【python技巧】替换文件中的某几行
【python技巧】替换文件中的某几行
1. 背景描述
最近在写一个后端项目,主要的操作就是根据用户的前端数据,在后端打开项目中的代码文件,修改对应位置的参数,因为在目前的后端项目中经常使用这个操作,所以简单总结一下。
1. 文件路径:./test.c
2. 文件内容
……
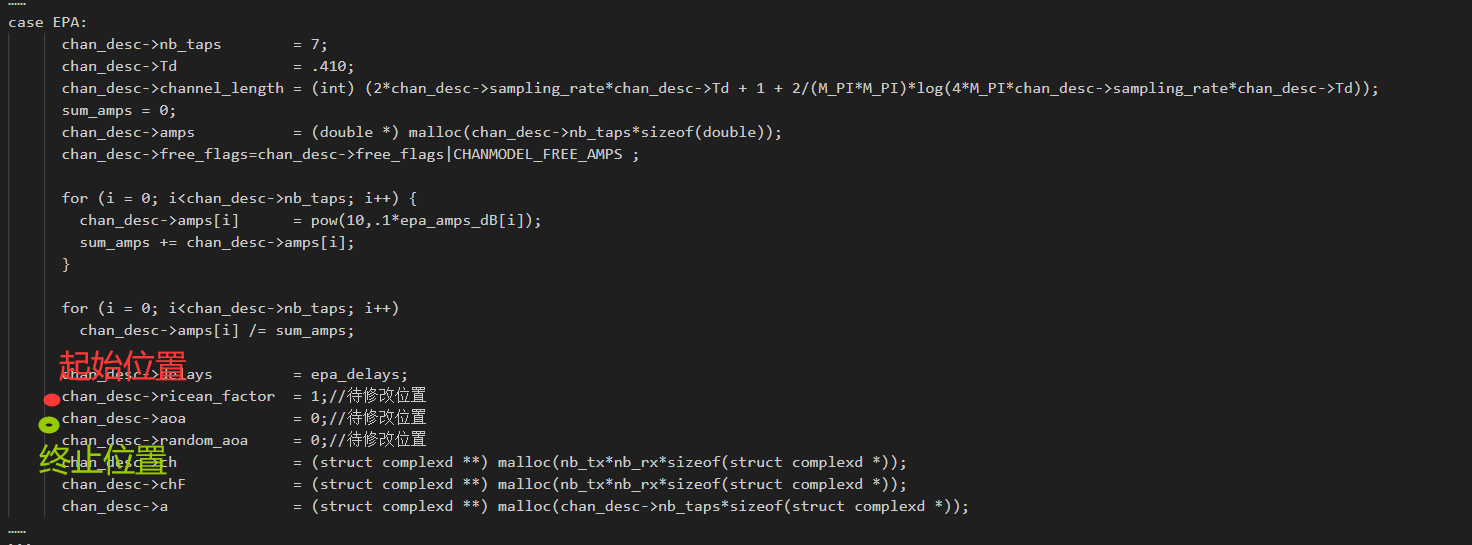
case EPA:
chan_desc->nb_taps = 7;
chan_desc->Td = .410;
chan_desc->channel_length = (int) (2*chan_desc->sampling_rate*chan_desc->Td + 1 + 2/(M_PI*M_PI)*log(4*M_PI*chan_desc->sampling_rate*chan_desc->Td));
sum_amps = 0;
chan_desc->amps = (double *) malloc(chan_desc->nb_taps*sizeof(double));
chan_desc->free_flags=chan_desc->free_flags|CHANMODEL_FREE_AMPS ;
for (i = 0; i<chan_desc->nb_taps; i++) {
chan_desc->amps[i] = pow(10,.1*epa_amps_dB[i]);
sum_amps += chan_desc->amps[i];
}
for (i = 0; i<chan_desc->nb_taps; i++)
chan_desc->amps[i] /= sum_amps;
chan_desc->delays = epa_delays;
chan_desc->ricean_factor = 1;//待修改位置
chan_desc->aoa = 0;//待修改位置
chan_desc->random_aoa = 0;//待修改位置
chan_desc->ch = (struct complexd **) malloc(nb_tx*nb_rx*sizeof(struct complexd *));
chan_desc->chF = (struct complexd **) malloc(nb_tx*nb_rx*sizeof(struct complexd *));
chan_desc->a = (struct complexd **) malloc(chan_desc->nb_taps*sizeof(struct complexd *));
……
2. 单行修改-操作步骤
- 读取文件
使用python中的open()函数进行文件读取,将数据存储在缓冲区。
#1. 读取文件
path='./test.c'
with open(path, 'r') as file:
file_content = file.read()
- 查找文件替换位置
以查找chan_desc->ricean_factor = 1;//待修改位置为例,查找这句话的起点和终点。
## 注:此步骤需要import re
#2. 查找文件替换位置
start_index=file_content.find('chan_desc->ricean_factor = ')#起点
end_index=file_content.find('chan_desc->aoa = ',start_index)#终点
if end_index==-1 or start_index==-1:
print('未找到待修改位置')
#此时得到的两个指针,分别指向了待修改位置的起点和终点,如下图所示:
- 设置替换文件内容
假设目前只修改这一行的参数,
#3. 设置替换文件内容
ricean_factor=3#假设这是要修改的参数信息
updata_content=file_content[:start_index]#获取这行代码之前的内容
update_content+='chan_desc->ricean_factor = '+str(ricean_factor)+';//待修改位置'#修改这行代码
update_content+=file_content[end_index:]#获取这行代码之后的内容
#此时得到的update_content就是修改后的完整文件内容,只修改了ricean_factor这一行的值
- 写入文件
同样使用python中的open函数。
#4. 写入文件
if update_content!="":#如果修改内容不为空
with open(path, 'w') as file:#w表示覆盖写入,之前的内容都会被覆盖
file.write(update_content)
- 总代码
整体的代码如下所示:
import re
#1. 读取文件
path='./test.c'
with open(path, 'r') as file:
file_content = file.read()
#2. 查找文件替换位置
start_index=file_content.find('chan_desc->ricean_factor = ')#起点
end_index=file_content.find('chan_desc->aoa = ',start_index)#终点
if end_index==-1 or start_index==-1:
print('未找到待修改位置')
#3. 设置替换文件内容
ricean_factor=3#假设这是要修改的参数信息
updata_content=file_content[:start_index]#获取这行代码之前的内容
update_content+='chan_desc->ricean_factor = '+str(ricean_factor)+';//待修改位置'#修改这行代码
update_content+=file_content[end_index:]#获取这行代码之后的内容
#4. 写入文件
if update_content!="":#如果修改内容不为空
with open(path, 'w') as file:#w表示覆盖写入,之前的内容都会被覆盖
file.write(update_content)
3. 多行修改-操作步骤
- 多行修改思路
多行修改有两种修改思路,如果修改部分比较集中,则可直接替换一整块的字符串内容,如果修改部分较为分散,则需要单独查找修改位置,然后再分别进行替换。 - 多行修改-整块替换
try:
with open(file_path, "r") as file:
file_content = file.read()
except Exception as e:
return str(e)
# 设置改写内容
updated_content = ""
# 查找修改
start_index_1 = file_content.find("start_sentence")#要确保查找元素的唯一性
end_index_1 = file_content.find("end_sentence",start_index_1,)
if start_index_1 == -1 or end_index_1 == -1:
print("未找到待修改位置")
return -1
#
updated_content = file_content[:start_index_1]#获取这行代码之前的内容
updated_content += "start_sentence和end_sentence之间的sentence_1;\n"
updated_content += "start_sentence和end_sentence之间的sentence_2;\n"
updated_content +=file_content[end_index_1:]
##此时updated_content就是修改后的完整文件内容
if updated_content != "":
with open(file_path, "w") as file:
file.write(updated_content)
else:
print("修改失败")
return -1
- 多行修改-局部替换
try:
with open(file_path, "r") as file:
file_content = file.read()
except Exception as e:
return str(e)
# 设置改写内容
updated_content = ""
# 查找修改
start_index_1 = file_content.find("start_sentence_1")#要确保查找元素的唯一性
end_index_1 = file_content.find("end_sentence_1",start_index_1,)
start_index_2 = file_content.find("start_sentence_2",end_index_1)
end_index_2 = file_content.find("end_sentence_2",start_index_2,)
start_index_3 = file_content.find("start_sentence_3",end_index_2)
end_index_3 = file_content.find("end_sentence_3",start_index_3,)
start_index_4 = file_content.find("start_sentence_4",end_index_3)
end_index_4 = file_content.find("end_sentence_4",start_index_4,)
if (
start_index_1 == -1
or end_index_1 == -1
or start_index_2 == -1
or end_index_2 == -1
or start_index_3 == -1
or end_index_3 == -1
or start_index_4 == -1
or end_index_4 == -1
):
print("未找到待修改位置")
return -1
#
updated_content = file_content[:start_index_1]#获取这行代码之前的内容
updated_content += "start_sentence_1和end_sentence_1之间的内容"
updated_content +=file_content[end_index_1:start_index_2]
updated_content += "start_sentence_2和end_sentence_2之间的内容"
updated_content +=file_content[end_index_2:start_index_3]
updated_content += "start_sentence_3和end_sentence_3之间的内容"
updated_content +=file_content[end_index_3:start_index_4]
updated_content += "start_sentence_4和end_sentence_4之间的内容"
updated_content += file_content[end_index_4:]
##此时updated_content就是修改后的完整文件内容
if updated_content != "":
with open(file_path, "w") as file:
file.write(updated_content)
else:
print("修改失败")
return -1
【python技巧】替换文件中的某几行的更多相关文章
- linux 小技巧(查找替换文件中的ascii编码字符)
这里纪录一些linux下用到的小技巧,以免遗忘 在linux中经常碰见各种文件处理.最常用的就是替换文件中的某些字符.常见字符替换还是很容易完成.但是有些不可见字符以及ascii编码字符等等都无法直接 ...
- 用python 替换文件中的git地址
有个需求要替换文件中git地址,要替换成的git地址是一个变量 本来想用sed替换但是git地址中有斜杠符号 需要转义,提前知道还好弄,如果是变量就不好处理了 #!/usr/bin/python3 # ...
- python逐行读取替换文件中的字符串
用列表中的值逐行替换文件中符合条件的字符串,并保存为新的文件, open("file").readlines 方案1: 逐行替换并保存为新的文件 import re def rep ...
- python操作txt文件中数据教程[4]-python去掉txt文件行尾换行
python操作txt文件中数据教程[4]-python去掉txt文件行尾换行 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文章 python操作txt文件中数据教程[1]-使用pyt ...
- python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 python操作txt文件中 ...
- python操作txt文件中数据教程[2]-python提取txt文件
python操作txt文件中数据教程[2]-python提取txt文件中的行列元素 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果-将txt中元素提取并保存在c ...
- python操作txt文件中数据教程[1]-使用python读写txt文件
python操作txt文件中数据教程[1]-使用python读写txt文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 原始txt文件 程序实现后结果 程序实现 filename = '. ...
- linux sed 批量替换文件中的字符串或符号
sed -i :直接修改读取的文件内容,而不是输出到终端. sed -i 就是直接对文本文件进行操作的 替换每行第一次出现的字符串 sed -i 's/查找的字符串/替换的字符串/' 文件 ...
- Python 调用JS文件中的函数
Python 调用JS文件中的函数 1.安装PyExecJS第三方库 2.导入库:import execjs 3.调用JS文件中的方法 Passwd = execjs.compile(open(r&q ...
- 使用 sed 命令查找和替换文件中的字符串的 16 个示例
当你在使用文本文件时,很可能需要查找和替换文件中的字符串.sed 命令主要用于替换一个文件中的文本.在 Linux 中这可以通过使用 sed 命令和 awk 命令来完成. 在本教程中,我们将告诉你使用 ...
随机推荐
- remote: HTTP Basic:Access denied fatal:Authentication failed for
近来在一天新电脑上面使用git pull 一个项目,老是提示 Access denied, 找了许多方法,ssh key这些都配置了还是不行,当时别提有多尬 看嘛这就是pull 时的提示 // *** ...
- cve_2020_6507分析
poc $ cat poc.js array = Array(0x40000).fill(1.1); args = Array(0x100 - 1).fill(array); args.push(Ar ...
- 曲线艺术编程 coding curves 第四章 利萨茹曲线(Lissajous Curves)
第四章 利萨茹曲线(Lissajous Curves) 原作:Keith Peters https://www.bit-101.com/blog/2022/11/coding-curves/ 译者:池 ...
- Spring框架参考手册(4.2.6版本)翻译——第三部分 核心技术 6.10.8 提供带注解的限定符元数据
6.1.1 提供带注解的限定符元数据 在第6.9.4节"使用@Qualifier微调基于注解的自动装配"中讨论了@Qualifier注解.该部分中的示例阐释了,在解析自动装配候选者 ...
- ubuntu22.04下编译ffmpeg-6.0,并且激活x264编码功能。记录一下踩坑(ERROR: x264 not found using pkg-config)
一.编译x264(在编译前确保安装了pkg-config,默认在/usr/share下) 1.下载x264源代码:(我下载到了~/Downloads下,各位随意就好) git clone https: ...
- Python 一大坑,配置文件中字典引用问题(拷贝)。
大坑 +1 python 配置文件中字典引用问题 最近在开发系统时发现一个传奇的BUG, 用户未登录就可进入系统内,而且含有真实身份信息. 此问题困扰多时,反复debug.由于找不到问题原因,复现具有 ...
- 从TL、ITL到TT
1.概述 ThreadLocal(TL)是Java中一种线程局部变量实现机制,他为每个线程提供一个单独的变量副本,保证多线程场景下,变量的线程安全.经常用于代替参数的显式传递. Inheritable ...
- [Spring+SpringMVC+Mybatis]框架学习笔记:前言_目录
下一章:[Spring+SpringMVC+Mybatis]框架学习笔记(一):SpringIOC概述 前言 本笔记用于记录本人(Steven)的SSM框架学习历程,仅用作学习.交流,不用于商业用途, ...
- CocosCreator + Vscode + Ts 代码注释生成文档,利用typedoc
需求: 脚本的代码注释,生成为文档 基本搭建环境: (cocoscreator 2.4.x + vscode + ts) .(nodejs + npm) 步骤: 1.安装typedoc: npm in ...
- Ui2Code+ChatGPT助力低代码搭建
前言 低代码开发平台(LCDP),是低代码或无代码通过快速搭建配置的方式完成一个应用程序的开发与上线,可视化低代码就是可视化的DSL,它的优点更多的是来源可视化,相对的,它的局限性也还是来源于可视化, ...