python安装及简单爬虫(爬取导师信息)
1.下载:
解释器(我下的是3.8.2版本):https://www.python.org/downloads/
pycharm(我下的是2019.3.3版本):https://www.jetbrains.com/pycharm/download/download-thanks.html?platform=windows
注意:python安装时要勾选
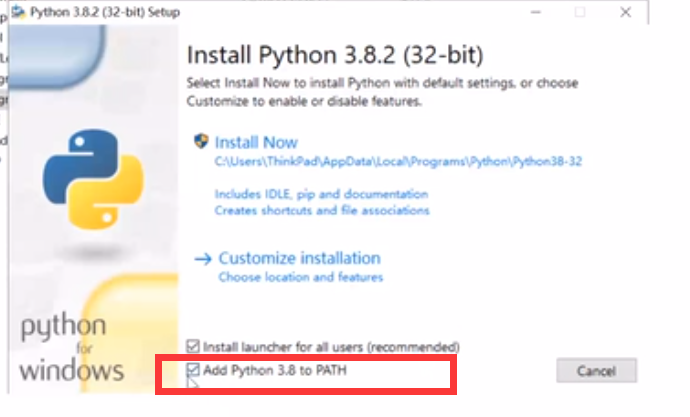
检查python是否安装好可以在cmd命令中输入python,出现下图即可

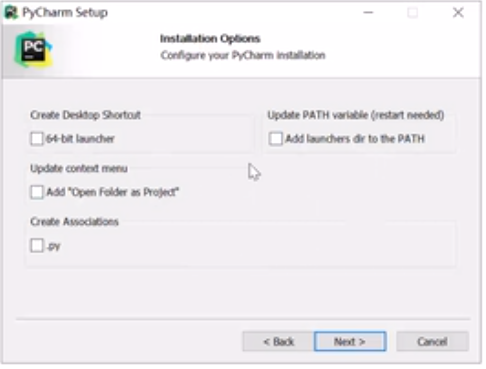
pycharm安装时这四个全选上(只有30天试用期)
JB全家桶永久激活:https://www.exception.site/essay/how-to-free-use-intellij-idea-2019-3
2.爬取网页信息(以浙工大为例)http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id=35


# -*- codeing = utf-8 -*-
#@Time : 2022/2/20 16:44
#@Auther : 叶丹薇
#@File : spider.py
#@Software: PyCharm
from bs4 import BeautifulSoup #网页解析
import re #正则
import urllib.request,urllib.error #制定url 获取网页数据
import sqlite3 #数据库
import xlwt #excel
def main():
baseurl="http://www.cs.zjut.edu.cn/jsp/inslabsread.jsp?id="
#1.爬取网页
datalist=getData(baseurl)
savepath="导师.xls"
#3保存
saveData(datalist,savepath) findname=re.compile(r'<li><a.*?>(.*?)</a><br/>')#<a href=
finddire=re.compile(r'研究方向:(.*?)</a>')#<a href="#">空间信息计算研究所</a>
findcoll=re.compile(r'<li><a href="#">(.*?)</a>')
#1.爬取网页
def getData(baseurl):
datalist=[]
for j in range(35,50):
url=baseurl+str(j)
html=askURL(url)
if(html==''):continue
#2.逐一解析数据
soup=BeautifulSoup(html,"html.parser")
item0=soup.find_all('div',id="boxtitle3")
item0=str(item0)
colle = re.findall(findcoll,item0)[1]
for item in soup.find_all('div',style="width:100%; float:left"):#查找符合要求的字符串
item=str(item)
teacher=re.findall(findname,item)
director = re.findall(finddire, item)
for i in range(len(teacher)):
data = []
data.append(teacher[i])
data.append(colle)
data.append(director[i])
datalist.append(data)
# print(data)
# print(datalist)
return datalist #得到指定URL的网页内容
def askURL(url):
#模拟浏览器头部,进行伪装
head={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
request=urllib.request.Request(url,headers=head)#请求
html=""
try:
response=urllib.request.urlopen(request)#响应
html=response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
#print("这页没有内容")
html=''
return html
#保存数据
def saveData(datalist,savepath):
book=xlwt.Workbook(encoding="utf-8")#创建word对象
sheet=book.add_sheet('老师',cell_overwrite_ok=True)#创建sheet表
col=("姓名","研究所","研究方向")
for i in range(0,3):
sheet.write(0,i,col[i])
for i in range(0,len(datalist)):
#print("第%d条"%(i+1))
data=datalist[i]
for j in range(0,3):
sheet.write(i+1,j,data[j])
book.save(savepath)
if __name__=="__main__":
main()
python安装及简单爬虫(爬取导师信息)的更多相关文章
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python 基础语法+简单地爬取百度贴吧内容
Python笔记 1.Python3和Pycharm2018的安装 2.Python3基础语法 2.1.1.数据类型 2.1.1.1.数据类型:数字(整数和浮点数) 整数:int类型 浮点数:floa ...
- Python简单程序爬取天气信息,定时发邮件给朋友【高薪必学】
前段时间看到了这个博客.https://blog.csdn.net/weixin_45081575/article/details/102886718.他用了request模块,这不巧了么,正好我刚用 ...
- 简单爬虫-爬取免费代理ip
环境:python3.6 主要用到模块:requests,PyQuery 代码比较简单,不做过多解释了 #!usr/bin/python # -*- coding: utf-8 -*- import ...
- python实战之原生爬虫(爬取熊猫主播排行榜)
""" this is a module,多行注释 """ import re from urllib import request # B ...
- PHP简单爬虫 爬取免费代理ip 一万条
目标站:http://www.xicidaili.com/ 代码: <?php require 'lib/phpQuery.php'; require 'lib/QueryList.php'; ...
- 一个简单python爬虫的实现——爬取电影信息
最近在学习网络爬虫,完成了一个比较简单的python网络爬虫.首先为什么要用爬虫爬取信息呢,当然是因为要比人去收集更高效. 网络爬虫,可以理解为自动帮你在网络上收集数据的机器人. 网络爬虫简单可以大致 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- Java语言发展史-计算机进制转换
Java语言发展史 java的诞生 在1991年时候,James Gosling在Sun公司的工程师小组想要设计这样一种主要用于像电视盒这样的消费类电子产品的小型计算机语言. 这些电子产品有一个共同的 ...
- nginx 隐藏 index.php 直接访问
项目配置文件vhosts加上: if ( !-e $request_filename) { rewrite ^/(.*)$ /index.php/$1 last; break; } 修改后如图
- 如何用Python实现http客户端和服务器
功能:客户端可以向服务器发送get,post等请求,而服务器端可以接收这些请求,并返回给客户端消息. 客户端: #coding=utf-8import http.clientfrom urllib i ...
- springcloud 02-zookeeper
转 https://www.cnblogs.com/h--d/p/12643306.html ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的 ...
- cv::Mat::step详解
1.简介 step的几个类别区分: step:矩阵第一行元素的字节数 step[0]:矩阵第一行元素的字节数 step[1]:矩阵中一个元素的字节数 step1(0):矩阵中一行有几个通道数 step ...
- 30道四则运算java
package test4; import java.util.Scanner;import java.util.Random;public class Test4 { public static v ...
- 如何让别人pip install自己写的库?
一. 构建项目目录结构 结构如图所示: 文件介绍:LICENSE和README.md在git建仓库时选上,克隆下来就会有,license最好选择MIT的.sort.py文件里随便写个方法用于直接调用: ...
- Philips and Calculator
代码 #include<cstdio> #include<algorithm> using namespace std; const int N = 3 * 1e6; int ...
- 双端队列xLIS问题
题目大意 有 \(N\) 个数 \(A_i\) ,他准备将他们依次插入一个双端队列(每次可以在头或尾插入一个元素),最后将 整个队列从尾到头看成一个序列,求出最长上升子序列的长度 .他想知道 , \( ...
- 如何获取win10用户最高权限
第五步,在(输入对象名称)方框中输入"System Managed Accounts Group",再点击"检查名称" 转载: 百度经验: https: ...