Kubernetes容器日志收集
日志采集方式
日志从传统方式演进到容器方式的过程就不详细讲了,可以参考一下这篇文章Docker日志收集最佳实践,由于容器的漂移、自动伸缩等特性,日志收集也就必须使用新的方式来实现,Kubernetes官方给出的方式基本是这三种:原生方式、DaemonSet方式和Sidecar方式。
1.原生方式:使用 kubectl logs 直接在查看本地保留的日志,或者通过docker engine的 log driver 把日志重定向到文件、syslog、fluentd等系统中。
2.DaemonSet方式:在K8S的每个node上部署日志agent,由agent采集所有容器的日志到服务端。
3.Sidecar方式:一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。
三种方式都有利有弊,没有哪种方式能够完美的解决100%问题的,所以要根据场景来贴合。
一、原生方式
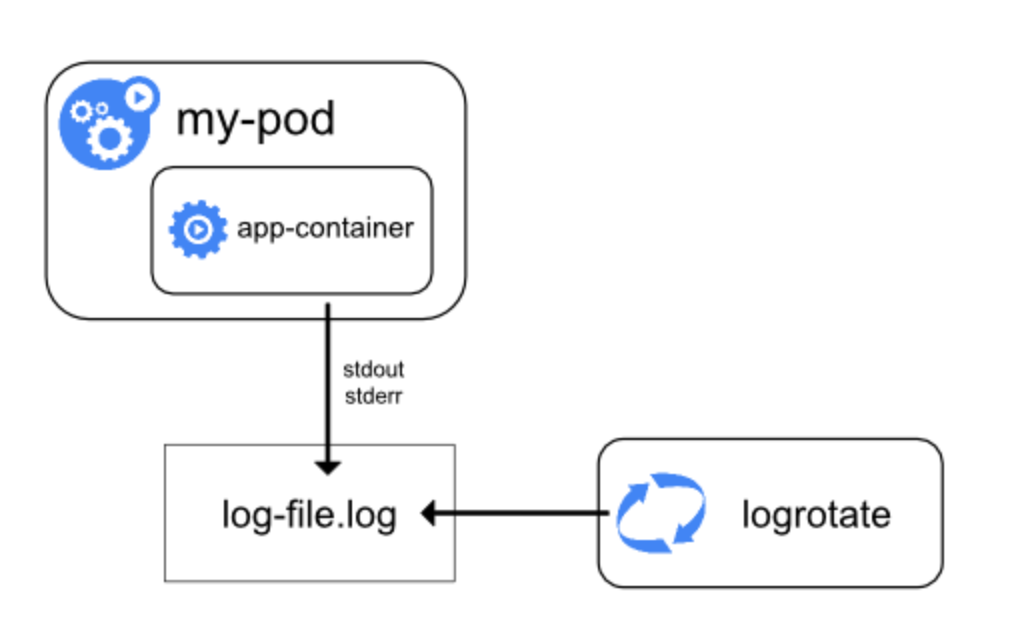
简单的说,原生方式就是直接使用kubectl logs来查看日志,或者将docker的日志通过日志驱动来打到syslog、journal等去,然后再通过命令来排查,这种方式最好的优势就是简单、资源占用率低等,但是,在多容器、弹性伸缩情况下,日志的排查会十分困难,仅仅适用于刚开始研究Kubernetes的公司吧。不过,原生方式确实其他两种方式的基础,因为它的两种最基础的理念,daemonset和sidecar模式都是基于这两种方式而来的。
1.1 控制台stdout方式
这种方式是daemonset方式的基础。将日志全部输出到控制台,然后docker开启journal,然后就能在/var/log/journal下面看到二进制的journal日志,如果要查看二进制的日志的话,可以使用journalctl来查看日志:journalctl -u docker.service -n 1 --no-pager -o json -o json-pretty
{
"__CURSOR" : "s=113d7df2f5ff4d0985b08222b365c27a;i=1a5744e3;b=05e0fdf6d1814557939e52c0ac7ea76c;m=5cffae4cd4;t=58a452ca82da8;x=29bef852bcd70ae2",
"__REALTIME_TIMESTAMP" : "1559404590149032",
"__MONOTONIC_TIMESTAMP" : "399426604244",
"_BOOT_ID" : "05e0fdf6d1814557939e52c0ac7ea76c",
"PRIORITY" : "6",
"CONTAINER_ID_FULL" : "f2108df841b1f72684713998c976db72665f353a3b4ea17cd06b5fc5f0b8ae27",
"CONTAINER_NAME" : "k8s_controllers_master-controllers-dev4.gcloud.set_kube-system_dcab37be702c9ab6c2b17122c867c74a_1",
"CONTAINER_TAG" : "f2108df841b1",
"CONTAINER_ID" : "f2108df841b1",
"_TRANSPORT" : "journal",
"_PID" : "6418",
"_UID" : "0",
"_GID" : "0",
"_COMM" : "dockerd-current",
"_EXE" : "/usr/bin/dockerd-current",
"_CMDLINE" : "/usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current --init-path=/usr/libexec/docker/docker-init-current --seccomp-profile=/etc/docker/seccomp.json --selinux-enabled=false --log-driver=journald --insecure-registry hub.paas.kjtyun.com --insecure-registry hub.gcloud.lab --insecure-registry 172.30.0.0/16 --log-level=warn --signature-verification=false --max-concurrent-downloads=20 --max-concurrent-uploads=20 --storage-driver devicemapper --storage-opt dm.fs=xfs --storage-opt dm.thinpooldev=/dev/mapper/docker--vg-docker--pool --storage-opt dm.use_deferred_removal=true --storage-opt dm.use_deferred_deletion=true --mtu=1450",
"_CAP_EFFECTIVE" : "1fffffffff",
"_SYSTEMD_CGROUP" : "/system.slice/docker.service",
"_SYSTEMD_UNIT" : "docker.service",
"_SYSTEMD_SLICE" : "system.slice",
"_MACHINE_ID" : "225adcce13bd233a56ab481df7413e0b",
"_HOSTNAME" : "dev4.gcloud.set",
"MESSAGE" : "I0601 23:56:30.148153 1 event.go:221] Event(v1.ObjectReference{Kind:\"DaemonSet\", Namespace:\"openshift-monitoring\", Name:\"node-exporter\", UID:\"f6d2bdc1-6658-11e9-aca2-fa163e938959\", APIVersion:\"apps/v1\", ResourceVersion:\"15378688\", FieldPath:\"\"}): type: 'Normal' reason: 'SuccessfulCreate' Created pod: node-exporter-hvrpf",
"_SOURCE_REALTIME_TIMESTAMP" : "1559404590148488"
}
在上面的json中,_CMDLINE以及其他字段占用量比较大,而且这些没有什么意义,会导致一条简短的日志却被封装成多了几十倍的量,所以的在日志量特别大的情况下,最好进行一下字段的定制,能够减少就减少。
我们一般需要的字段是CONTAINER_NAME以及MESSAGE,通过CONTAINER_NAME可以获取到Kubernetes的namespace和podName,比如CONTAINER_NAME为k8s_controllers_master-controllers-dev4.gcloud.set_kube-system_dcab37be702c9ab6c2b17122c867c74a_1的时候
container name in pod: controllers
**pod name: **master-controllers-dev4.gcloud.set
namespace: kube-system
**pod uid: **dcab37be702c9ab6c2b17122c867c74a_1
1.2 新版本的subPathExpr
journal方式算是比较标准的方式,如果采用hostPath方式,能够直接将日志输出这里。这种方式唯一的缺点就是在旧Kubernetes中无法获取到podName,但是最新版的Kubernetes1.14的一些特性subPathExpr,就是可以将目录挂载的时候同时将podName写进目录里,但是这个特性仍旧是alpha版本,谨慎使用。
简单说下实现原理:容器中填写的日志目录,挂载到宿主机的/data/logs/namespace/service_name/$(PodName)/xxx.log里面,如果是sidecar模式,则将改目录挂载到sidecar的收集目录里面进行推送。如果是宿主机安装fluentd模式,则需要匹配编写代码实现识别namespace、service_name、PodName等,然后发送到日志系统。
可参考:https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20181029-volume-subpath-env-expansion.md
日志落盘参考细节:
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
...
volumeMounts:
- name: workdir1
mountPath: /logs
subPathExpr: $(POD_NAME)
我们主要使用了在Pod里的主容器挂载了一个fluent-agent的收集器,来将日志进行收集,其中我们修改了Kubernetes-Client的源码使之支持subPathExpr,然后发送到日志系统的kafka。这种方式能够处理多种日志的收集,比如业务方的日志打到控制台了,但是jvm的日志不能同时打到控制台,否则会发生错乱,所以,如果能够将业务日志挂载到宿主机上,同时将一些其他的日志比如jvm的日志挂载到容器上,就可以使用该种方式。
{
"_fileName":"/data/work/logs/epaas_2019-05-22-0.log",
"_sortedId":"660c2ce8-aacc-42c4-80d1-d3f6d4c071ea",
"_collectTime":"2019-05-22 17:23:58",
"_log":"[33m2019-05-22 17:23:58[0;39m |[34mINFO [0;39m |[34mmain[0;39m |[34mSpringApplication.java:679[0;39m |[32mcom.hqyg.epaas.EpaasPortalApplication[0;39m | The following profiles are active: dev",
"_domain":"rongqiyun-dev",
"_podName":"aofjweojo-5679849765-gncbf",
"_hostName":"dev4.gcloud.set"
}
二、Daemonset方式
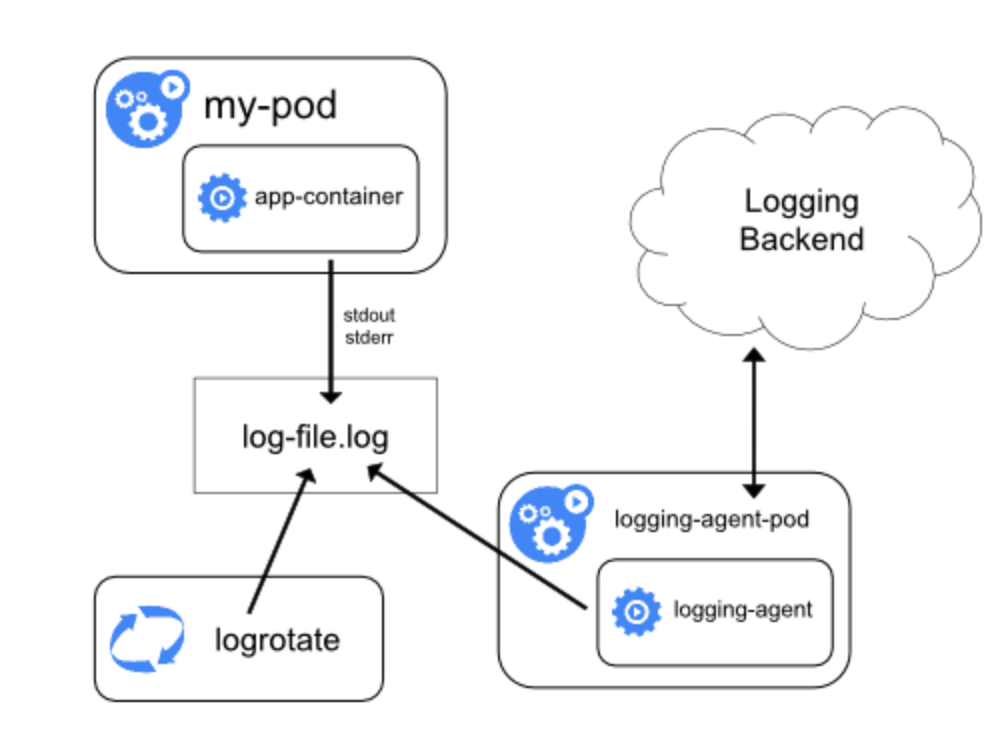
daemonset方式也是基于journal,日志使用journal的log-driver,变成二进制的日志,然后在每个node节点上部署一个日志收集的agent,挂载/var/log/journal的日志进行解析,然后发送到kafka或者es,如果节点或者日志量比较大的话,对es的压力实在太大,所以,我们选择将日志推送到kafka。容器日志收集普遍使用fluentd,资源要求较少,性能高,是目前最成熟的日志收集方案,可惜是使用了ruby来写的,普通人根本没时间去话时间学习这个然后进行定制,好在openshift中提供了origin-aggregated-logging方案。
我们可以通过fluent.conf来看origin-aggregated-logging做了哪些工作,把注释,空白的一些东西去掉,然后我稍微根据自己的情况修改了下,结果如下:
@include configs.d/openshift/system.conf
设置fluent的日志级别
@include configs.d/openshift/input-pre-*.conf
最主要的地方,读取journal的日志
@include configs.d/dynamic/input-syslog-*.conf
读取syslog,即操作日志
<label @INGRESS>
@include configs.d/openshift/filter-retag-journal.conf
进行匹配
@include configs.d/openshift/filter-k8s-meta.conf
获取Kubernetes的相关信息
@include configs.d/openshift/filter-viaq-data-model.conf
进行模型的定义
@include configs.d/openshift/filter-post-*.conf
生成es的索引id
@include configs.d/openshift/filter-k8s-record-transform.conf
修改日志记录,我们在这里进行了字段的定制,移除了不需要的字段
@include configs.d/openshift/output-applications.conf
输出,默认是es,如果想使用其他的比如kafka,需要自己定制
</label>
当然,细节上并没有那么好理解,换成一步步理解如下:
1. 解析journal日志
origin-aggregated-logging会将二进制的journal日志中的CONTAINER_NAME进行解析,根据匹配规则将字段进行拆解
"kubernetes": {
"container_name": "fas-dataservice-dev-new",
"namespace_name": "fas-cost-dev",
"pod_name": "fas-dataservice-dev-new-5c48d7c967-kb79l",
"pod_id": "4ad125bb7558f52e30dceb3c5e88dc7bc160980527356f791f78ffcaa6d1611c",
"namespace_id": "f95238a6-3a67-11e9-a211-20040fe7b690"
}
2. es封装
主要用的是elasticsearch_genid_ext插件,写在了filter-post-genid.conf上。
3. 日志分类
通过origin-aggregated-logging来收集journal的日志,然后推送至es,origin-aggregated-logging在推送过程中做了不少优化,即适应高ops的、带有等待队列的、推送重试等,详情可以具体查看一下。
还有就是对日志进行了分类,分为三种:
(1).操作日志(在es中以.operations匹配的),记录了对Kubernetes的操作
(2).项目日志(在es中以project匹配的),业务日志,日志收集中最重要的
(3).孤儿日志(在es中以.orphaned.*匹配的),没有namespace的日志都会打到这里
4. 日志字段定制
经过origin-aggregated-logging推送至后采集的一条日志如下:
{
"CONTAINER_TAG": "4ad125bb7558",
"docker": {
"container_id": "4ad125bb7558f52e30dceb3c5e88dc7bc160980527356f791f78ffcaa6d1611c"
},
"kubernetes": {
"container_name": "fas-dataservice-dev-new",
"namespace_name": "fas-cost-dev",
"pod_name": "fas-dataservice-dev-new-5c48d7c967-kb79l",
"pod_id": "4ad125bb7558f52e30dceb3c5e88dc7bc160980527356f791f78ffcaa6d1611c",
"namespace_id": "f95238a6-3a67-11e9-a211-20040fe7b690"
},
"systemd": {
"t": {
"BOOT_ID": "6246327d7ea441339d6d14b44498b177",
"CAP_EFFECTIVE": "1fffffffff",
"CMDLINE": "/usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtime=docker-runc --exec-opt native.cgroupdriver=systemd --userland-proxy-path=/usr/libexec/docker/docker-proxy-current --init-path=/usr/libexec/docker/docker-init-current --seccomp-profile=/etc/docker/seccomp.json --selinux-enabled=false --log-driver=journald --insecure-registry hub.paas.kjtyun.com --insecure-registry 10.77.0.0/16 --log-level=warn --signature-verification=false --bridge=none --max-concurrent-downloads=20 --max-concurrent-uploads=20 --storage-driver devicemapper --storage-opt dm.fs=xfs --storage-opt dm.thinpooldev=/dev/mapper/docker--vg-docker--pool --storage-opt dm.use_deferred_removal=true --storage-opt dm.use_deferred_deletion=true --mtu=1450",
"COMM": "dockerd-current",
"EXE": "/usr/bin/dockerd-current",
"GID": "0",
"MACHINE_ID": "0096083eb4204215a24efd202176f3ec",
"PID": "17181",
"SYSTEMD_CGROUP": "/system.slice/docker.service",
"SYSTEMD_SLICE": "system.slice",
"SYSTEMD_UNIT": "docker.service",
"TRANSPORT": "journal",
"UID": "0"
}
},
"level": "info",
"message": "\tat com.sun.proxy.$Proxy242.execute(Unknown Source)",
"hostname": "host11.rqy.kx",
"pipeline_metadata": {
"collector": {
"ipaddr4": "10.76.232.16",
"ipaddr6": "fe80::a813:abff:fe66:3b0c",
"inputname": "fluent-plugin-systemd",
"name": "fluentd",
"received_at": "2019-05-15T09:22:39.297151+00:00",
"version": "0.12.43 1.6.0"
}
},
"@timestamp": "2019-05-06T01:41:01.960000+00:00",
"viaq_msg_id": "NjllNmI1ZWQtZGUyMi00NDdkLWEyNzEtMTY3MDQ0ZjEyZjZh"
}
可以看出,跟原生的journal日志类似,增加了几个字段为了写进es中而已,总体而言,其他字段并没有那么重要,所以我们对其中的字段进行了定制,以减少日志的大小,定制化字段之后,一段日志的输出变为(不是同一段,只是举个例子):
{
"hostname":"dev18.gcloud.set",
"@timestamp":"2019-05-17T04:22:33.139608+00:00",
"pod_name":"istio-pilot-8588fcb99f-rqtkd",
"appName":"discovery",
"container_name":"epaas-discovery",
"domain":"istio-system",
"sortedId":"NjA3ODVhODMtZDMyYy00ZWMyLWE4NjktZjcwZDMwMjNkYjQ3",
"log":"spiffluster.local/ns/istio-system/sa/istio-galley-service-account"
}
5.部署
最后,在node节点上添加logging-infra-fluentd: "true"的标签,就可以在namespace为openshift-logging中看到节点的收集器了。
logging-fluentd-29p8z 1/1 Running 0 6d
logging-fluentd-bpkjt 1/1 Running 0 6d
logging-fluentd-br9z5 1/1 Running 0 6d
logging-fluentd-dkb24 1/1 Running 1 5d
logging-fluentd-lbvbw 1/1 Running 0 6d
logging-fluentd-nxmk9 1/1 Running 1 5d
6.关于ip
业务方不仅仅想要podName,同时还有对ip的需求,控制台方式正常上是没有记录ip的,所以这算是一个难点中的难点,我们在kubernetes_metadata_common.rb的kubernetes_metadata中添加了 'pod_ip' => pod_object['status']['podIP'],最终是有些有ip,有些没有ip,这个问题我们继续排查。
三、Sidecar模式
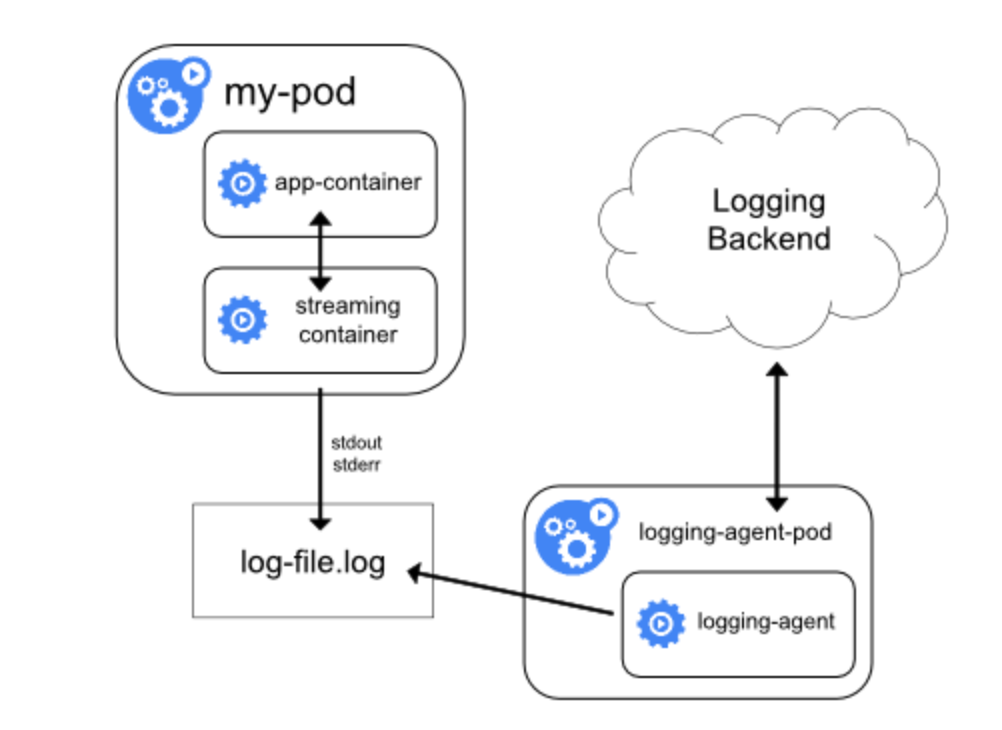
这种方式的好处是能够获取日志的文件名、容器的ip地址等,并且配置性比较高,能够很好的进行一系列定制化的操作,比如使用log-pilot或者filebeat或者其他的收集器,还能定制一些特定的字段,比如文件名、ip地址等。
sidecar模式用来解决日志收集的问题的话,需要将日志目录挂载到宿主机的目录上,然后再mount到收集agent的目录里面,以达到文件共享的目的,默认情况下,使用emptydir来实现文件共享的目的,这里简单介绍下emptyDir的作用。
EmptyDir类型的volume创建于pod被调度到某个宿主机上的时候,而同一个pod内的容器都能读写EmptyDir中的同一个文件。一旦这个pod离开了这个宿主机,EmptyDir中的数据就会被永久删除。所以目前EmptyDir类型的volume主要用作临时空间,比如Web服务器写日志或者tmp文件需要的临时目录。
日志如果丢失的话,会对业务造成的影响不可估量,所以,我们使用了尚未成熟的subPathExpr来实现,即挂载到宿主的固定目录/data/logs下,然后是namespace,deploymentName,podName,再然后是日志文件,合成一块便是/data/logs/${namespace}/${deploymentName}/${podName}/xxx.log。
具体的做法就不在演示了,这里只贴一下yaml文件。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: xxxx
namespace: element-dev
spec:
template:
spec:
volumes:
- name: host-log-path-0
hostPath:
path: /data/logs/element-dev/xxxx
type: DirectoryOrCreate
containers:
- name: xxxx
image: 'xxxxxxx'
volumeMounts:
- name: host-log-path-0
mountPath: /data/work/logs/
subPathExpr: $(POD_NAME)
- name: xxxx-elog-agent
image: 'agent'
volumeMounts:
- name: host-log-path-0
mountPath: /data/work/logs/
subPathExpr: $(POD_NAME)
fluent.conf的配置文件由于保密关系就不贴了,收集后的一条数据如下:
{
"_fileName":"/data/work/logs/xxx_2019-05-22-0.log",
"_sortedId":"660c2ce8-aacc-42c4-80d1-d3f6d4c071ea",
"_collectTime":"2019-05-22 17:23:58",
"_log":"[33m2019-05-22 17:23:58[0;39m |[34mINFO [0;39m |[34mmain[0;39m |[34mSpringApplication.java:679[0;39m |[32mcom.hqyg.epaas.EpaasPortalApplication[0;39m | The following profiles are active: dev",
"_domain":"namespace",
"_ip":"10.128.93.31",
"_podName":"xxxx-5679849765-gncbf",
"_hostName":"dev4.gcloud.set"
}
四、总结
总的来说,daemonset方式比较简单,而且适合更加适合微服务化,当然,不是完美的,比如业务方想把业务日志打到控制台上,但是同时也想知道jvm的日志,这种情况下或许sidecar模式更好。但是sidecar也有不完美的地方,每个pod里都要存在一个日志收集的agent实在是太消耗资源了,而且很多问题也难以解决,比如:主容器挂了,agent还没收集完,就把它给kill掉,这个时候日志怎么处理,业务会不会受到要杀掉才能启动新的这一短暂过程的影响等。所以,我们实际使用中首选daemonset方式,但是提供了sidecar模式让用户选择。
参考:
1.Kubernetes日志官方文档
2.Kubernetes日志采集Sidecar模式介绍
3.Docker日志收集最佳实践
Kubernetes容器日志收集的更多相关文章
- [Kubernetes]容器日志的收集与管理
在开始这篇文章之前,首先要明确一点: Kubernetes 中对容器日志的处理方式,都叫做 cluster-level-logging ,也就是说,这个日志处理系统,与容器, Pod 以及 Node ...
- Kubernetes 常用日志收集方案
Kubernetes 常用日志收集方案 学习了 Kubernetes 集群中监控系统的搭建,除了对集群的监控报警之外,还有一项运维工作是非常重要的,那就是日志的收集. 介绍 应用程序和系统日志可以帮助 ...
- docker容器日志收集方案汇总评价总结
docker日志收集方案有太多,下面截图罗列docker官方给的日志收集方案(详细请转docker官方文档).很多方案都不适合我们下面的系列文章没有说. 经过以下5篇博客的叙述简单说下docker容器 ...
- docker容器日志收集方案(方案N,其他中间件传输方案)
由于docker虚拟化的特殊性导致日志收集方案的多样性和复杂性下面接收几个可能的方案 这个方案各大公司都在用只不过传输方式大同小异 中间件使用kafka是肯定的,kafka的积压与吞吐能力相当强悍 ...
- docker容器日志收集方案(方案一 filebeat+本地日志收集)
filebeat不用多说就是扫描本地磁盘日志文件,读取文件内容然后远程传输. docker容器日志默认记录方式为 json-file 就是将日志以json格式记录在磁盘上 格式如下: { " ...
- docker容器日志收集方案(方案三 filebeat+journald本地日志收集)
其实方案三和方案二日志采集套路一样,但是还是有点差别. 差别就在于日志格式如下: 为了方便对比吧日志贴上来 Nov 16 10:51:58 localhost 939fe968a91d[4721] ...
- docker容器日志收集方案(方案二 filebeat+syslog本地日志收集)
与方案一一样都是把日志输出到本地文件系统使用filebeat进行扫描采集 不同的是输出的位置是不一样的 我们对docker进行如下设置 sudo docker service update --lo ...
- 阿里云ilogtail收集自建Kubernetes容器日志文件
背景 1,k8s属于自建. 2,需要收集应用服务容器里面指定目录的日志. 3,计划收集所有私有云php和nginx日志. 4,日志格式化处理. 思考 1,一个私有云一个Project,还是统一放入一个 ...
- docker容器日志收集方案(方案四,目前使用的方案)
先看数据流图,然后一一给大家解释 这个方案是将日志直接从应用代码中将日志输出到redis中(注意,是应用直接连接redis进行日志输出),redis充当一个缓存中间件有一定的缓存能力,不过有限,因 ...
随机推荐
- (day69)axios、配置ElementUI、配置jQuery和Bootstrap、Django中的CORS问题
目录 一.Vue的ajax插件:axios 二.Django中的CORS跨域问题 (一)同源策略 (二)解决方式(cors模块) 三.Vue配置ElementUI 四.Vue配置jQuery和Boot ...
- Pipe——高性能IO(一)
System.IO.Pipelines是一个新的库,旨在简化在.NET中执行高性能IO的过程.它是一个依赖.NET Standard的库,适用于所有.NET实现. Pipelines诞生于.NET C ...
- 深入理解 Java 数组
- java高并发系列 - 第26篇:学会使用JUC中常见的集合,常看看!
这是java高并发系列第26篇文章. 环境:jdk1.8. 本文内容 了解JUC常见集合,学会使用 ConcurrentHashMap ConcurrentSkipListMap Concurrent ...
- 签名时出错: 未能对** SignTool Error:
项目在vs2010创建,在2017上运行时报签名时出错.......... 解决方法: 右键项目 - 属性-签名 - 创建测试证书 - 密码可以为空-确定
- tomcat8 到idea控制台和servlet乱码问题
作者:晨钟暮鼓c个人微信公众号:程序猿的月光宝盒 1.问题重现 Tomcat8 部署到idea上时候,控制台出现的乱码 如图,本来框出来的是乱码 其中,"测试"这个是在serv ...
- [Spring]:java.lang.NoSuchMethodError: 'java.lang.String javax.annotation.Resource.lookup()'
错误信息 11月 05, 2019 9:32:15 下午 org.springframework.test.context.TestContextManager prepareTestInstance ...
- SpringCloud(七):springcloud-config统一管理配置中心
前言: Spring Cloud Config组件是独立的,不需要注册到eureka.config工作原理是把读取目标到配置拉取到本地缓存一份然后供给其他客户端使用,所以一旦config启动成功,可以 ...
- BurpSuite的基础使用,这个教程有“坑”?
BurpSuite简介 BurpSuite是一款辅助渗透的工具,可以给我们带来许多便利.Burp给我们提供了简单的HTTP抓包改包,数据枚举模块,以及各种安全漏洞的手动式扫描与爬虫式扫描,还有很多经常 ...
- Python 中運算子 + 與 * 的 Overload 方法重載功能
字串 String 原本不能像數值一樣有加減乘除運算,但有例外.例如: >>> 'Good' + 'Morning''GoodMorning' 運算子 + 可將2個字串,串接起來. ...