python爬虫爬取小说网站
项目场景:
利用python爬取某小说网站,主要爬取小说名字,作者,类别,将其保存为三元组形式:(xxx, xxx, xxx)并将其保存至excel表格中。本文从爬取目的到爬取的各步骤都尽量详细的去复现。
(学习爬虫1个月,python两个月,记录自己的学习过程。只要爬成功一次后,之后就会更得心应手。)
本文中不恰当之处还望指正。
复现过程
1.审查相关数据元素标签:
比如我要爬取的内容都在下图红框标签中:
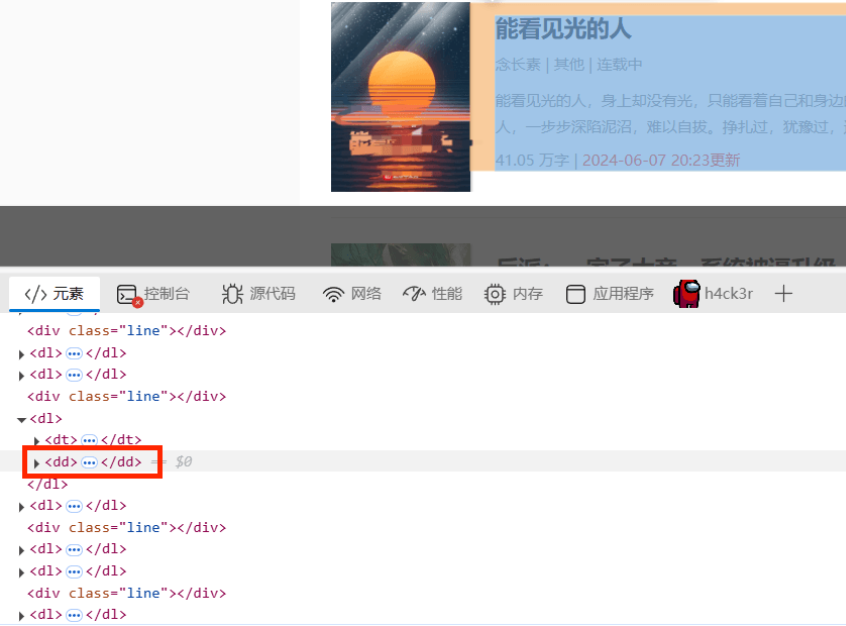
更细分一点呢,我要爬取的是标题,作者和类别,我们发现这三组数据在该页面中都可以找到,就在这个页面中进行爬取吧。接下来寻找数据对应的元素标签。
(打开开发者工具,F12,或在设置里打开也可。找到找个小图标:
点击你想要爬取的内容就可以找到其对应的标签了。)
下面我们来查看一下我们想要爬取的数据的标签吧。
小说名称对应的元素:

作者对应的元素标签:

类别对应的元素标签:

2.下面开始编写代码:
a.导入库:
import requests
from bs4 import BeautifulSoup
import pandas as pd
b.这里我就编写一个爬虫类NovelSpider了:
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page
这是编写类最基本的内容了,用__init__定义一个类的基本属性。
c.下面我们开始在类中编写一个具体的实现代码了:
def get_novel(self, url: str):
"""获取文章信息的方法"""
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
novel_list = []
dl_tag = soup.find_all('dl')
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
if title and author and type_:
novel_list.append([title, author, type_])
return novel_list
except Exception as e:
print(f'出现{e}错误!!!')
在编写python代码中使用try-except模块几乎是约定俗成的规定:
因为爬虫面临的不确定性很多:比如:网络问题(连接超时、DNS解析失败、SSL错误等),
目标网站变更(HTML结构调整、标签属性变化),反爬机制(IP封禁、验证码、请求频率限制),数据异常(缺失字段、格式不符预期)。"宁可失败也要明确原因,不要沉默地继续运行错误状态"
try-except块:
try:
xxx
except requests.RequestException as e:
print(f'请求出现 {e} 错误!!!')
except Exception as e:
print(f'出现{e}错误!!!')
在编写好最基本的爬虫语句后,着重处理我们想要爬取的特定标签:
我们知道,关于小说的内容都在以下元素中:
<dl>
<dt>
<a href="/novel/40814.html" target="_blank">
<img src="/uploads/novel/20240607/16b3a64816abde58e26c2c8313a2dc05.jpg" class="lazyimg" data-original="/uploads/novel/20240607/16b3a64816abde58e26c2c8313a2dc05.jpg" style="display: block;"></a>
</dt>
<dd>
<a href="/novel/40814.html" class="bigpic-book-name" target="_blank">能看见光的人</a>
<p>
<a href="/search/%E5%BF%B5%E9%95%BF%E7%B4%A0.html" target="_blank">念长素</a>
|
<a href="/lists/35.html" target="_blank">其他</a>
| 连载中 </p>
<p class="big-book-info">能看见光的人,身上却没有光,只能看着自己和身边的人,一步步深陷泥沼,难以自拔。挣扎过,犹豫过,逃避过,反抗过,最终抛弃信念,沉默地沉沦在现实的漩涡里。那些有光的人,终究才是世界的中心。也许,怪他不够努力,不够聪明,不够坚定吧...</p>
<p>
<span href="javascript:;" target="_blank">41.05 万字 |</span>
<span class="red">2024-06-07 20:23更新</span>
</p>
</dd>
</dl>
我们要遍历网页中的所有dl标签:
dl_tag = soup.find_all('dl')
*小说名称对应的a标签如下:
<a href="/novel/40814.html" class="bigpic-book-name" target="_blank">能看见光的人</a>
且具有属性:
class="bigpic-book-name"
*小说作者对应的a标签:
<a href="/search/%E5%BF%B5%E9%95%BF%E7%B4%A0.html" target="_blank">念长素</a>
*小说类别对应的a标签:
<a href="/lists/35.html" target="_blank">其他</a>
基于此可编写代码如下:
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
1.这行代码的作用是在一个 dl 标签内查找符合特定条件的 a 标签,这个条件是该 a 标签的 href 属性值包含 /search/ 字符串。
2.href=lambda href: href and '/search/' in href:这是一个条件表达式,用于筛选 a 标签。具体来说,它使用了一个匿名函数(lambda 函数)来定义筛选条件。
3.lambda href: href and '/search/' in href 这个匿名函数接受一个参数 href,它代表 a 标签的 href 属性值。
4.href and '/search/' in href 这个条件表达式的含义是:首先检查 href 是否存在(即不为 None),然后检查 '/search/' 是否包含在 href 字符串中。只有当这两个条件都满足时,这个 a 标签才会被选中。
a_type_tag同理。
在循环遍历的每个dl标签中,如果title,author,type都存在的话,就将这三者存储为三元组,并追加到列表中:
if title and author and type_:
novel_list.append([title, author, type_])
生成的三元组列表如下所示:

d.将三元组列表保存至excel表格中:
def save_to_excel(self, data):
"""将爬取到的数据保存至本地excel表格"""
df = pd.DataFrame(data, columns=['小说', '作者', '类别'])
df.to_excel('novel_information.xlsx', index=False)
print(f"保存成功!!!")
e.实现自动翻页:
我们发现:url后面拼接参数?page=xx就可以实现自动翻页,我们需要一个for循环来实现: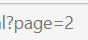
def page_turning(self):
"""实现自动翻页"""
if not self.url:
print("未提供有效的 URL,请检查输入。")
return
print(f"正在保存......")
novel_result = []
for i in range(1, self.page):
base_url = f'{self.url}?page={i}'
novel = self.get_novel(base_url)
novel_result.extend(novel)
self.save_to_excel(novel_result)
将拼接好的base_url作为参数传给get_novel()方法就可以爬取每一页了。
f.主程序块
主程序块(if name == 'main':)是Python脚本的执行入口:
1.脚本自执行:当文件被直接运行时(如 python script.py),块内代码会自动执行
2.模块化隔离:当文件被其他模块导入时,块内代码不会自动运行
在主程序块中传入url和想要翻取的页数:
if __name__ == '__main__':
url = 'https://rrbook.net/all.html'
page = 3
spider = NovelSpider(url, page)
spider.page_turning()
源代码如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page
def get_novel(self, url: str):
"""获取文章信息的方法"""
try:
response = requests.get(url, headers=self.headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
novel_list = []
dl_tag = soup.find_all('dl')
for dl in dl_tag:
# 获取小说名称
a_title_tag = dl.find('a', class_="bigpic-book-name")
title = a_title_tag.text if a_title_tag.text else ""
# 获取小说作者
a_author_tag = dl.find('a', href=lambda href: href and '/search/' in href)
author = a_author_tag.text if a_author_tag.text else ""
# 获取小说的类别
a_type_tag = dl.find('a', href=lambda href: href and '/lists/' in href)
type_ = a_type_tag.text if a_type_tag.text else ""
if title and author and type_:
novel_list.append([title, author, type_])
return novel_list
except requests.RequestException as e:
print(f'请求出现 {e} 错误!!!')
except Exception as e:
print(f'出现{e}错误!!!')
def save_to_excel(self, data):
"""将爬取到的数据保存至本地excel表格"""
df = pd.DataFrame(data, columns=['小说', '作者', '类别'])
df.to_excel('novel_information.xlsx', index=False)
print(f"保存成功!!!")
def page_turning(self):
"""实现自动翻页"""
if not self.url:
print("未提供有效的 URL,请检查输入。")
return
print(f"正在保存......")
novel_result = []
for i in range(1, self.page):
base_url = f'{self.url}?page={i}'
novel = self.get_novel(base_url)
novel_result.extend(novel)
self.save_to_excel(novel_result)
if __name__ == '__main__':
url = 'https://rrbook.net/all.html'
page = 3 # 想爬多少页可以自己选
spider = NovelSpider(url, page)
spider.page_turning()
效果展示:
爬取10页:

优化后的代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
def get_tag_text(tag):
"""辅助函数:获取标签文本,若标签不存在则返回空字符串"""
return tag.text if tag else ""
class NovelSpider:
"""
全书网小说爬虫爬取小说名称
"""
def __init__(self, url: str = None, page: int = 2):
self.url = url
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60'
}
self.page = page
def get_novel(self, url: str) -> list[tuple[str, str, str]]:
try:
response = requests.get(url, headers=self.headers)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
return [
(get_tag_text(dl.find('a', class_="bigpic-book-name")),
get_tag_text(dl.find('a', href=lambda href: href and '/search/' in href)),
get_tag_text(dl.find('a', href=lambda href: href and '/lists/' in href)))
for dl in soup.find_all('dl')
if get_tag_text(dl.find('a', class_="bigpic-book-name"))
and get_tag_text(dl.find('a', href=lambda href: href and '/search/' in href))
and get_tag_text(dl.find('a', href=lambda href: href and '/lists/' in href))
]
except requests.RequestException as e:
print(f'请求出现 {e} 错误!!!')
except Exception as e:
print(f'出现 {e} 错误!!!')
return []
def save_to_excel(self, data: list[tuple[str, str, str]]):
"""将爬取到的数据保存至本地excel表格"""
df = pd.DataFrame(data, columns=['小说', '作者', '类别'])
df.to_excel('novel_information.xlsx', index=False)
print("保存成功!!!")
def page_turning(self):
"""实现自动翻页"""
if not self.url:
print("未提供有效的 URL,请检查输入。")
return
print("正在保存......")
novel_result = [novel for i in range(1, self.page)
for novel in self.get_novel(f'{self.url}?page={i}')]
self.save_to_excel(novel_result)
if __name__ == '__main__':
url = 'https://rrbook.net/all.html'
page = 11
spider = NovelSpider(url, page)
spider.page_turning()
优化点说明:
1.辅助函数:定义了 get_tag_text 辅助函数,避免代码中重复出现获取标签文本的逻辑,提高代码复用性。
2.列表推导式: 在 get_novel 方法中,使用列表推导式替代传统的 for 循环,使代码更简洁。 在 page_turning 方法中,同样使用列表推导式来合并各页的小说数据。
3.异常处理细化:在 get_novel 方法中,将 requests 请求异常单独处理,这样能更清晰地定位问题。
4.参数类型提示:为 save_to_excel 方法的参数添加类型提示,增强代码可读性。
5.URL 有效性检查:在 page_turning 方法中添加了对 url 是否有效的检查,避免无效请求。
python爬虫爬取小说网站的更多相关文章
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- python爬虫--爬取某网站电影信息并写入mysql数据库
书接上文,前文最后提到将爬取的电影信息写入数据库,以方便查看,今天就具体实现. 首先还是上代码: # -*- coding:utf-8 -*- import requests import re im ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 使用python爬虫爬取链家潍坊市二手房项目
使用python爬虫爬取链家潍坊市二手房项目 需求分析 需要将潍坊市各县市区页面所展示的二手房信息按要求爬取下来,同时保存到本地. 流程设计 明确目标网站URL( https://wf.lianjia ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
随机推荐
- Q:以非root用户编辑定时任务报错You are not allowed to use this program(crontab)
编辑定时删除文件任务时报错 crontab -e 编辑定时任务时报错,如下图所示 问题原因:/etc/cron.allow中没有添加对应的用户名解决办法:切换到root用户,在/etc/cron.al ...
- CTFHub-RCE漏洞wp
引言 题目共有如下类型 什么是RCE漏洞 RCE漏洞,全称是Remote Code Execution漏洞,翻译成中文就是远程代码执行漏洞.顾名思义,这是一种安全漏洞,允许攻击者在受害者的系统上远程执 ...
- 库卡机器人KR240电源模块维修思路讲解
一.库卡机器人KR240电源模块故障诊断 故障诊断是维修过程中的关键步骤.使用库卡提供的诊断工具或软件,对库卡机器人KR240电源模块进行故障诊断.重点关注电源供应.输出电压.电流等关键参数.通过诊断 ...
- 库卡机器人维修常见报警代码KSS故障修复
对库卡机器人工作中一些细节和一些安全的措施有所了解才能防患于未然.库卡机器人故障排查可通过观察KUKA机械手报警代码得知,故障代码以及原因有: --kuka机械臂提示文字KSS 0121:电流过大 原 ...
- Oracle DBA末日or重生?不会APEX=淘汰!
残酷现实:传统DBA正在消失 "只会调优SQL的DBA,正在沦为数据库修理工!" 掌握APEX的DBA,薪资翻3倍,秒变企业核心资产! 一.DBA的死刑通知书 1. 云+AI:直接 ...
- java 8 lamdba 表达式list集合的BigDecimal求和操作
- autMan奥特曼机器人-narkPro对接autMan内置容器
前言 这里以NarkPro为例,其他登陆工具自测.下面是以vc1为例展开说明 一.创建autMan虚拟容器vc1 理论上来说autMan可以创建无数个虚拟容器,即相当于你创建无数个青龙容器 二.创建系 ...
- C#/.NET/.NET Core技术前沿周刊 | 第 28 期(2025年2.24-2.28)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录.追踪C#/.NET/.NET Core领域.生态的每周最新.最实用.最有价值的技术文章.社区动态.优质项目和学习资源等. ...
- 【编程思维】临近实施 WPF 下拉框闪烁问题!!
私以为架构是业务开发的发展历史,顺应大方向而生,再为贴切时刻的用户需求,持续微改动. 我本以为了解这个软件的架构没甚意思,加快的开发速度不能过渡到下一个别的软件去: 却不知以小窥大,关键还是计算机思维 ...
- RealityCapture重建试验
一.使用已有数据集 (一)小型物件(官网) 输入:Camera_Lubitel2_studio "Lubitel Camera" consisting of 72 images 地 ...