《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
1.简介
前边宏哥拖拽有提到那个反爬虫机制,加了各种参数,以及加载js脚本文件还是有问题,偶尔宏哥好像发现了解决问题的办法,看到了黎明的曙光,宏哥就说试一下看看行不行,万一实现了。结果宏哥试了结果真的OK啊,但是宏哥第一次运行可以,后边就不行了,然后将编辑器关闭重启,再次运行又可以,宏哥猜测可能是缓冲问题吧,但是具体原因还是没有查到。所以就加更一篇来记录是如何解决的。而且最近有一些爬虫用户私信给宏哥留言:在使用 playwright 的时候,提到 playwright 默认是用无痕模式打开的浏览器,很多网站会有反爬机制,使用无痕模式打开的时候功能无法正常使用。问宏哥有没有好的办法。宏哥答复暂时也没有好办法,也不知道宏哥这种解决方法会不会帮到他们,或者对他们有参考价值。
2.启动浏览器的模式
playwright 提供了 launch_persistent_context 启动浏览器的方法,可以非无痕模式启动浏览器。
无痕模式启动浏览器适合做自动化测试的人员
非无痕模式启动浏览器适合一些爬虫用户人员
2.1无痕模式启动浏览器
launch()方法是无痕模式启动浏览器。
参考代码如下:
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.cnblogs.com/du-hong") # do ....
page.pause()
browser.close()
无痕模式启动浏览器,会在浏览器右上角出现“无痕模式”,如下图所示:

2.2非无痕模式启动浏览器
如果网站被识别或者被监测无痕模式不能使用,那么可以用 launch_persistent_context()方法非无痕模式启动浏览器。
相关参数说明:
- user_data_dir : 用户数据目录,此参数是必须的,可以自定义一个目录
- accept_downloads: 接收下载事件
- headless: 是否设置无头模式
- channel: 指定浏览器类型,默认chromium
参考代码如下:
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"C:\\Users\\DELL\\Desktop\\Chrome\\test",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome"
)
page = browser.new_page()
page.goto("https://www.cnblogs.com/du-hong") # do ....
page.pause()
browser.close()
宏哥发现以上代码运行后,会多出一个空白页。如下图所示:

进入launch_persistent_context方法,发现是因为使用launch_persistent_context方法会自动打开一个tab标签页,后面代码browser.new_page()重新打开了一个新的page对象。所以才会多一个空白页。
解决办法很简单,去掉browser.new_page()代码即可。直接用默认打开发tab标签页对象。
参考代码如下:
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
''' # 3.导入模块
from playwright.sync_api import sync_playwright with sync_playwright() as p: browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"C:\\Users\\DELL\\Desktop\\Chrome\\test",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome"
)
page = browser.pages[0]
page.goto("https://www.cnblogs.com/du-hong") # do ....
page.pause()
browser.close()
运行代码,如下图所示:
3.项目实战
这里宏哥还用之前的那个实例进行演示,也就是在文章最后提到反爬虫的那篇文章的例子:携程旅行,手机号查单页面的一个滑动,进行项目实战。如下图所示:

3.1代码设计
参考前边提到的方法进行代码设计如下:

3.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-10-10
@author: 北京-宏哥 QQ交流群:705269076
公众号:北京宏哥
Project: 《《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇
''' # 3.导入模块
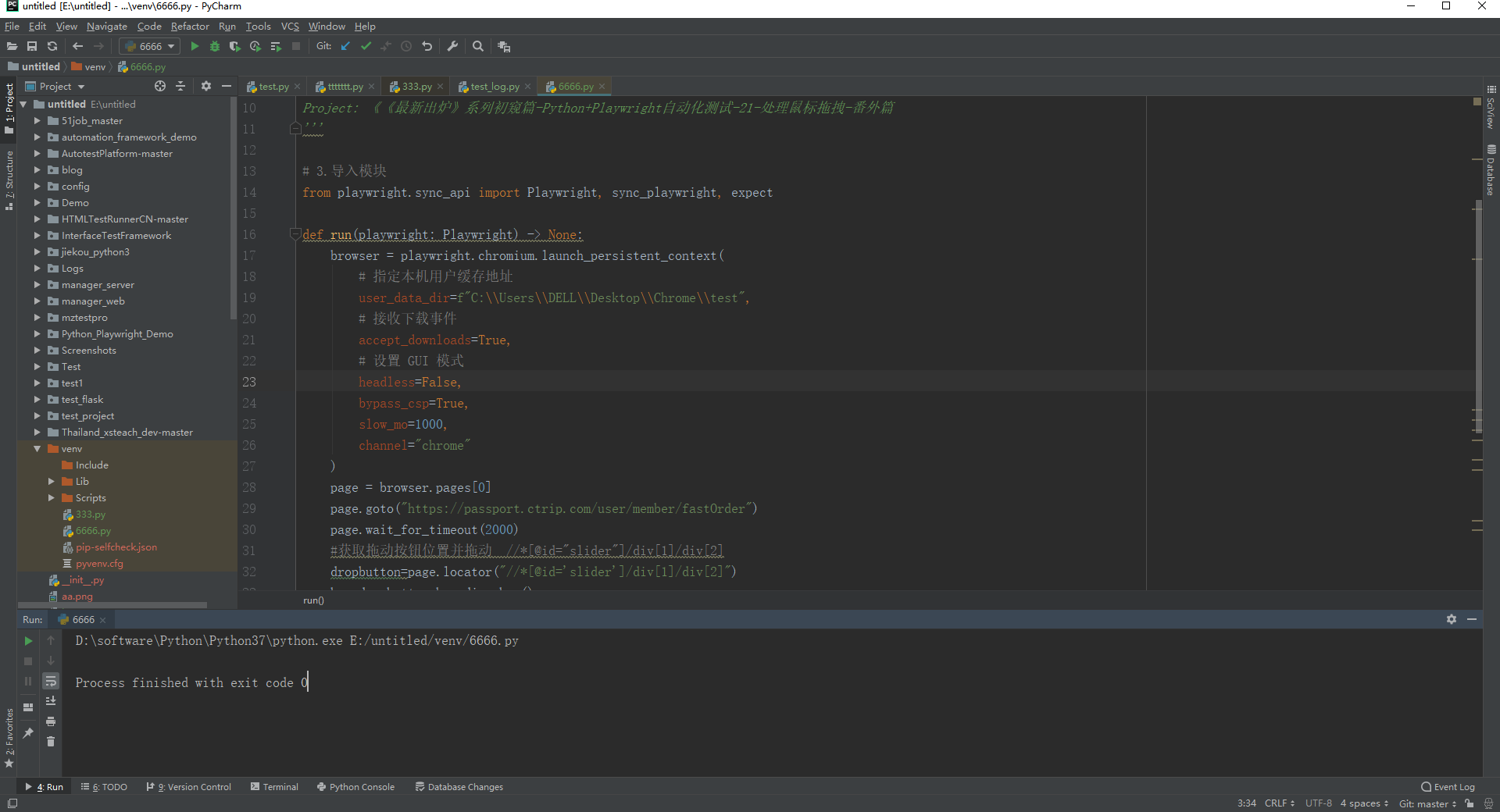
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"C:\\Users\\DELL\\Desktop\\Chrome\\test",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome"
)
page = browser.pages[0]
page.goto("https://passport.ctrip.com/user/member/fastOrder")
page.wait_for_timeout(2000)
#获取拖动按钮位置并拖动 //*[@id="slider"]/div[1]/div[2]
dropbutton=page.locator("//*[@id='slider']/div[1]/div[2]")
box=dropbutton.bounding_box()
page.mouse.move(box['x']+box['width']/2,box['y']+box[ 'height']/2)
page.mouse.down()
mov_x=box['x']+box['width']/2+280
page.mouse.move(mov_x,box['y']+box[ 'height']/2)
page.mouse.up()
page.wait_for_timeout(3000)
browser.close() with sync_playwright() as playwright:
run(playwright)
3.3运行代码
1.运行代码,右键Run'Test',控制台输出,如下图所示:
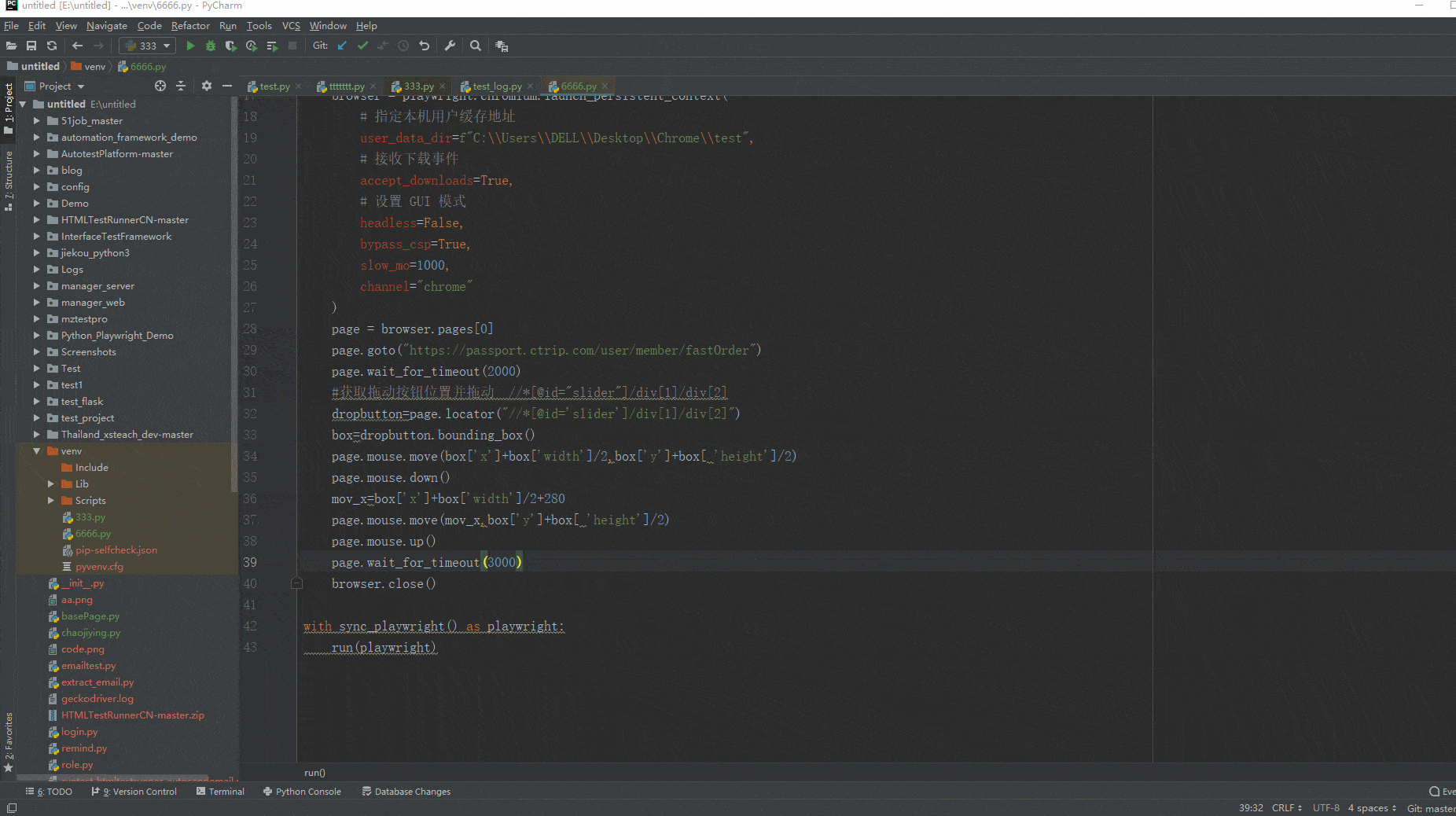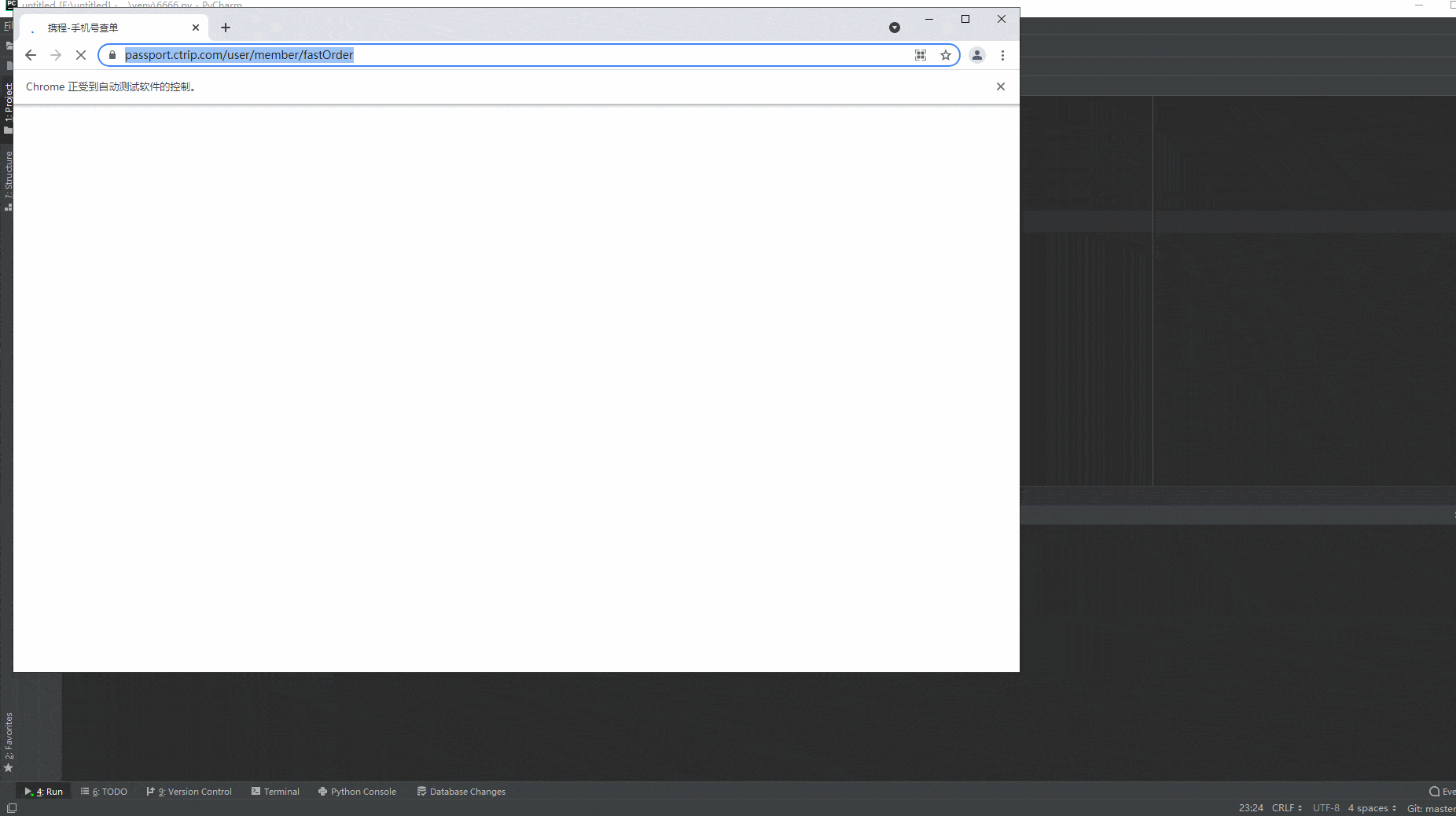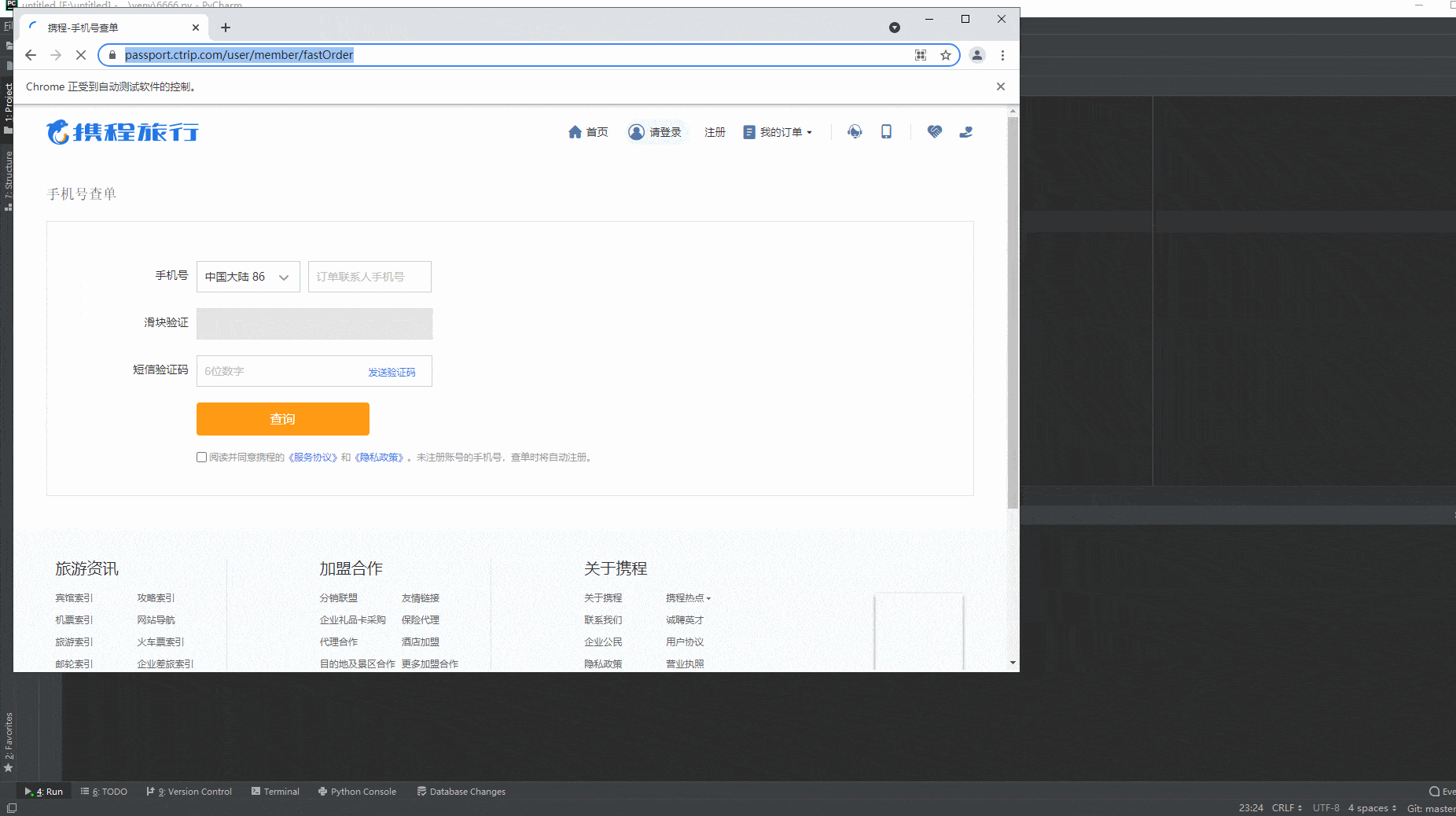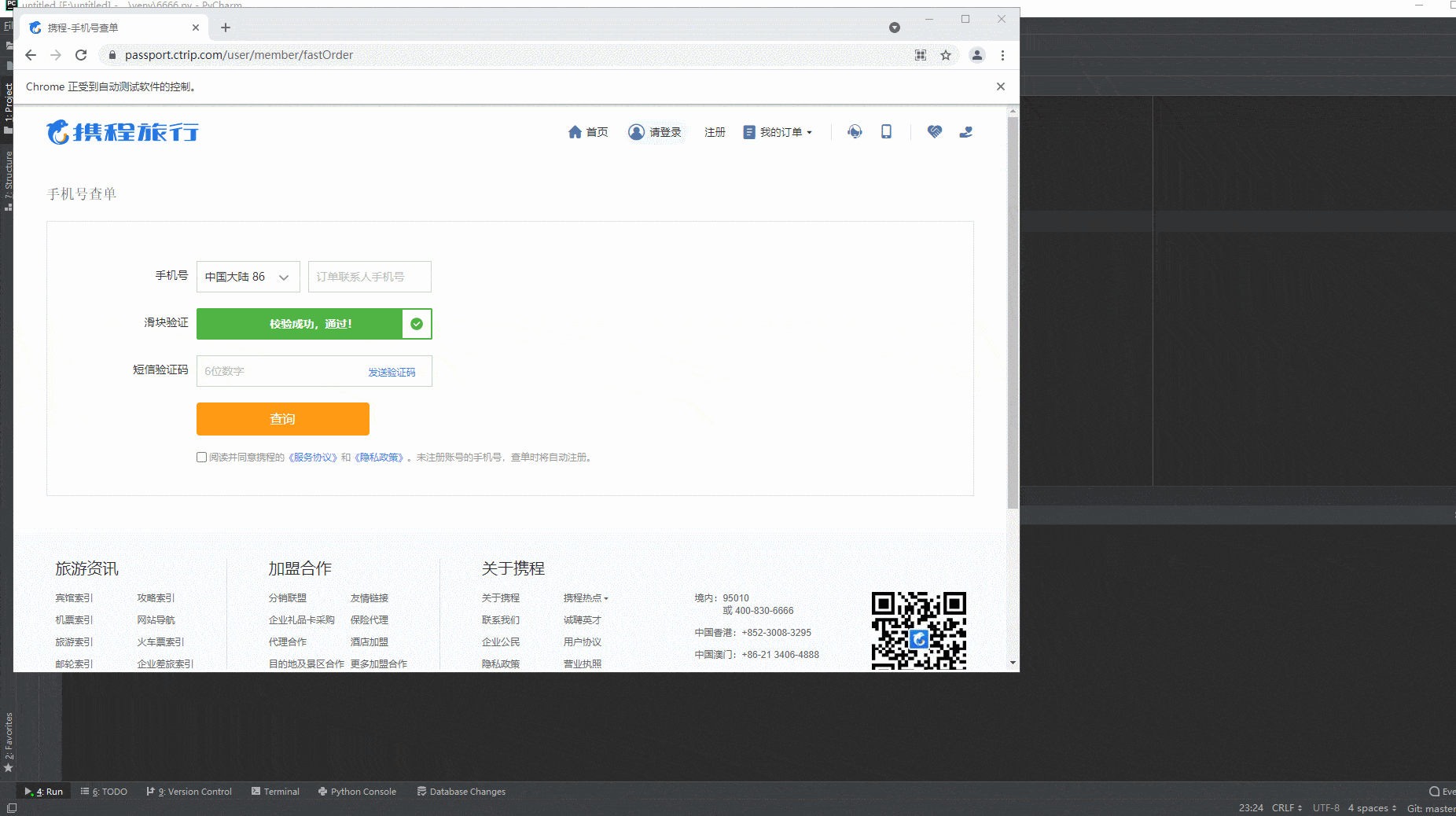
2.运行代码后电脑端的浏览器的动作(可以清楚地的看到滑动后,出现“校验成功,通过”的字样,而不是之前出现的那种反爬虫机制,又弹出选字校验)。如下图所示:
好了,到此大功告成,问题就解决了。
4.小结
1. launch_persistent_context创建的浏览器对象,为什么无法使用browser.new_context()创建上下文?
因为launch_persistent_context字面上意思就已经是一个context上下文对象了,所以无法创建上下文,只能创建page对象。
2.user_data_dir路径参数的作用什么?
user_data_dir是指定浏览器启动的用户数据缓存目录,当指定一个新的目录时,启动浏览器会发现自动生成缓存文件。打开C:\Users\\DELL\Desktop\Chrome\test目录会看到加载的浏览器缓存文件。如下图所示:

3.user_data_dir能不能记住用户登录的状态?
user_data_dir就是你自己定义的打开浏览器保存的用户数据,包含了用户的cookies,所以你只要登录过,就会自动保存。
所以你只要代码打开网站,如果不能通过代码自动登录(可能有一些验证码什么的),你可以断点后手工去登录一次,也会记住cookies。下次代码再打开就不需要登录了。
4.为什么按你的教程,我这个网站就无法保持登录?
能不能保持登录状态,主要看你网站的cookies有效期,有些网站关闭浏览器后就失效了,比如一些银行的网站,你只要关闭浏览器窗口,下次就需要再次登录。
简单来说一句话:你手工去操作一次,关闭浏览器,再打开还要不要登录,如果关闭浏览器需要再次登录,那代码也没法做到保持登录。
有些博客网站,你登录一次,cookies几个月都有效,这种就可以利用缓存的cookies保持登录。
5.为什么网上其他教程user_data_dir写chrome的安装目录?
其实没必要非要写chrome的安装目录"C:\Users\{getpass.getuser()}\AppData\Local\Google\Chrome\UserData"。
如果你写的是系统默认安装目录的用户数据,那你本地浏览器打开后,执行代码就会报错。所以不推荐!
6.默认启动的是chromium浏览器,能不能换成其他的浏览器?
可以通过"channel"参数指定浏览器,可以支持chromium系列:chromium、chrome、chrome-beta、msedge。
7.如何设置窗口最大化?
添加args=['--start-maximized']和no_viewport=True两个参数设置窗口最大化。
browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"D:\chrome_userx\yoyo",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome",
args=['--start-maximized'],
no_viewport=True
)
或者使用viewport={'width':1920,'height':1080}设置屏幕分辨率
browser = p.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=f"D:\chrome_userx\yoyo",
# 接收下载事件
accept_downloads=True,
# 设置 GUI 模式
headless=False,
bypass_csp=True,
slow_mo=1000,
channel="chrome",
viewport={'width': 1920, 'height': 1080}
)
《最新出炉》系列初窥篇-Python+Playwright自动化测试-21-处理鼠标拖拽-番外篇的更多相关文章
- 《手把手教你》系列基础篇(八十)-java+ selenium自动化测试-框架设计基础-TestNG依赖测试-番外篇(详解教程)
1.简介 经过前边几篇知识点的介绍,今天宏哥就在实际测试中应用一下前边所学的依赖测试.这一篇主要介绍在TestNG中一个类中有多个测试方法的时候,多个测试方法的执行顺序或者依赖关系的问题.如果不用de ...
- python接口自动化(三十三)-python自动发邮件总结及实例说明番外篇——下(详解)
简介 发邮件前我们需要了解的是邮件是怎么一个形式去发送到对方手上的,通俗点来说就是你写好一封信,然后装进信封,写上地址,贴上邮票,然后就近找个邮局,把信仍进去,其他的就不关心了,只是关心时间,而电子邮 ...
- 羽夏看Win系统内核—— VT 入门番外篇
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (II)
#3使用html+css+js制作网页 番外篇 使用python flask 框架 II第二部 0. 本系列教程 1. 登录功能准备 a.python中操控mysql b. 安装数据库 c.安装mys ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (I)
#3使用html+css+js制作网页 番外篇 使用python flask 框架(I 第一部) 0. 本系列教程 1. 准备 a.python b. flask c. flask 环境安装 d. f ...
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
这次博客园的排版彻底残了..高清版请移步: https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程: 给深度学习入门者的Python快速教程 - 基础篇 给深度 ...
- python自动化测试应用-番外篇--接口测试1
篇1 book-python-auto-test-番外篇--接口测试1 --lamecho辣么丑 1.1概要 大家好! 我是lamecho(辣么丑),至今<安卓a ...
- python自动化测试应用-番外篇--接口测试2
篇2 book-python-auto-test-番外篇--接口测试2 --lamecho辣么丑 大家好! 我是lamecho(辣么丑),今天将继续上一篇python接 ...
- python之爬虫--番外篇(一)进程,线程的初步了解
整理这番外篇的原因是希望能够让爬虫的朋友更加理解这块内容,因为爬虫爬取数据可能很简单,但是如何高效持久的爬,利用进程,线程,以及异步IO,其实很多人和我一样,故整理此系列番外篇 一.进程 程序并不能单 ...
- openresty 学习笔记番外篇:python的一些扩展库
openresty 学习笔记番外篇:python的一些扩展库 要写一个可以使用的python程序还需要比如日志输出,读取配置文件,作为守护进程运行等 读取配置文件 使用自带的ConfigParser模 ...
随机推荐
- 如何将视频文件.h264和音频文件.mp3复用为输出文件output.mp4?
一.初始化复用器 在这个部分我们可以分三步进行:(1)打开输入视频文件上下文句柄 (2)打开输入音频文件上下文句柄 (3)打开输出文件上下文句柄 1.打开输入视频文件上下文句柄 在这一步,我们主要用到 ...
- UI自动化 --- 微软UI Automation
引言 自动化测试平台的意义就三个字 --- 稳定性. 无论是接口自动化测试,还是UI自动化测试,目的就是为了提高产品的稳定性,保证用户体验. 那常见的接口自动化测试比如有 Postman ,SoapU ...
- pod reopened update慢
CocoaPods 镜像使用帮助 CocoaPods 是一个 Cocoa 和 Cocoa Touch 框架的依赖管理器,具体原理和 Homebrew 有点类似,都是从 GitHub 下载索引,然后根据 ...
- 【RabbitMQ】当队列中消息数量超过最大长度的淘汰策略
[RabbitMQ]当队列中消息数量超过最大长度的淘汰策略 说明 最近在研究RabbitMQ如何实现延时队列时发现消息进入死信队列的情况之一就是当消息数量超过队列设置的最大长度时会被丢入死信队列,看到 ...
- std::queue 中遇到释放内存错误的问题
项目上有个需求要用到 std::queue 顺序处理消息事件 简单的示例如下: struct MyEvent { MyEvent() { event_ = CreateEvent(nullptr, 0 ...
- 超详细的mysql总结(DQL)
上一篇文章总结了 DDL.DML的使用,这一篇文章把剩下的 DQL 加上~ DQL(Data Query Language)即数据库查询语言,用来查询所需要的信息,在查询的过程中,需要判断所查询的 ...
- 发布关于PostGIS对于USD格式的拓展
我们非常高兴的发布为了一年一度的SIGGRAPH 2023发布关于为PostGIS支持USD格式的新拓展. 新添加了3个函数 ST_AsUSDA(geom geometry, usd_root_nam ...
- nginx-http反向代理与负载均衡
前言 反向代理服务器位于用户与目标服务器之间,但是对于用户而言,反向代理服务器就相当于目标服务器,即用户直接访问反向代理服务器就可以获得目标服务器的资源.同时,用户不需要知道目标服务器的地址,也无须在 ...
- (2023.7.24)软件加密与解密-2-1-程序分析方法[XDbg].md
body { font-size: 15px; color: rgba(51, 51, 51, 1); background: rgba(255, 255, 255, 1); font-family: ...
- 使用 Sealos 在离线环境中光速安装 K8s 集群
作者:尹珉.Sealos 开源社区 Ambassador,云原生爱好者. 当容器化交付遇上离线环境 在当今快节奏的软件交付环境中,容器化交付已经成为许多企业选择的首选技术手段.在可以访问公网的环境下, ...