python安装及简单爬虫(爬取导师信息)
1.下载:
解释器(我下的是3.8.2版本):https://www.python.org/downloads/
pycharm(我下的是2019.3.3版本):https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows
注意:python安装时要勾选
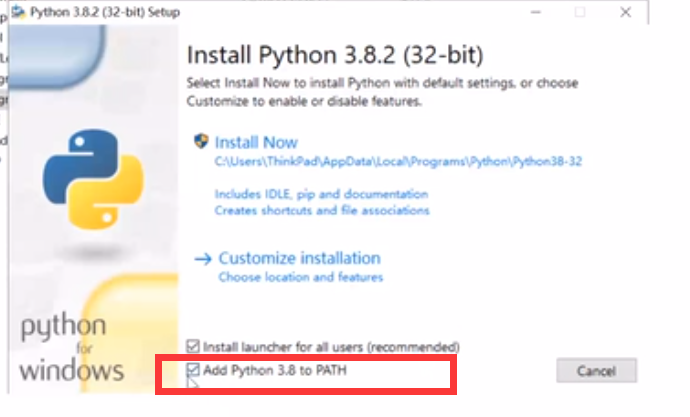
检查python是否安装好可以在cmd命令中输入python,出现下图即可

pycharm安装时这四个全选上(只有30天试用期)
JB全家桶永久激活:https://www.exception.site/essay/how-to-free-use-intellij-idea-2019-3
2.爬取网页信息(以浙工大为例)http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id=35


# -*- codeing = utf-8 -*-
#@Time : 2022/2/20 16:44
#@Auther : 叶丹薇
#@File : spider.py
#@Software: PyCharm
from bs4 import BeautifulSoup #网页解析
import re #正则
import urllib.request,urllib.error #制定url 获取网页数据
import sqlite3 #数据库
import xlwt #excel
def main():
baseurl="http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id="
#1.爬取网页
datalist=getData(baseurl)
savepath="导师.xls"
#3保存
saveData(datalist,savepath) findname=re.compile(r'<li><a.*?>(.*?)</a><br/>')#<a href=
finddire=re.compile(r'研究方向:(.*?)</a>')#<a href="#">空间信息计算研究所</a>
findcoll=re.compile(r'<li><a href="#">(.*?)</a>')
#1.爬取网页
def getData(baseurl):
datalist=[]
for j in range(35,50):
url=baseurl+str(j)
html=askURL(url)
if(html==''):continue
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
item0=soup.find_all('div',id="boxtitle3")
item0=str(item0)
colle = re.findall(findcoll,item0)[1]
for item in soup.find_all('div',style="width:100%; float:left"):#查找符合要求的字符串
item=str(item)
teacher=re.findall(findname,item)
director = re.findall(finddire, item)
for i in range(len(teacher)):
data = []
data.append(teacher[i])
data.append(colle)
data.append(director[i])
datalist.append(data)
# print(data)
# print(datalist)
return datalist #得到指定URL的网页内容
def askURL(url):
#模拟浏览器头部,进行伪装
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
request=urllib.request.Request(url,headers=head)#请求
html=""
try:
response=urllib.request.urlopen(request)#响应
html=response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
#print("这页没有内容")
html=''
return html
#保存数据
def saveData(datalist,savepath):
book=xlwt.Workbook(encoding="utf-8")#创建word对象
sheet=book.add_sheet('老师',cell_overwrite_ok=True)#创建sheet表
col=("姓名","研究所","研究方向")
for i in range(0,3):
sheet.write(0,i,col[i])
for i in range(0,len(datalist)):
#print("第%d条"%(i+1))
data=datalist[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
book.save(savepath)
if __name__=="__main__":
main()
python安装及简单爬虫(爬取导师信息)的更多相关文章
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python 基础语法+简单地爬取百度贴吧内容
Python笔记 1.Python3和Pycharm2018的安装 2.Python3基础语法 2.1.1.数据类型 2.1.1.1.数据类型:数字(整数和浮点数) 整数:int类型 浮点数:floa ...
- Python简单程序爬取天气信息,定时发邮件给朋友【高薪必学】
前段时间看到了这个博客.https://blog.csdn.net/weixin_45081575/article/details/102886718.他用了request模块,这不巧了么,正好我刚用 ...
- 简单爬虫-爬取免费代理ip
环境:python3.6 主要用到模块:requests,PyQuery 代码比较简单,不做过多解释了 #!usr/bin/python # -*- coding: utf-8 -*- import ...
- python实战之原生爬虫(爬取熊猫主播排行榜)
""" this is a module,多行注释 """ import re from urllib import request # B ...
- PHP简单爬虫 爬取免费代理ip 一万条
目标站:http://www.xicidaili.com/ 代码: <?php require 'lib/phpQuery.php'; require 'lib/QueryList.php'; ...
- 一个简单python爬虫的实现——爬取电影信息
最近在学习网络爬虫,完成了一个比较简单的python网络爬虫.首先为什么要用爬虫爬取信息呢,当然是因为要比人去收集更高效. 网络爬虫,可以理解为自动帮你在网络上收集数据的机器人. 网络爬虫简单可以大致 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- 异常的产生过程解析-throw关键字
异常的产生过程解析 先运行下面的程序,程序会产生一个数组索引越界异常ArrayIndexOfBoundException.我们通过图解来解析下异常产生的过程. 工具类 throw关键字 在编写程序时, ...
- Linux防火墙部署与配置
Linux防火墙部署与配置 1. 实验概述 Linux作为网关,搭建小型局域网,在此基础上进行实验,了解Linux防火墙的构成.NAT和包过滤配置方法等. 2. 实验环境 网络大致结构如图2-1所示, ...
- USACO 2023 January Contest, Bronze Problem 3. Moo Operations
这道题目灰常简单,我们先从最简单的3个字符串开始 有以下几种情况: 可以看到,只有在中间是O的情况下才有可能变成MOO 辣么我们不妨在在s串中枚举这个中间 O 每枚举到一个就看看能不能用他的本身操作次 ...
- DNA
思路一: 这题需要桶+哈希(简化版像A 1 B 2 ......) 具体: 先把数据输入 再枚举可能的右端点,再由右端点得到左端点(l和r相差k) 在 l到r 区间内将这一段区间哈希成一个4进制数 ...
- Solon2 开发之容器,八、动态代理的本质
在 Java 里动态代理,主要分:接口动态代理 和 类动态代理.因为它的代理类都是动态创建的,所以名字里会带上"动态". 官网的有些地方叫"代理",也有些地方叫 ...
- 关于AD获取成员隶属于哪些组InvokeGet("memberOf")的问题
关于AD获取成员隶属于组成员问题 获取结果默认返回object类型,可能是string类型,也可能是object[]类型,所以只有一个结果的时候是string类型,直接返回object[]会报错 pr ...
- P18_Day2.学习目标
能够使用 WXML 模板语法渲染页面结构 能够使用 WXSS 样式美化页面结构 能够使用 app.json 对小程序进行全局性配置 能够使用 page.json 对小程序页面进行个性化配置 能够知道如 ...
- Git常用指令集合🔥
关联文章:Git入门图文教程(1.5W字40图)--深入浅出.图文并茂 指令-查看状态信息 指令 描述 git --version 查看git版本 git status 查看本地仓库状态,比较常用的指 ...
- JZOJ 3252. 【GDOI三校联考】炸弹
思路 注:上图只是个例子,其实建图时 \(5\) 是不会连向 \(6\) 的 \(Code\) #include<cstdio> #include<cstring> #incl ...
- Median String
You are given two strings ss and tt, both consisting of exactly kk lowercase Latin letters, ss is le ...