: List(1, 1, 1,1)
*/
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
context.write(key, new IntWritable(sum));// 输出最终结果
};
}
Reduce任务最初按照分区号从Map端抓取数据为:
(River, 1)
(River, 1)
(River, 1)
(spark, 1)
(Spark , 1)
(Spark , 1)
(Spark , 1)
经过处理后得到的结果为:
key: hello value: List(1, 1, 1)
key: spark value: List(1, 1, 1,1)
所以reduce()函数的形参 Iterable<IntWritable> values 接收到的值为List(1, 1, 1)和List(1, 1, 1,1)
(3)Main函数
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountMain {
//若在IDEA中本地执行MR程序,需要将mapred-site.xml中的mapreduce.framework.name值修改成local
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
if (args.length != 2 || args == null) {
System.out.println("please input Path!");
System.exit(0);
}
//System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//configuration.set("mapreduce.job.jar","/home/bruce/project/kkbhdp01/target/com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
//调用getInstance方法,生成job实例
Job job = Job.getInstance(configuration, WordCountMain.class.getSimpleName());
// 打jar包
job.setJarByClass(WordCountMain.class);
// 通过job设置输入/输出格式
// MR的默认输入格式是TextInputFormat,所以下两行可以注释掉
// job.setInputFormatClass(TextInputFormat.class);
// job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入/输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置处理Map/Reduce阶段的类
job.setMapperClass(WordCountMap.class);
//map combine减少网路传出量
job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
//如果map、reduce的输出的kv对类型一致,直接设置reduce的输出的kv对就行;如果不一样,需要分别设置map, reduce的 输出的kv类型
//job.setMapOutputKeyClass(.class)
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
// 设置reduce task最终输出key/value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 提交作业
job.waitForCompletion(true);
}
}
2本地运行
首先更改mapred-site.xml文件配置
将mapreduce.framework.name的值设置为local
然后本地运行:
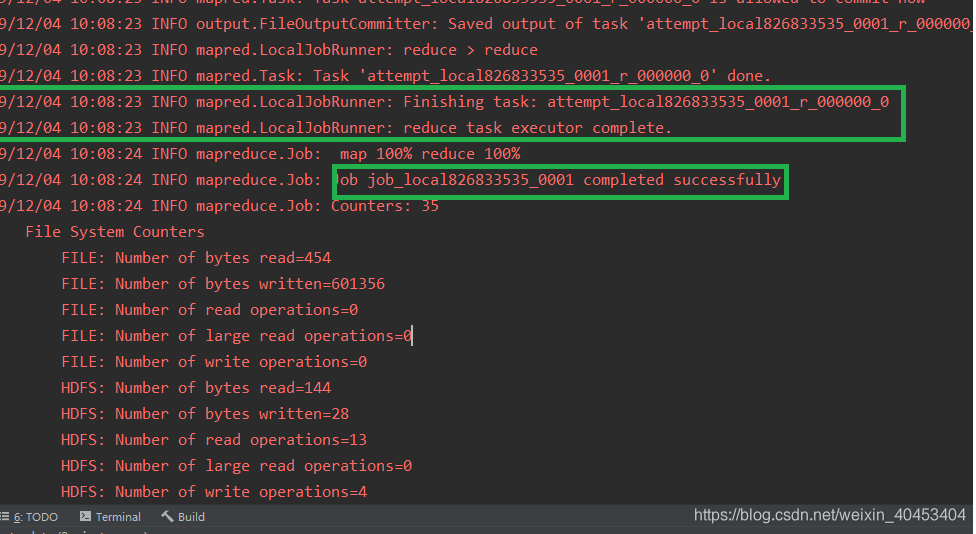
查看结果:
3集群运行
方式一:
首先打包
更改配置文件,改成yarn模式
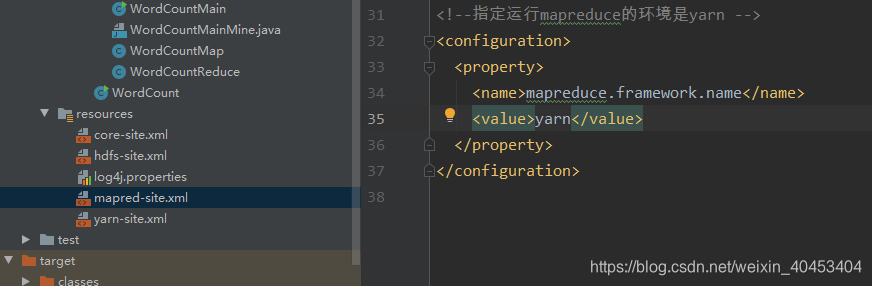
添加本地jar包位置:
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.jar","C:\\Users\\tanglei1\\IdeaProjects\\Hadooptang\\target");
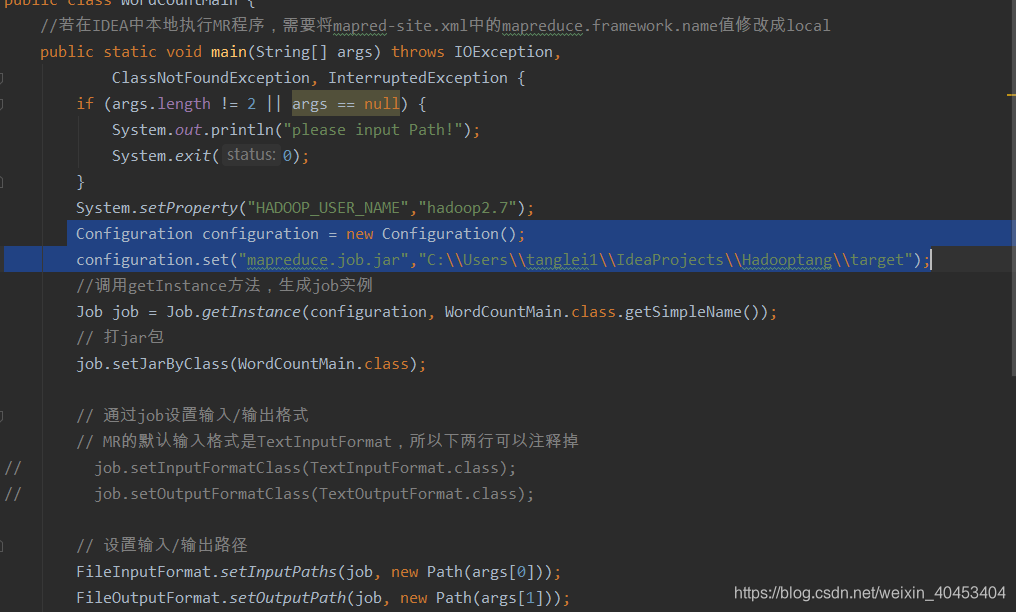
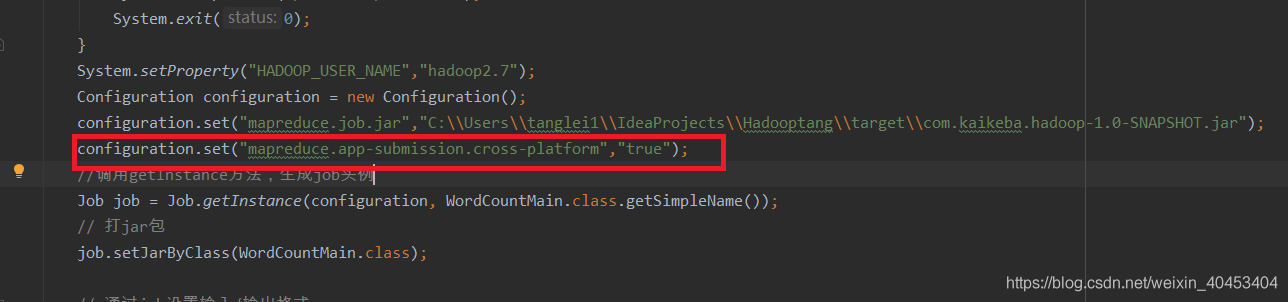
设置允许跨平台远程调用:
configuration.set("mapreduce.app-submission.cross-platform","true");
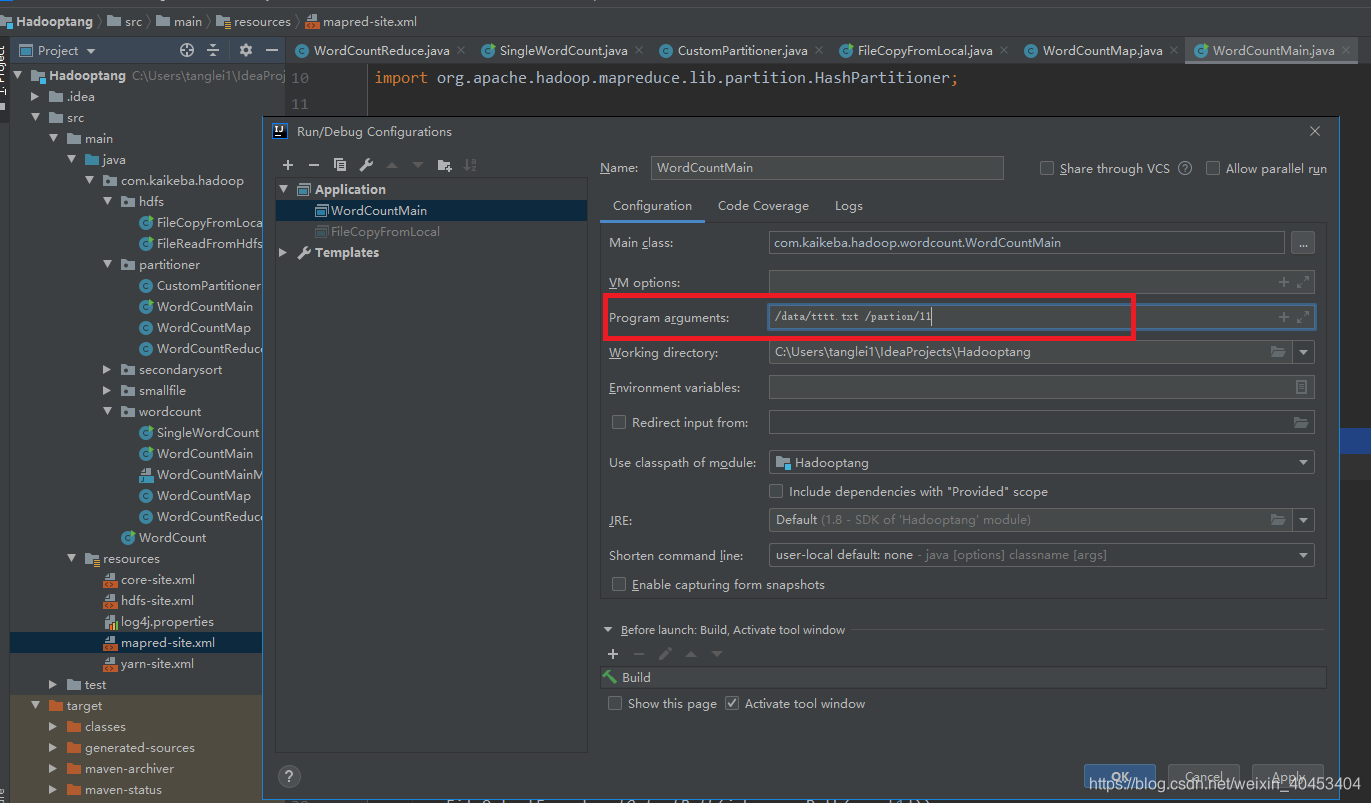
修改输入参数:
运行结果:
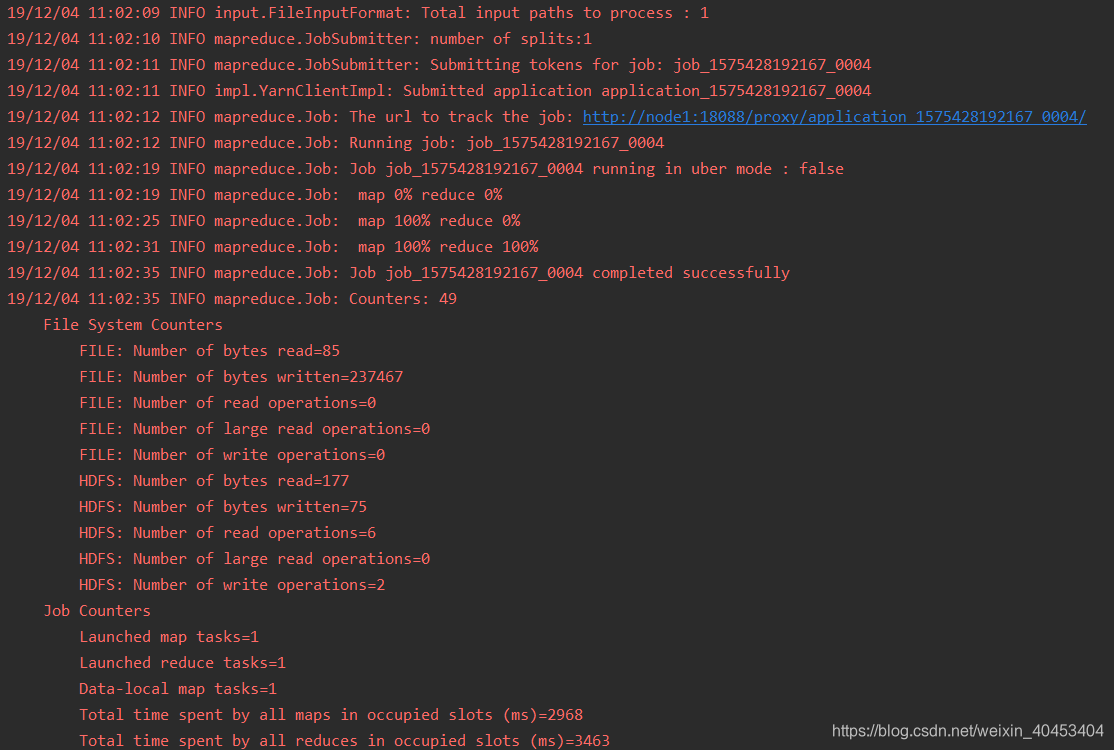
方式二:
将maven项目打包,在服务器端用命令运行mr程序
hadoop jar com.kaikeba.hadoop-1.0-SNAPSHOT.jar
com.kaikeba.hadoop.wordcount.WordCountMain /tttt.txt /wordcount11
Hadoop学习之路(5)Mapreduce程序完成wordcount的更多相关文章
- Hadoop学习之第一个MapReduce程序
期望 通过这个mapreduce程序了解mapreduce程序执行的流程,着重从程序解执行的打印信息中提炼出有用信息. 执行前 程序代码 程序代码基本上是<hadoop权威指南>上原封不动 ...
- Hadoop学习之路(7)MapReduce自定义排序
本文测试文本: tom 20 8000 nancy 22 8000 ketty 22 9000 stone 19 10000 green 19 11000 white 39 29000 socrate ...
- Hadoop学习之路(6)MapReduce自定义分区实现
MapReduce自带的分区器是HashPartitioner 原理:先对map输出的key求hash值,再模上reduce task个数,根据结果,决定此输出kv对,被匹配的reduce任务取走. ...
- Hadoop学习笔记—4.初识MapReduce
一.神马是高大上的MapReduce MapReduce是Google的一项重要技术,它首先是一个编程模型,用以进行大数据量的计算.对于大数据量的计算,通常采用的处理手法就是并行计算.但对许多开发者来 ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- Hadoop学习基础之三:MapReduce
现在是讨论这个问题的不错的时机,因为最近媒体上到处充斥着新的革命所谓“云计算”的信息.这种模式需要利用大量的(低端)处理器并行工作来解决计算问题.实际上,这建议利用大量的低端处理器来构建数据中心,而不 ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- Hadoop学习之路(十七)MapReduce框架Partitoner分区
Partitioner分区类的作用是什么? 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中:按照性别划分的话,需要 ...
- Hadoop学习之路(十五)MapReduce的多Job串联和全局计数器
MapReduce 多 Job 串联 需求 一个稍复杂点的处理逻辑往往需要多个 MapReduce 程序串联处理,多 job 的串联可以借助 MapReduce 框架的 JobControl 实现 实 ...
随机推荐
- C语言实现双人控制的战斗小游戏
实现功能 1.双人分别控制小人移动 2.子弹碰撞 3.可改变出弹方向 4.血条实体化 前言 这个游戏是看了知乎一位非常好的老师的专栏后练手写的,(至于是哪位,知乎搜C语言小游戏最牛逼的那位) 有老师系 ...
- Python学习小记(2)---[list, iterator, and, or, zip, dict.keys]
1.List行为 可以用 alist[:] 相当于 alist.copy() ,可以创建一个 alist 的 shallo copy,但是直接对 alist[:] 操作却会直接操作 alist 对象 ...
- 9种分布式ID生成之 美团(Leaf)实战
整理了一些Java方面的架构.面试资料(微服务.集群.分布式.中间件等),有需要的小伙伴可以关注公众号[程序员内点事],无套路自行领取 更多优选 一口气说出 9种 分布式ID生成方式,面试官有点懵了 ...
- .NET知识梳理——1.泛型Generic
1. 泛型Generic 1.1 引入泛型:延迟声明 泛型方法声明时,并未写死类型,在调用的时候再指定类型. 延迟声明:推迟一切可以推迟的. 1.2 如何声明和使用泛型 泛 ...
- 皮皮家园干活~万元web前端系统班在线课程点击免费领取
点击添加群聊 今天在整理百度云盘里的资源,这几年累计了不少软件和教程. 在这特殊的时期里,先给大家分享一波.图片里的文件夹就是目录, 加入群聊免费领取 好资源就是要大家一起共享, 你们也不用到处在网上 ...
- Spark基础和RDD
spark 1. Spark的四大特性 速度快 spark比mapreduce快的两个原因 基于内存 1. mapreduce任务后期在计算的是时候,每一个job的输出结果都会落地到磁盘,后续有其他的 ...
- 安装Matlab R2017a 出现 “弹出DVD1 并插入DVD2” 解决办法超简单
打开此电脑 找到驱动器虚拟镜像 右击选择弹出 点击另一个文件装载 点击确定即可
- 常用 PostgreSQL 脚本
数据定义 数据库 -- 创建数据库 -- https://www.postgresql.org/docs/current/static/multibyte.html -- database_name, ...
- Bringing up interface eth0: Device eth0 does not seem to be presen
在公司的电脑虚拟机上安装了centos 6.5 ,然后我把他克隆下来用在家里电脑的虚拟机上,打开后查看ip,发现只有回环地址lo,没有eth0, 于是重启网络 输入 service network r ...
- Enityt模型特性
数据验证相关的数据注解: 特性 解释 Remote 使用 jQuery 验证插件远程验证程序的特性 FileExtension 验证文件扩展名 Compare 比较两个属性的值 RegularExpr ...