python爬虫入门(5)----- 阿里巴巴供应商爬虫
阿里巴巴供应商爬虫#
起因##
学了爬虫入门之后,打算找一个有难度的网站来实践,一开始打算找淘宝或者天猫(业界老大)来实践,但后续发现网上已经有很多这方面的项目,于是瞄上了阿里的国际网站阿里巴巴。开始一切顺利,没发现什么难度,后面发现供应商的联系方式需要登录,于是以其为目标开始写爬虫。
网站结构##
1.阿里巴巴有个供应商分类的页面
https://www.alibaba.com/companies
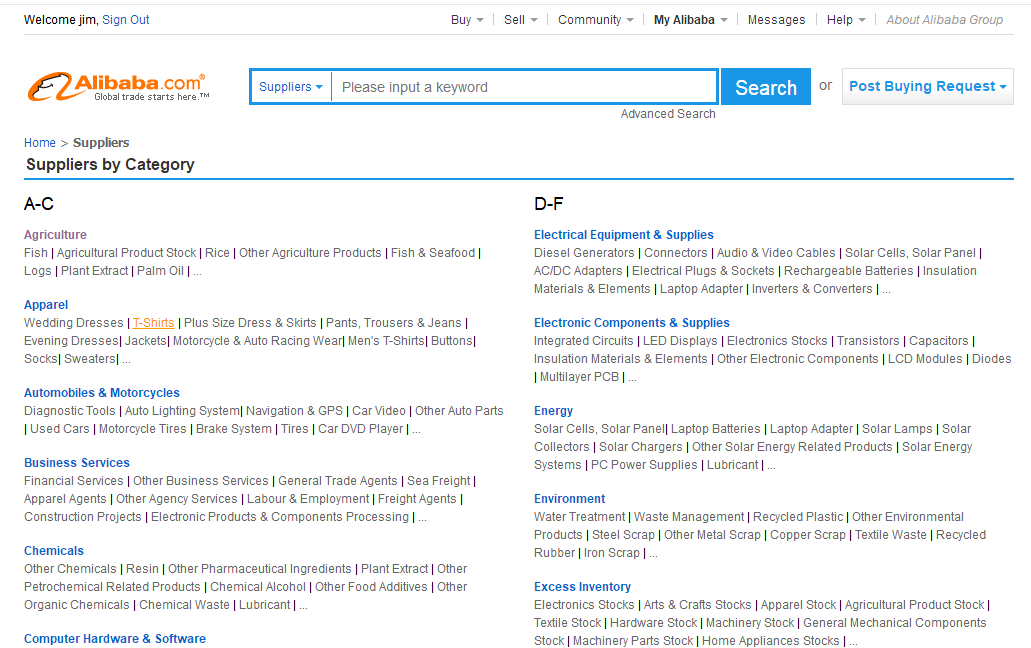
2.点进去之后有个二级分类
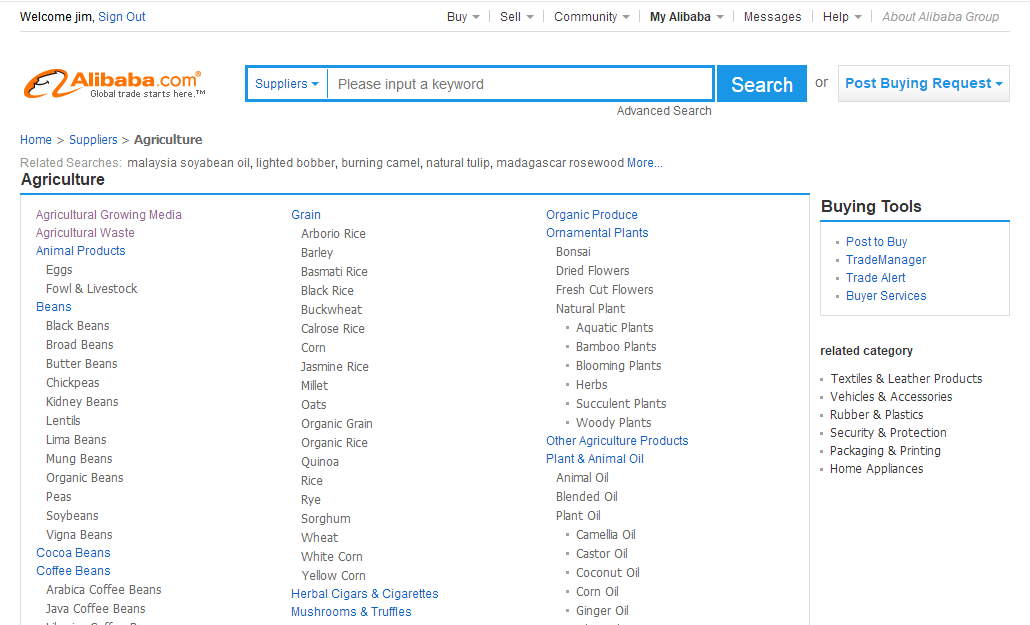
3.再点进去就可以找到这个分类下的所有供应商
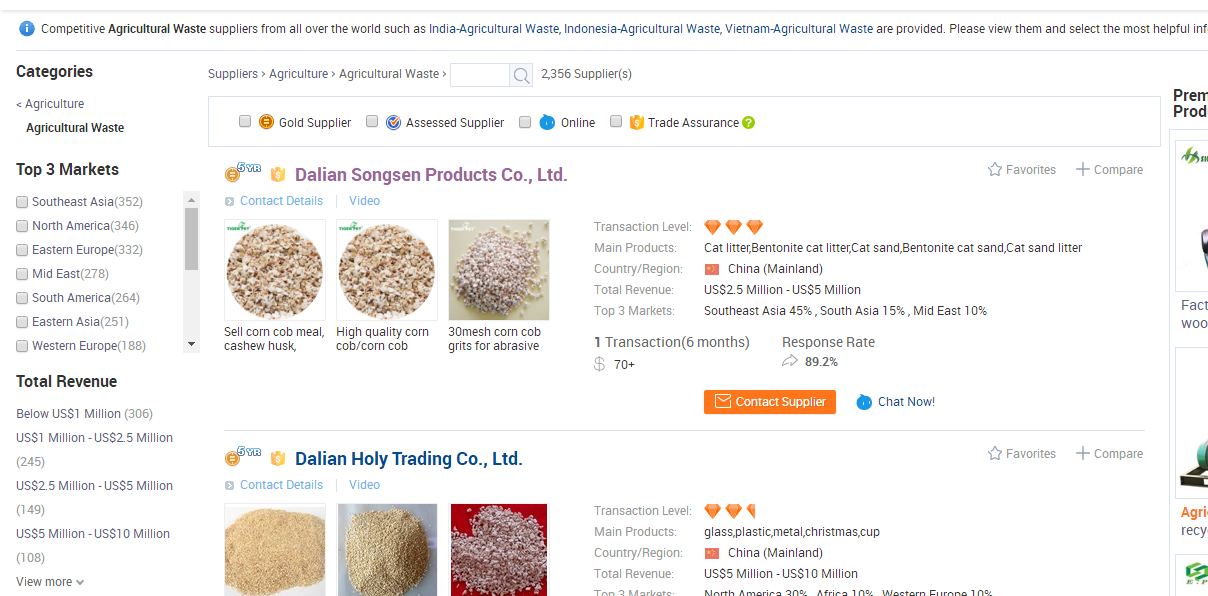
4.再进去就可以找供应商的联系方式了
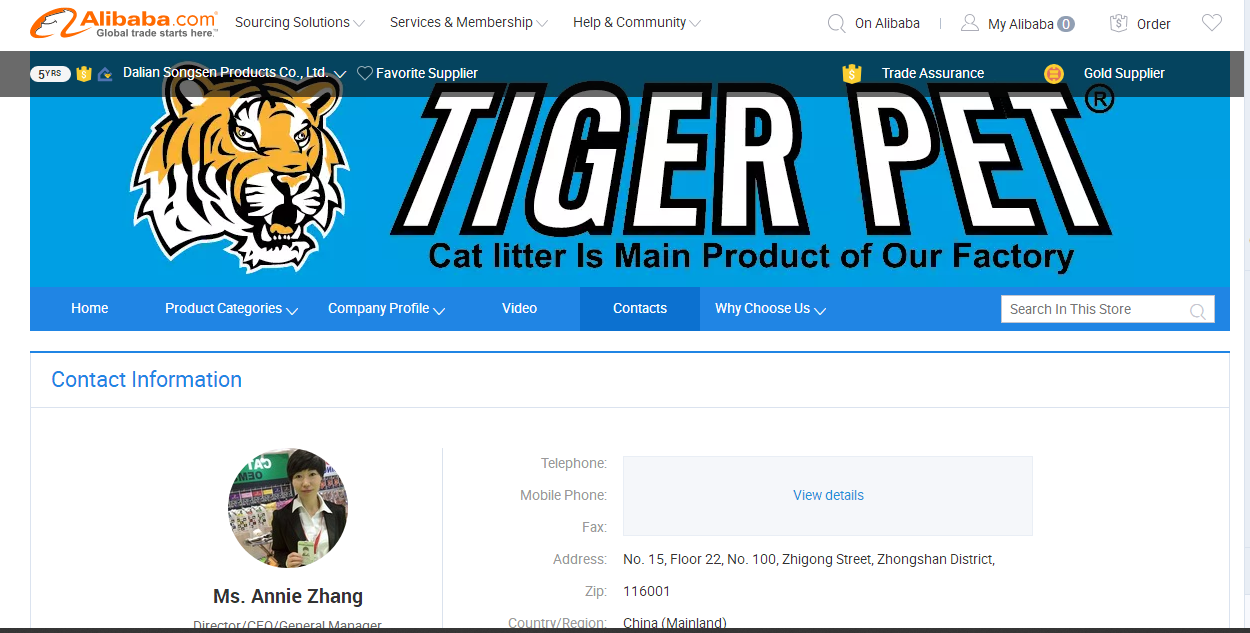
5.这时要获取联系方式就需要登录
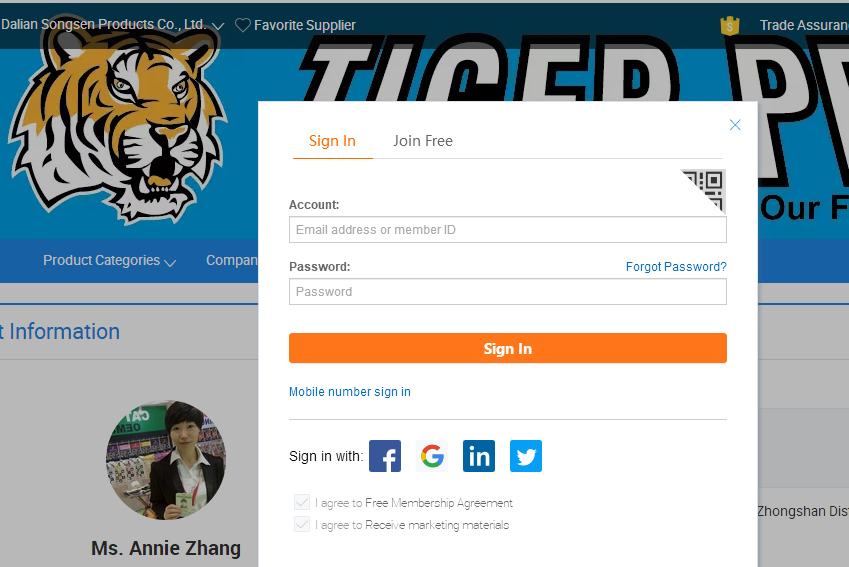
爬虫思路##
1.先从供应商分类页面开始爬取,获取到所有的供应商联系方式的页面(即上面网站结构的第4步)存入数据库
2.编写另一个爬虫从数据库拿到联系方式页面,再用selenium登录获取联系方式(这一步是取巧了,但也导致爬取速度直线下降)
代码结构##
#scrapy的代码结构
alibaba
-spider
--company.py #获取供应商联系方式页面
--contact.py #获取联系方式的页面
-items
-middlewares.py
-pipelines.py
-setting.py
company.py
class CompanySpider(scrapy.Spider):
name = 'company'
allowed_domains = ['www.alibaba.com']
start_urls = ['https://www.alibaba.com/companies']
# 爬取大的分类信息
def parse(self, response):
categorys = response.css(".ui-box.ui-box-normal.ui-box-wrap.clearfix .g-cate-list dl dt a")
for cat in categorys:
name = cat.css("::text").extract_first()
url = cat.css("::attr(href)").extract_first()
yield scrapy.Request(url, callback=self.parseCategory, meta={'cat': name})
pass
# 爬取详细分类信息
def parseCategory(self, response):
cat = response.meta['cat']
ccats = response.css("#category-main-box .g-float-left>ul>li>a")
for ccat in ccats:
name = ccat.css("::text").extract_first()
url = ccat.css("::attr(href)").extract_first()
ccat_url = urljoin(self.start_urls[0], url)
yield scrapy.Request(ccat_url, callback=self.parseCompany, meta={'ccat': name, 'cat': cat})
pass
def parseCompany(self, response):
cat = response.meta['cat']
ccat = response.meta['ccat']
# 爬取下一页
next_url = response.css(".next::attr(href)").extract_first()
if (next_url):
yield scrapy.Request(urljoin(response.url, next_url), callback=self.parseCompany, meta={'cat': cat, 'ccat': ccat})
# 爬取公司信息
items = response.css(".item-main")
for item in items:
company = CompanyItem()
title = item.css(".item-title .title.ellipsis a")
company["name"] = title.css("::text").extract_first().strip()
url = title.css("::attr(href)").extract_first()
url = url.rpartition("/")[0]
company["url"] = url
attrs = item.css(".content.util-clearfix .right .attr")
for attr in attrs:
name = attr.css(".name::text").extract_first()
value = attr.css(".value")
if name == 'Main Products:':
mainProducts = value.css("::text").extract_first()
company["mainProducts"] = mainProducts
elif name == "Country/Region:":
region = value.css(".ellipsis.search::text").extract_first()
company["region"] = region
elif name == "Total Revenue:":
totalRevenue = value.css(".ellipsis.search::text").extract_first()
company["totalRevenue"] = totalRevenue
elif name == "Top 3 Markets:":
top3 = value.css(".ellipsis.search::text").extract()
company["top3Markets"] = ",".join(top3)
company["ccat"] = ccat
company["cat"] = cat
yield company
pass
contact.py
class ContactSpider(scrapy.Spider):
name = 'contact'
allowed_domains = ['www.alibaba.com']
start_urls = []
count = 1000
def __init__(self):
# selenium
# options = Options()
# prefs = {"profile.managed_default_content_settings.images": 2}
# options.add_experimental_option("prefs", prefs)
# options.headless = True
# driver_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))+"\chromedriver.exe"
# print(driver_path)
# 创建Firefox浏览器的一个Options实例对象
profile = webdriver.FirefoxProfile()
# 禁用CSS加载
profile.set_preference('permissions.default.stylesheet', 2)
# 禁用images加载
profile.set_preference('permissions.default.image', 2)
# 禁用flash插件
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.headless = True
profile.set_preference('dom.ipc.plugins.enabled.libflashplayer.so', False)
self.browser = webdriver.Firefox(executable_path=settings.FIREFOX_WEBDRIVER_PATH,
firefox_profile=profile, firefox_options=fireFoxOptions)
# mysql
self.client = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8'
)
self.cur = self.client.cursor()
# startUrls
sql = "select id,url from disct_company where id <= {} and id > {}".format(settings.END, settings.START)
try:
self.cur.execute(sql)
results = self.cur.fetchall()
for url in results:
id = url[0]
contact_url = url[1] # type: str
if not (contact_url.startswith("http:") or contact_url.startswith("https:")):
contact_url = "https:" + contact_url
if not (contact_url.endswith("/")):
contact_url += "/"
contact_url += ("contactinfo.html?%d" % (id))
self.start_urls.append(contact_url)
except Exception as error:
logging.error("contact spider init err:{}".format(error))
# 关闭资源
dispatcher.connect(receiver=self.spiderCloseHandler, signal=signals.spider_closed)
def spiderCloseHandler(self, spider):
self.browser.quit()
self.cur.close()
self.client.close()
def parse(self, response):
id = response.meta.get("id")
item = ContactItem()
item['id'] = id
name = response.css(".contact-name::text").extract_first()
if not name:
name = response.css(".contact-info .name::text").extract_first()
if name:
name = name.strip()
item['name'] = name
department = response.css(".contact-department::text").extract_first()
job = response.css(".contact-job::text").extract_first()
if not (department and job):
dds = response.css(".contact-info .dl-horizontal dd::text")
dts = response.css(".contact-info .dl-horizontal dt::text")
if dds:
for i in range(len(dds)):
dd = dds[i].extract()
dt = dts[i].extract()
if dt == 'Department:':
department = dd
elif dt == 'Job Title:':
job = dd
item['department'] = department
item['job'] = job
info_table = response.css(".info-table tr")
if info_table:
for info in info_table:
th = info.css("th::text").extract_first()
td = info.css("td::text").extract_first()
if th == 'Telephone:':
item['telephone'] = td
elif th == 'Mobile Phone:':
item['mobilePhone'] = td
elif th == 'Fax:':
item['fax'] = td
elif th == 'Address:':
item['address'] = td
elif th == 'Zip:':
item['zip'] = td
elif th == 'Country/Region:':
item['country'] = td
elif th == 'Province/State:':
item['province'] = td
elif th == 'City:':
item['city'] = td
else:
item['telephone'] = response.css(
".contact-detail .sensitive-info .dl-horizontal dd[data-role=phone]::text").extract_first()
item['mobilePhone'] = response.css(
".contact-detail .sensitive-info .dl-horizontal dd[data-role=mobile]::text").extract_first()
item['fax'] = response.css(
".contact-detail .sensitive-info .dl-horizontal dd[data-role=fax]::text").extract_first()
dds = response.css(".contact-detail .public-info .dl-horizontal dd::text").extract()
dts = response.css(".contact-detail .public-info .dl-horizontal dt::text").extract()
for i in range(len(dts)):
dt = dts[i]
dd = dds[i]
if dt == 'Address:':
item['address'] = dd
elif dt == 'Zip:':
item['zip'] = dd
elif dt == 'Country/Region:':
item['country'] = dd
elif dt == 'Province/State:':
item['province'] = dd
elif dt == 'City:':
item['city'] = dd
yield item
seleniumDownloaderMiddleware
class SeleniumDownloaderMiddleware(object):
def process_request(self, request, spider):
if spider.name == 'contact':
try:
url = request.url
spider.browser.get(url)
time.sleep(1)
if self.is_element_exist(".sens-mask .icbu-link-default", spider.browser):
viewButton = spider.browser.find_element_by_css_selector(".sens-mask .icbu-link-default")
elif self.is_element_exist(".contact-detail-mask .view-contact-trigger", spider.browser):
viewButton = spider.browser.find_element_by_css_selector(".contact-detail-mask .view-contact-trigger")
if viewButton:
spider.browser.execute_script("arguments[0].click();", viewButton)
# spider.browser.execute_script("arguments[0].scrollIntoView();", viewButton)
time.sleep(2)
if self.is_element_exist(".sc-hd-prefix2-dialog-bd", spider.browser):
spider.browser.execute_script("arguments[0].click();", spider.browser.find_element_by_css_selector(".sc-hd-prefix2-tab-trigger"))
time.sleep(1)
spider.browser.switch_to.frame("alibaba-login-box")
spider.browser.find_element_by_id("fm-login-id").send_keys("your username")
time.sleep(1)
spider.browser.find_element_by_id("fm-login-password").send_keys("your password")
time.sleep(1)
# submit = spider.browser.find_element_by_id("fm-login-submit")
spider.browser.execute_script("document.getElementById('fm-login-submit').click();")
# spider.browser.execute_script("arguments[0].scrollIntoView();", submit)
# submit.click()
time.sleep(5)
spider.browser.switch_to.default_content()
except Exception as error:
logging.error("{} err:{}".format(url, error))
return HtmlResponse(spider.browser.current_url, body=spider.browser.page_source, encoding='utf-8',
request=request)
return None
def is_element_exist(self, css, browser):
s = browser.find_elements_by_css_selector(css_selector=css)
if len(s) == 0:
return False
elif len(s) == 1:
return True
else:
return False
项目地址##
项目已上传github:https://github.com/shuo123/alibabaSpider
python爬虫入门(5)----- 阿里巴巴供应商爬虫的更多相关文章
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- Python爬虫入门教程 50-100 Python3爬虫爬取VIP视频-Python爬虫6操作
爬虫背景 原计划继续写一下关于手机APP的爬虫,结果发现夜神模拟器总是卡死,比较懒,不想找原因了,哈哈,所以接着写后面的博客了,从50篇开始要写几篇python爬虫的骚操作,也就是用Python3通过 ...
- Python爬虫入门教程 53-100 Python3爬虫获取三亚天气做旅游参照
爬取背景 这套课程虽然叫爬虫入门类课程,但是里面涉及到的点是非常多,十分检验你的基础掌握的牢固程度,代码中的很多地方都是可以细细品味的. 为什么要写这么一个小东东呢,因为我生活在大河北,那雾霾醇厚的很 ...
- Python爬虫入门教程 51-100 Python3爬虫通过m3u8文件下载ts视频-Python爬虫6操作
什么是m3u8文件 M3U8文件是指UTF-8编码格式的M3U文件. M3U文件是记录了一个索引纯文本文件, 打开它时播放软件并不是播放它,而是根据它的索引找到对应的音视频文件的网络地址进行在线播放. ...
- 爬虫入门之反反爬虫机制cookie UA与中间件(十三)
1. 通常防止爬虫被反主要有以下几个策略 (1)动态设置User-Agent(随机切换User-Agent,模拟不同的浏览器) 方法1: 修改setting.py中的User-Agent # Craw ...
- python爬虫入门01:教你在 Chrome 浏览器轻松抓包
通过 python爬虫入门:什么是爬虫,怎么玩爬虫? 我们知道了什么是爬虫 也知道了爬虫的具体流程 那么在我们要对某个网站进行爬取的时候 要对其数据进行分析 就要知道应该怎么请求 就要知道获取的数据是 ...
- Python爬虫学习——1.爬虫入门
HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法. HTTPS(Hypertext Transfer ...
- 爬虫入门系列(三):用 requests 构建知乎 API
爬虫入门系列目录: 爬虫入门系列(一):快速理解HTTP协议 爬虫入门系列(二):优雅的HTTP库requests 爬虫入门系列(三):用 requests 构建知乎 API 在爬虫系列文章 优雅的H ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
随机推荐
- ElasticSearch中的sort排序和filedData作用
默认情况下,ElasticSearch 会根据算分进行排序: 可以使用 sort API 指定排序的规则: POST /kibana_sample_data_ecommerce/_search { & ...
- jni不通过线程c回调java的函数
整个工程的项目如下: 1.项目的思路是在activity中启动MyService这个服务,在服务中调用 JniScsManger类中的本地方法startNativeScsService,在 start ...
- AJAX 调用WebService 、WebApi 增删改查(笔记)
经过大半天努力,终于完成增删改查了!心情有点小激动!!对于初学者的我来说,一路上都是迷茫,坑!!虽说网上有资料,可动手起来却不易(初学者的我).(苦逼啊!) WebService 页面: /// &l ...
- SecureCRT连接阿里云ECS服务器,经常掉线的解决方案
1 使用SecureCRT远程连接后,Options > Session Options > Terminal(终端) > 勾选 “Send protocol NO-OP”
- Layer 3.0
https://jeesite.gitee.io/front/layer/3.0/layer.layui.com/index.html
- docker 容器与本机文件的拷贝操作
[把docker中容器时db002里面的my.cnf文件拷贝到根目录下] docker cp db002:/etc/mysql/my.cnf ~/root/ [把根目录下my.cnf文件拷贝到doc ...
- js实现json格式化,以及json校验工具的简单实现
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,采用完全独立于语言的文本格式,但是也使用了类似于C语言家族的习惯(包括C, C++, C#, Java, ...
- 「疫期集训day5」火焰
我们就像一把穿刺敌人的利刃,把敌人开肠破肚----凡尔登高地前气势汹汹的德军 今天没有考试,挺好,有时间自己做题了 今天主要复习+学习了数据结构,列了个表: 已完成:单调队列,线段树,set/vect ...
- Codeforces 1215D Ticket Game 题解
Codeforces 1215D Ticket Game 原题 题目 Monocarp and Bicarp live in Berland, where every bus ticket consi ...
- 如何排查CPU占用太高
线上项目运行时,出现问题不像在本地那么容易排查,经常需要借助日志.或者一些工具来找出问题.cpu被占满我们经常会遇到.比如我们有这样一段代码: public Class Demo1_16 { publ ...