【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】
官方参考 配置 地址 :http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
一、
在Hadoop-senior.zuoyan.com 的主机上
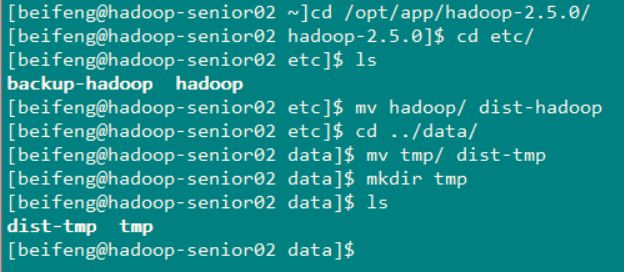
首先将Hadoop安装目录下 etc下的hadoop的配置文件进行备份 使用命令: cp -r hadoop dist-hadoop
然后在Hadoop安装目录下 data 文件夹内 将tmp 文件夹 重命名 使用命令 : mv tmp dits-tmp ,重命名完成后,在创建一个文件夹 mkdir tmp
然后在其余的 两台主机上也重复这个操作
将hadoop安装目录下的etc下的hadoop的所有配置文件复制文件为 dist-hadoop 然后再Hadoop的主安装目录中的data 下的 tmp 目录重命名为 dist-tmp 然后在创建新的数据存放目录
说明:图片中使用的命令有错误,不应该是重命名hadoop 而应该是重新复制文件,将复制文件的名字设置为 dist-hadoop
二、修改配置文件
打开core-site.xml 和 hdfs-site.xml 文件
在core-site.xml 文件中配置
因为是NameNode 的高可用行,配制两台机器的NameNode ,需要修改这个,所以需要配置成集群

在hdfs-site.xml 配置文件中配制:
首先去除掉
<!--配置secondary namenode 所在的主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior03.zuoyan.com:50090</value>
</property>
在 /opt/app/hadoop2.5.0/data 目录下创建文件夹 dfs/jn 用来存放NameNode的 日志信息
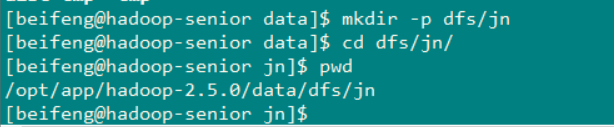
然后在从hdfs-site.xml 文件中配置
<!--配置Hadoop NameNode 的HA -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property> <property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property> <!-- NameNode RPC Adress -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hadoop-senior.zuoyan.com:8020</value>
</property> <property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hadoop-senior02.zuoyan.com:8020</value>
</property> <!-- 配置 WEB 界面的 访问地址和端口 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hadoop-senior.zuoyan.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hadoop-senior02.zuoyan.com:50070</value>
</property> <!--配置 NameNode Shared EDITS Address 和NameNode 日志文件存放的位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop-senior.zuoyan.com:8485;hadoop-senior02.zuoyan.com:8485;hadoop-senior03.zuoyan.com:8485/ns1</value>
</property> <property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/app/hadoop-2.5.0/data/dfs/jn</value>
</property> <!-- 配置 HDFS PROXY Client -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <!--配置两个 NameNode的隔离机制 -->
<!-- 使用的方式是 ssh-fence 要求是两个NameNode 之间能够无密码登录 两个主机之间能互相ssh无密钥登录 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/beifeng/.ssh/id_rsa</value>
</property>
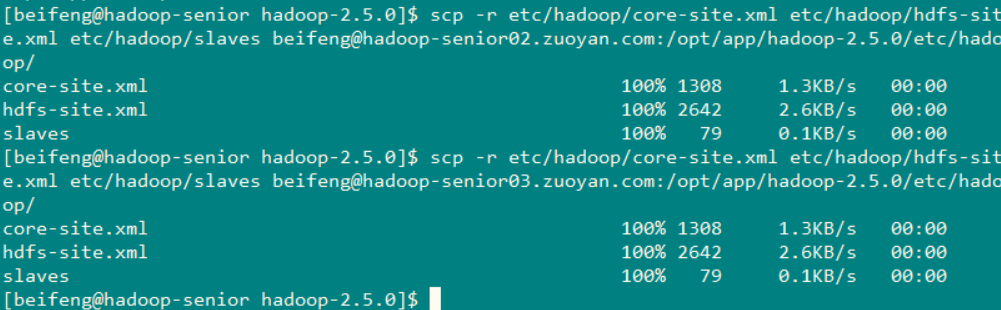
配置好 主机一(hadoop-senior.zuoyan.com) 需要将配置文件进行同步
使用命令 scp -r etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml etc/hadoop/slaves beifeng@hadoop-senior02.zuoyan.com:/opt/app/hadoop-2.5.0/etc/hadoop/
开始启动QJM HA:
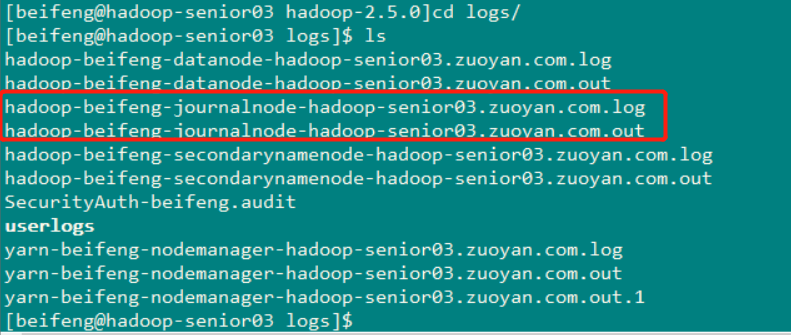
完成后,分别启动三个节点的journalnode 使用命令: sbin/hadoop-daemon.sh start journalnode 每个节点启动后 使用jps查看一下进程,看任务是否启动

可以查看一下启动日志(这个步骤不是必须要做的 可以看见journalnode 的启动日志):
在NameNode1节点上 对文件系统进行格式化,产生fsimage 文件 使用命令 : bin/hdfs namenode -format 然后再启动NameNode
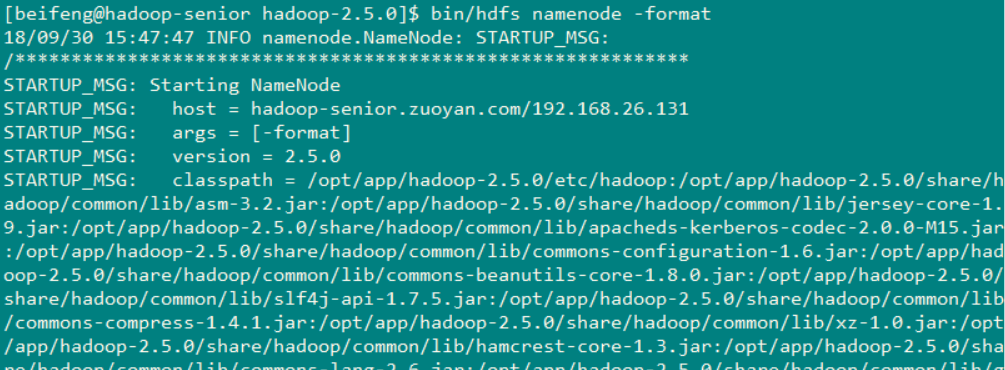

在NameNode1 上启动namenode 使用命令 : bin/hadoop-daemon.sh start namenode
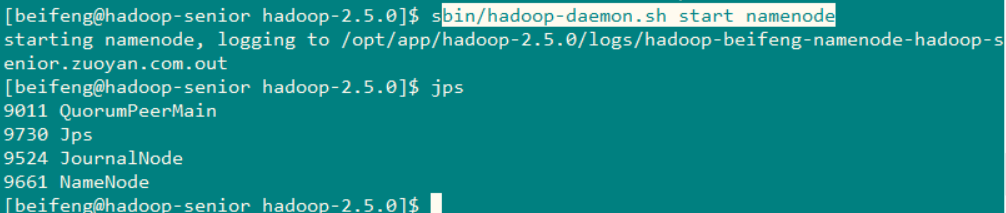
之后在NameNode2 上同步NameNode1 的元数据信息
使用命令:bin/hdfs namenode -bootstrapStandby

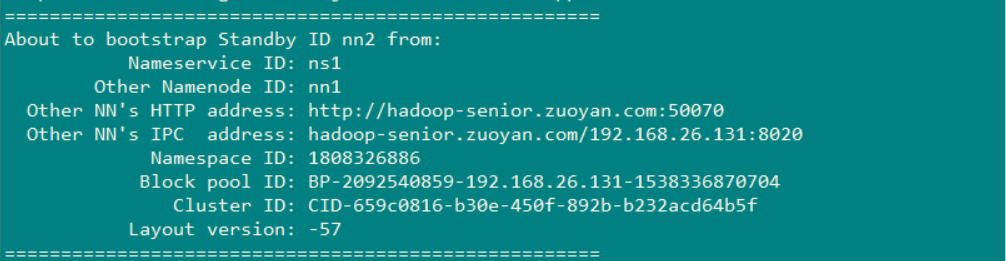
可以看到复制镜像文件是从Hadoop-senior.zuoyan.com 上拷贝

然后启动NameNode2 使用命令: sbin/hadoop-daemon.sh start namenode
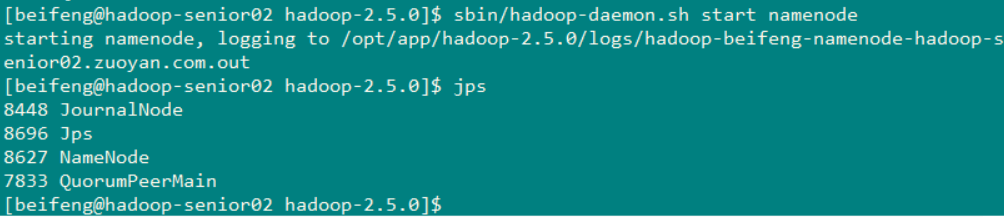
然后分别访问这两个主机的50070 发现如果可以访问 就初步配置成功
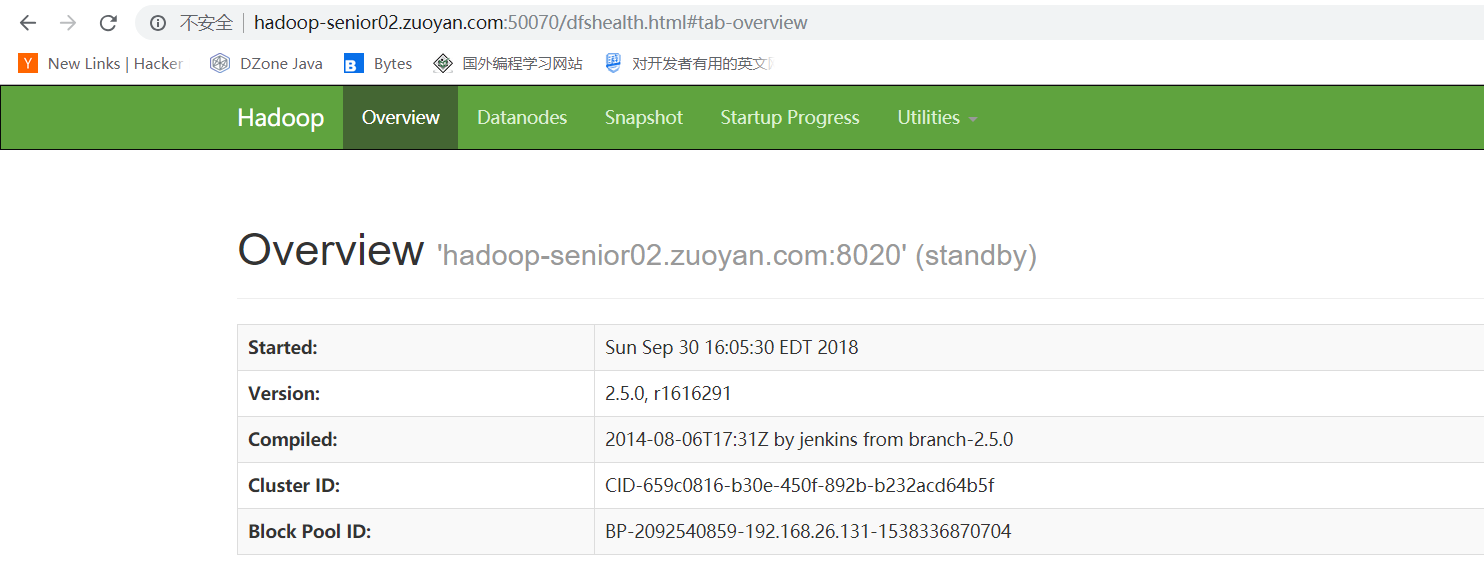

然后启动所有机器上的DataNode 使用命令:sbin/start-dfs.sh (也可以使用命令 一个个启动 sbin/hadoop-daemon.sh start datanode 我这里省事,就所有机器的都启动)
打开WEB界面 发现两个NameNode 都可以进行管理 这样就是配置成功!!!
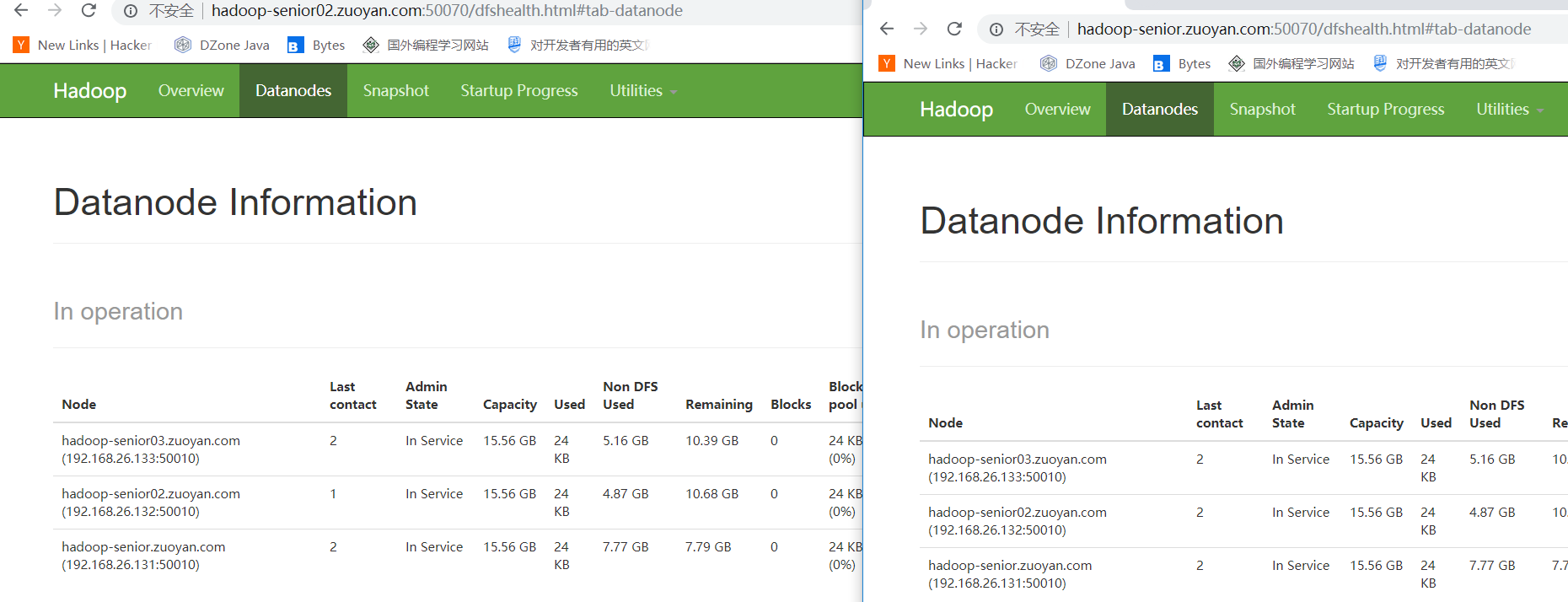
使用命令将第一个节点改变为活跃状态,使用命令: bin/hdfs haadmin -transitionToActive nn1
(可以看到这个NameNode 节点 已经改变为活跃状态)

也可以通过命令 来查看节点的状态 (可以看到这两个主机 一个是active 一个是 standby)

现在查看一下 HDFS文件系统上的文件 来进行测试NameNode
(下面没有打印出文件 这个上面说没有找到ns1 这个原因技就是我们在配置Proxy的时候 没有改变myclsur)

下面这个内容配置错误的原因,我现在已经更改过来了

更改完成后,在执行一下 (就可以看见文件目录已经循环出来了)

使用命令创建文件目录

将文件上传到文件系统上

通过文件管理的web界面进行查看 (就会发现文件已经上传成功)

然后 在测试HA的读取功能 使用命令: bin/hdfs dfs -text /user/zuoyan/conf/core-site.xml
文件已经成功 正常的被读取出来了

然后通过命令 将 nn1 切换称 standby 将nn2 切换成 active
将节点切换成Standby的命令 :bin/hdfs haadmin -transitionToStandby nn1
将节点切换成Active 的命令 : bin/hdfs haadmin -transitionToActive nn2

切换之后在用NameNode 1 去读取HDFS上的文件 测试 是否能正常读取文件
(切换之后已经正常的读取出来了,证明节点切换 对集群是没有影响的)
完成到这样 HDFS的高可用 已经初步搭建好了
【Hadoop 分布式部署 十:配置HDFS 的HA、启动HA中的各个守护进程】的更多相关文章
- 【Hadoop 分布式部署 十 一: NameNode HA 自动故障转移】
问题描述: 上一篇就是NameNode 的HA 部署完成,但是存在问题,问题是如果 主NameNode的节点宕机了,还是需要人工去使用命令来切换NameNode的Acitve 这样很不方便,所以 ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- CentOS7 下 Hadoop 分布式部署
Hadoop 服务划分 使用三台节点,集群部署规划如下 服务\主机 hadoop1 hadoop2 hadoop3 HDFS NameNode DataNode DataNode SecondaryN ...
- 【Hadoop 分布式部署 三:基于Hadoop 2.x 伪分布式部署进行修改配置文件】
1.规划好哪些服务运行在那个服务器上 需要配置的配置文件 2. 修改配置文件,设置服务运行机器节点 首先在 hadoop-senior 的这台主机上 进行 解压 hadoop2.5 按照 ...
- ubuntu在虚拟机下的安装 ~~~ Hadoop的安装及配置 ~~~ Hdfs中eclipse的安装
前言 Hadoop是基于Java语言开发的,具有很好跨平台的特性.Hadoop的所要求系统环境适用于Windows,Linux,Mac系统,我们推荐选择使用Linux或Mac系统.而Linux系统则 ...
- hadoop分布式部署(2014-3-8)
hadoop简介: (维基百科)Apache Hadoop是一款支持數據密集型分佈式應用并以Apache 2.0許可協議發佈的開源軟體框架.它支持在商品硬件構建的大型集群上運行的應用程序.Hadoop ...
- Hadoop分布式集群配置
硬件环境: 安装一个Hadoop集群时,需要专门指定一个服务器作为主节点. 三台虚拟机搭建的集群:(搭建集群时主机名不能一样,主机名在/etc/hostname修改) master机器:集群的主节点, ...
- 【Hadoop 分布式部署 九:分布式协作框架Zookeeper架构 分布式安装部署 】
1.首先将运行在本地上的 zookeeper 给停止掉 2.到/opt/softwares 目录下 将 zookeeper解压到 /opt/app 目录下 命令: tar -zxvf zoo ...
- 【Hadoop 分布式部署 四:配置Hadoop 2.x 中主节点(NN和RM)到从节点的SSH无密码登录】
******************* 一定要使这三台机器的用户名相同,安装目录相同 ************* SSH 无密钥登录的简单介绍(之前再搭 ...
随机推荐
- [openjudge-搜索]广度优先搜索之鸣人和佐助
题目描述 描述 佐助被大蛇丸诱骗走了,鸣人在多少时间内能追上他呢?已知一张地图(以二维矩阵的形式表示)以及佐助和鸣人的位置.地图上的每个位置都可以走到,只不过有些位置上有大蛇丸的手下,需要先打败大蛇丸 ...
- MVC 中的Model对象
最近实在是太忙,客户丢了一个框架,没有任何说明文档,更没有所谓的技术支持,一直忙于学习,最后好歹还有点头绪,话不多说,MVC的学习是不能拉下的,就当前小白的我,认为MVC中的M并不是想象中的那样简单, ...
- 使用Oozie中workflow的定时任务重跑hive数仓表的历史分期调度
在数仓和BI系统的开发和使用过程中会经常出现需要重跑数仓中某些或一段时间内的分区数据,原因可能是:1.数据统计和计算逻辑/口径调整,2.发现之前的埋点数据收集出现错误或者埋点出现错误,3.业务数据库出 ...
- JAVA基础2---深度解析A++和++A的区别
我们都知道JAVA中A++和++A在用法上的区别,都是自增,A++是先取值再自增,++A是先自增再取值,那么为什么会是这样的呢? 1.关于A++和++A的区别,下面的来看个例子: public cla ...
- Linux基础命令---切换用户su
su 临时切换身份到另外一个用户,使用su切换用户之后,不会改变当前的工作目录,但是会改变一些环境变量. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.SUSE.openSUS ...
- linux内核的双链表list_head、散列表hlist_head
一.双链表list_head 1.基本概念 linux内核提供的标准链表可用于将任何类型的数据结构彼此链接起来. 不是数据内嵌到链表中,而是把链表内嵌到数据对象中. 即:加入链表的数据结构必须包含一个 ...
- C#——WebApi 接口参数传参详解
本篇打算通过get.post.put.delete四种请求方式分别谈谈基础类型(包括int/string/datetime等).实体.数组等类型的参数如何传递. 一.get请求 对于取数据,我们使用最 ...
- How to do if the GM MDI cant connect with the software
When you use GM MDI on your laptop , you may meet some troubles . Such as it cant communicate with t ...
- 在vim编辑器python实现tab补全功能
在vim编辑器中实现python tab补全插件有Pydiction,Pydiction可以实现下面python代码的自动补全: 1. 简单python关键词补全 2. python函数补全带括号 3 ...
- 13:python-ldap
1.1 python-ldap 基本使用 11111111111111111111