Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改
修改一:修改爬虫执行方式
之前爬虫的执行 是通过在终端输入命令:scrapy crawl spiderName 执行
缺点:
1、需要记住并输入命令;
2、需要在终端切换到爬虫上一级目录下执行。
创建执行入口
如图
代码如下
# FileName : RunSpider.py
# Author : Adil
# DateTime : 2018/12/4 2:51 PM
# SoftWare : PyCharm from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # 此处添加 执行爬虫 名字,具体可以查看 源码
process.crawl('JdwSpider') process.start()
修改二:修改图片存放路径
之前是在执行路径下依照spiderName 创建了一个文件夹,用来存放图片。
缺点:
1、每次执行爬虫所有图片都会存放在该文件下,日积月累,图片会越来越多,不方便查找和归类
创建新的文件路径
根据爬取日期创建文件进而分类,方便查看不同时间对应的爬取结果
展示结果如下:

修改三:数据增加爬取时间
如图,方便以爬取时间进行区分爬取内容。
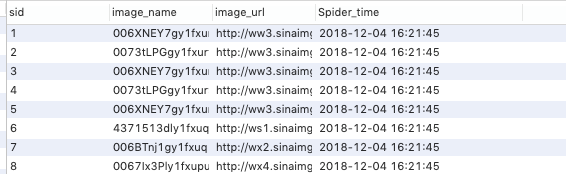
最后修改后代码如下:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import urllib
import time
import common.DBHandle as DBHandle class JiandanwPipeline(object): def __init__(self):
'''
初始化文件路径及 爬取时间
'''
# 获取当前路径
currentPath = os.getcwd()
# 拼接图片存放路径
file_path = os.path.join(currentPath, 'JdwSpider')
# 增加 按日期创建文件
localTime = time.localtime(time.time())
localTimeStrs = time.strftime("%Y-%m-%d %H:%M:%S", localTime)
# 再次拼接路径
file_path = os.path.join(file_path, localTimeStrs)
if not os.path.exists(file_path):
os.makedirs(file_path)
# 初始化 两个 变量,方便 后面的 方法使用
self.file_path = file_path
self.localTimeStrs = localTimeStrs
# 数据库连接 这里的 数据库信息,因为是本地数据库,后面如果是公司数据库 不方便透露的话,可以存放到配置文件中
host = '127.0.0.1'
username = 'adil'
password = 'helloyyj'
database = 'AdilTest'
port = 3306
# 实例化 数据库 连接
self.DbHandle = DBHandle.DataBaseHandle(host, username, password, database, port) def process_item(self, item, spider):
''' 爬虫文件数据处理函数 ''' # 这里是一页 算一个 item ,所以如果 将 文件信息 写在这里,会导致一页创建一次,所以 放在初始化函数内进行
# # 获取当前路径
# currentPath = os.getcwd()
# # 拼接图片存放路径
# file_path = os.path.join(currentPath, spider.name)
#
# # 增加 按日期创建文件
# localTime = time.localtime(time.time())
# localTimeStrs = time.strftime("%Y-%m-%d %H:%M:%S", localTime)
# # 再次拼接路径
# file_path = os.path.join(file_path, localTimeStrs)
#
# if not os.path.exists(file_path):
# os.makedirs(file_path) for image_url in item['image_urls']:
# 截图图片链接
list_name = image_url.split('/')
# 获取图片名称
file_name = list_name[len(list_name) - 1] # 图片名称
# 补全图片路径
path_name = os.path.join(self.file_path,file_name)
# 获取有效的url 因为 image_url = //wx4.sinaimg.cn/mw600/66b3de17gy1fxo6jis4iej21ma0u0x6r.jpg
image_url = 'http:' + image_url
# 此处执行 数据库插入,将 图片名称、url 插入到数据库 注意 这里的 values('占位符 一定要用 引号引起来,要不然执行不成功,血的教训')
sql = "insert into JdwSpider(image_name,image_url,Spider_time) values ('%s','%s','%s')" % (file_name,image_url,self.localTimeStrs)
# 如果不执行插入,可以注释改该行代码
self.DbHandle.insertDB(sql) # 图片保存
with open(path_name, 'wb') as file_writer:
conn = urllib.request.urlopen(image_url) # 下载图片
# 保存图片
file_writer.write(conn.read())
file_writer.close() return item def close_spider(self,spider):
''' 定义爬虫结束处理函数 此处会在 爬虫结束后执行该方法 '''
# 关闭数据库,
print('****'*50)
print('数据库关闭')
self.DbHandle.closeDb()
Python Scrapy 爬取煎蛋网妹子图实例(二)的更多相关文章
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- scrapy从安装到爬取煎蛋网图片
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/pip install wheelpip install lxmlpip install pyopens ...
- 爬虫实例——爬取煎蛋网OOXX频道(反反爬虫——伪装成浏览器)
煎蛋网在反爬虫方面做了不少工作,无法通过正常的方式爬取,比如用下面这段代码爬取无法得到我们想要的源代码. import requests url = 'http://jandan.net/ooxx' ...
随机推荐
- Vue基础进阶 之 Vue生命周期与钩子函数
Vue生命周期 Vue生命周期:Vue实例从创建到销毁的过程,称为Vue的生命周期: Vue生命周期示意图:https://cn.vuejs.org/v2/guide/instance.html#生命 ...
- NATS—基础介绍
1. 介绍 NATS(Message bus): 从CloudFoundry的总架构图看,位于各模块中心位置的是一个叫nats的组件.NATS是由CloudFoundry的架构师Derek开发的一个开 ...
- glibc 2.x release note
glibc 2.x release note,参见: https://sourceware.org/glibc/wiki/Glibc%20Timeline https://www.gnu.org/so ...
- ubuntu----VMware 鼠标自由切换问题及主机虚拟机共享剪切板问题
VMware 安装了Ubuntu之后,在正常安装了VMware tools后,仍然不能正常的在Ubuntu与物理机之间自由的切换,每次都要按下ctrl+Alt,而且鼠标指针会经常性的离奇的失灵 解决方 ...
- 并发 --- 2 进程的方法,进程锁 守护进程 数据共享 进程队列, joinablequeue模型
一.进程的其他方法 1. .name 进程名 (可指定) 2. .pid 进程号 3. os.getpid 在什么位置就是什么的进程号 4. .is ...
- 复旦大学2016--2017学年第二学期高等代数II期末考试情况分析
一.期末考试成绩班级前十五名 林晨(93).朱民哲(92).何陶然(91).徐钰伦(91).吴嘉诚(91).于鸿宝(91).宁盛臻(90).杨锦文(89).占文韬(88).章俊鑫(87).颜匡萱(87 ...
- MySql 语句收集
目录 =与:=区别 序列号: 分组: 子查询分组: 同数据库表数据迁移 存储过程 参考: =与:=区别 = 只有在set和update时才是和:=一样,赋值的作用,其它都是等于的作用.鉴于此,用变量实 ...
- c 语言中宏定义和定义全局变量的区别
宏定义和定义全局变量的区别: 1 作用时间不同. 宏定义在编译期间即会使用并替换,而全局变量要到运行时才可以. 2 本质类型不同. 宏定义的只是一段字符,在编译的时候被替换到引用的位置.在运行中是没有 ...
- 使用python+ffmpeg+youtube-dl下载youtube上的视频
一.准备工作 1.安装python,详见https://www.cnblogs.com/cnwuchao/p/10562416.html 2.安装ffmpeg,详见https://www.cnblog ...
- js转义和反转义html
本文地址: http://www.cnblogs.com/daysme/p/7100553.html 下面的代码网上常用有,但不是想要的. JS实现HTML标签转义及反转义 http://blog.c ...