Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序。好吧,其实就是找个目的学习python,分享一下。
1. 首先导入相关的模块
import os
import requests
from bs4 import BeautifulSoup
2. 向网站发送请求并获取网站数据
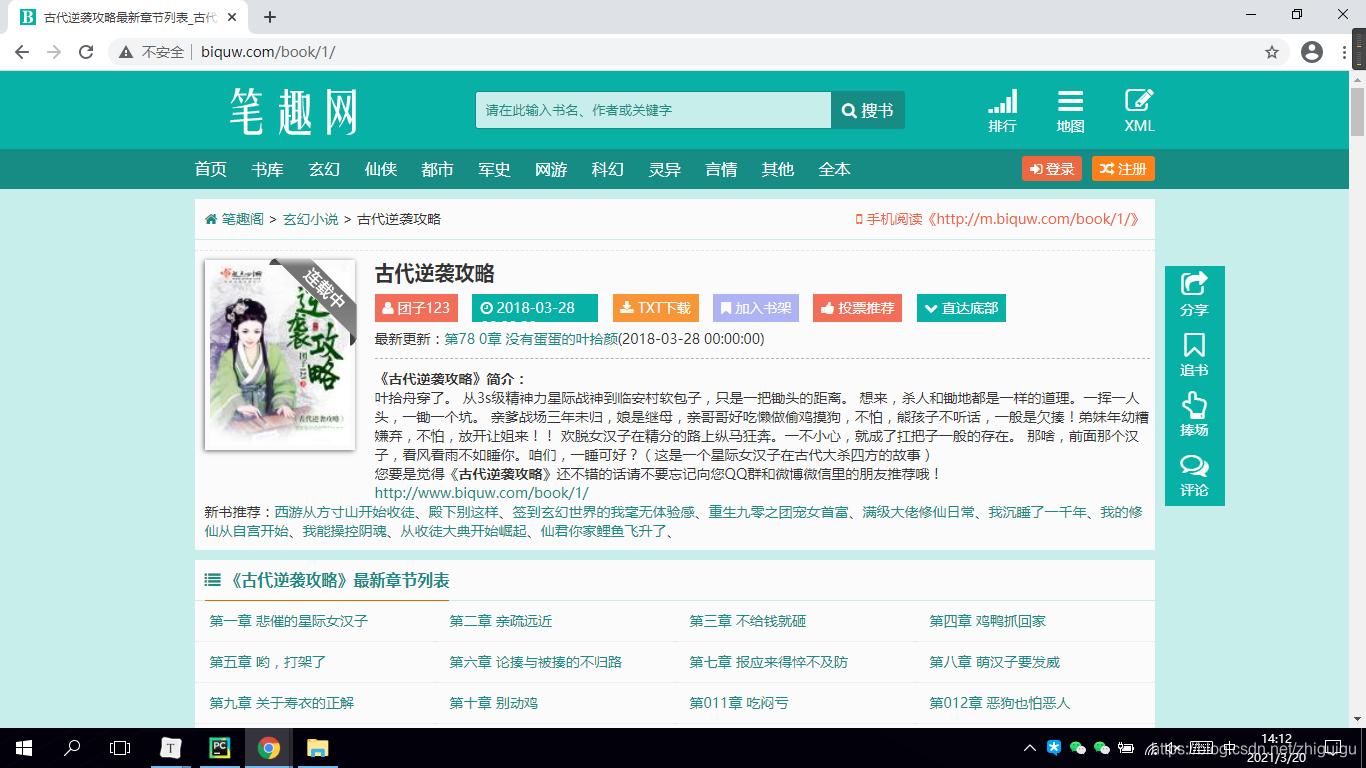
网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例。
进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取
# 声明请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'
}
# 创建保存小说文本的文件夹
if not os.path.exists('./小说'):
os.mkdir('./小说/')
# 访问网站并获取页面数据
response = requests.get('http://www.biquw.com/book/1/').text
print(response)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uu2ddyQB-1618914957232)(.\素材图片\中文显示乱码.png)]
写到这个地方同学们可能会发现了一个问题,当我去正常访问网站的时候为什么返回回来的数据是乱码呢?
这是因为页面html的编码格式与我们python访问并拿到数据的解码格式不一致导致的,python默认的解码方式为utf-8,但是页面编码可能是GBK或者是GB2312等,所以我们需要让python代码很具页面的解码方式自动变化
#### 重新编写访问代码
```python
response = requests.get('http://www.biquw.com/book/1/')
response.encoding = response.apparent_encoding
print(response.text)
'''
这种方式返回的中文数据才是正确的
'''
3. 拿到页面数据之后对数据进行提取
当大家通过正确的解码方式拿到页面数据之后,接下来需要完成静态页面分析了。我们需要从整个网页数据中拿到我们想要的数据(章节列表数据)
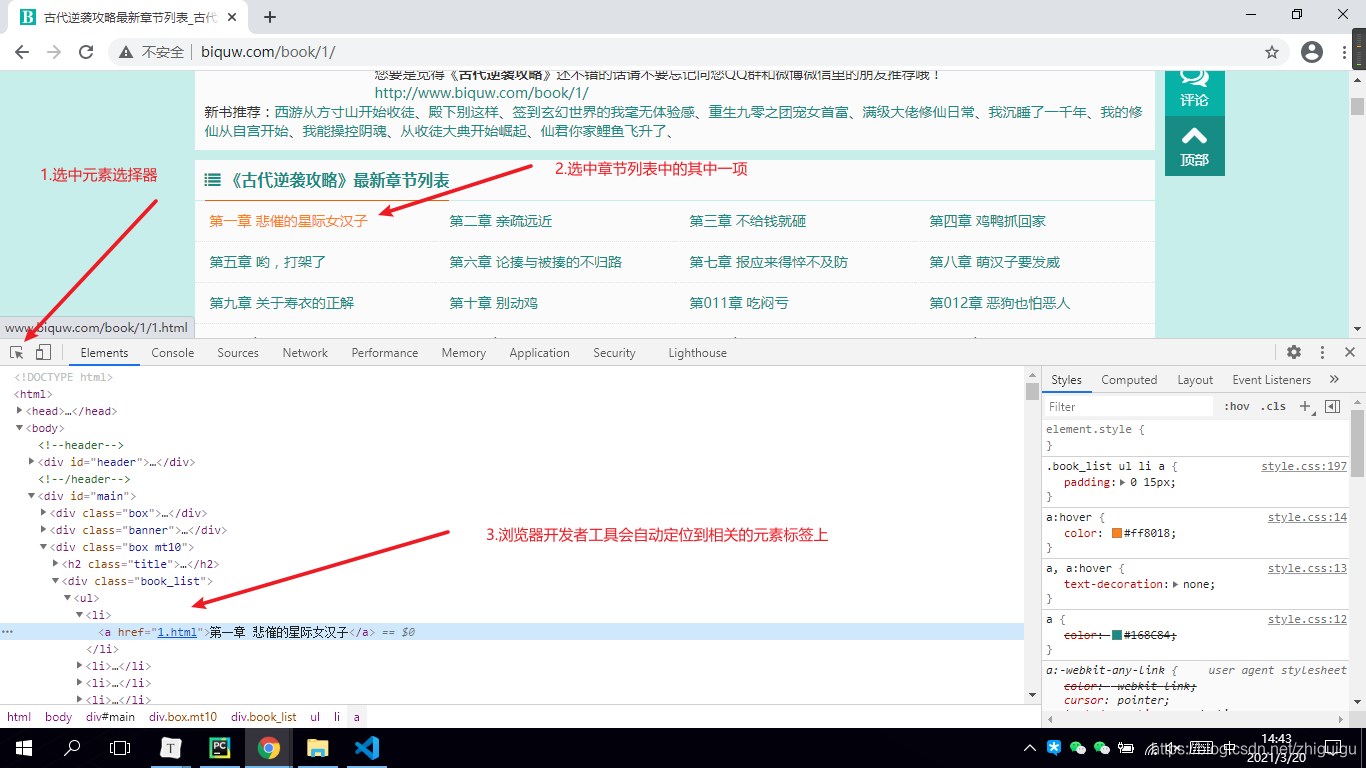
- 首先打开浏览器
- 按F12调出开发者工具
- 选中元素选择器
- 在页面中选中我们想要的数据并定位元素
- 观察数据所存在的元素标签
'''
根据上图所示,数据是保存在a标签当中的。a的父标签为li,li的父标签为ul标签,ul标签之上为div标签。所以如果想要获取整个页面的小说章节数据,那么需要先获取div标签。并且div标签中包含了class属性,我们可以通过class属性获取指定的div标签,详情看代码~
'''
# lxml: html解析库 将html代码转成python对象,python可以对html代码进行控制
soup = BeautifulSoup(response.text, 'lxml')
book_list = soup.find('div', class_='book_list').find_all('a')
# soup对象获取批量数据后返回的是一个列表,我们可以对列表进行迭代提取
for book in book_list:
book_name = book.text
# 获取到列表数据之后,需要获取文章详情页的链接,链接在a标签的href属性中
book_url = book['href']
4. 获取到小说详情页链接之后进行详情页二次访问并获取文章数据
book_info_html = requests.get('http://www.biquw.com/book/1/' + book_url, headers=headers)
book_info_html.encoding = book_info_html.apparent_encoding
soup = BeautifulSoup(book_info_html.text, 'lxml')
5. 对小说详情页进行静态页面分析
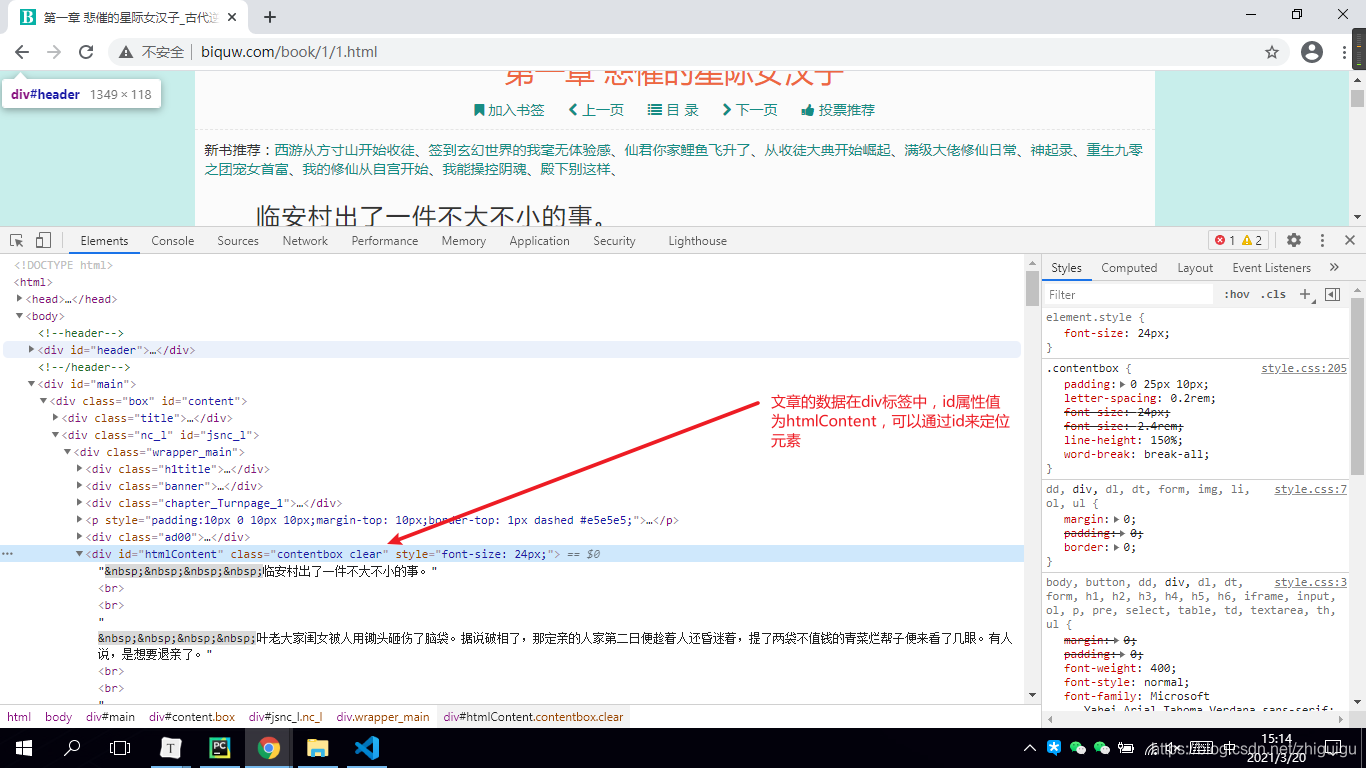
info = soup.find('div', id='htmlContent')
print(info.text)
6. 数据下载
with open('./小说/' + book_name + '.txt', 'a', encoding='utf-8') as f:
f.write(info.text)
最后让我们看一下代码效果吧~
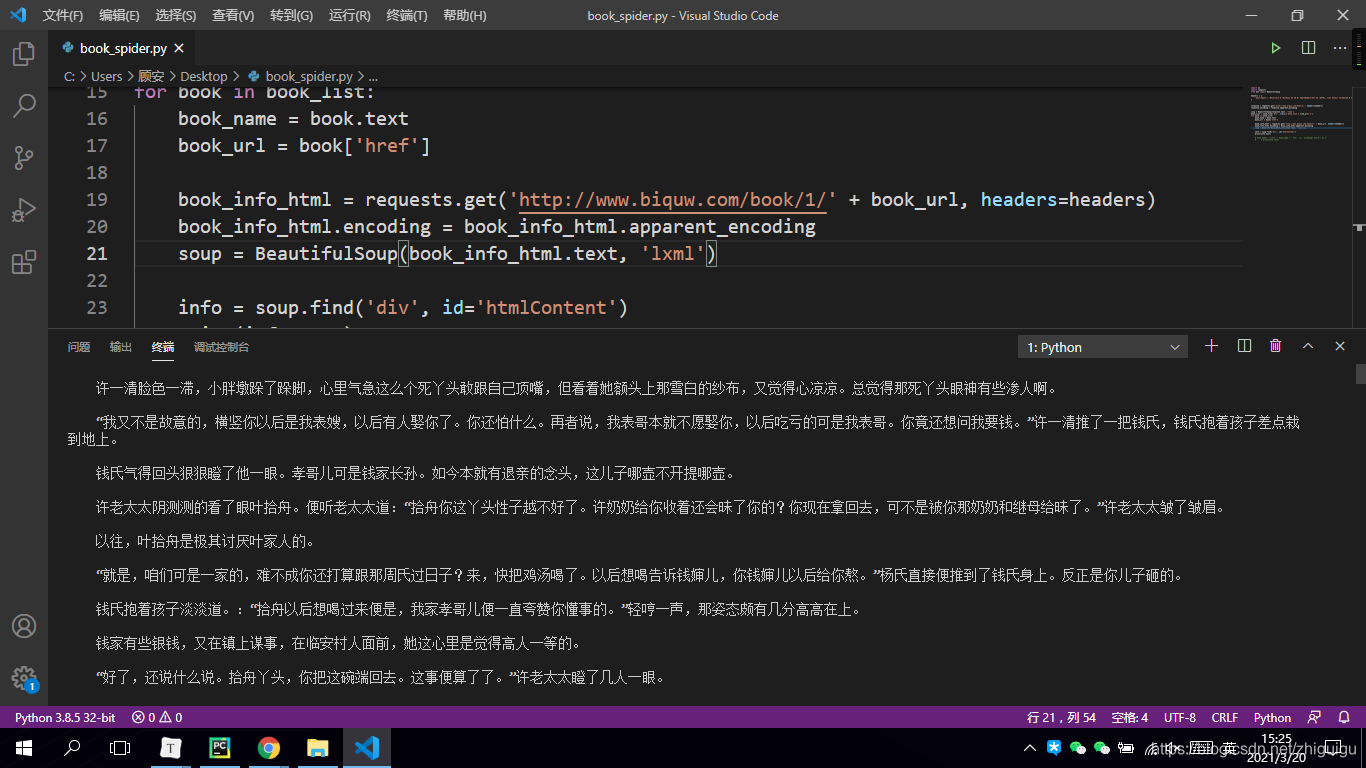
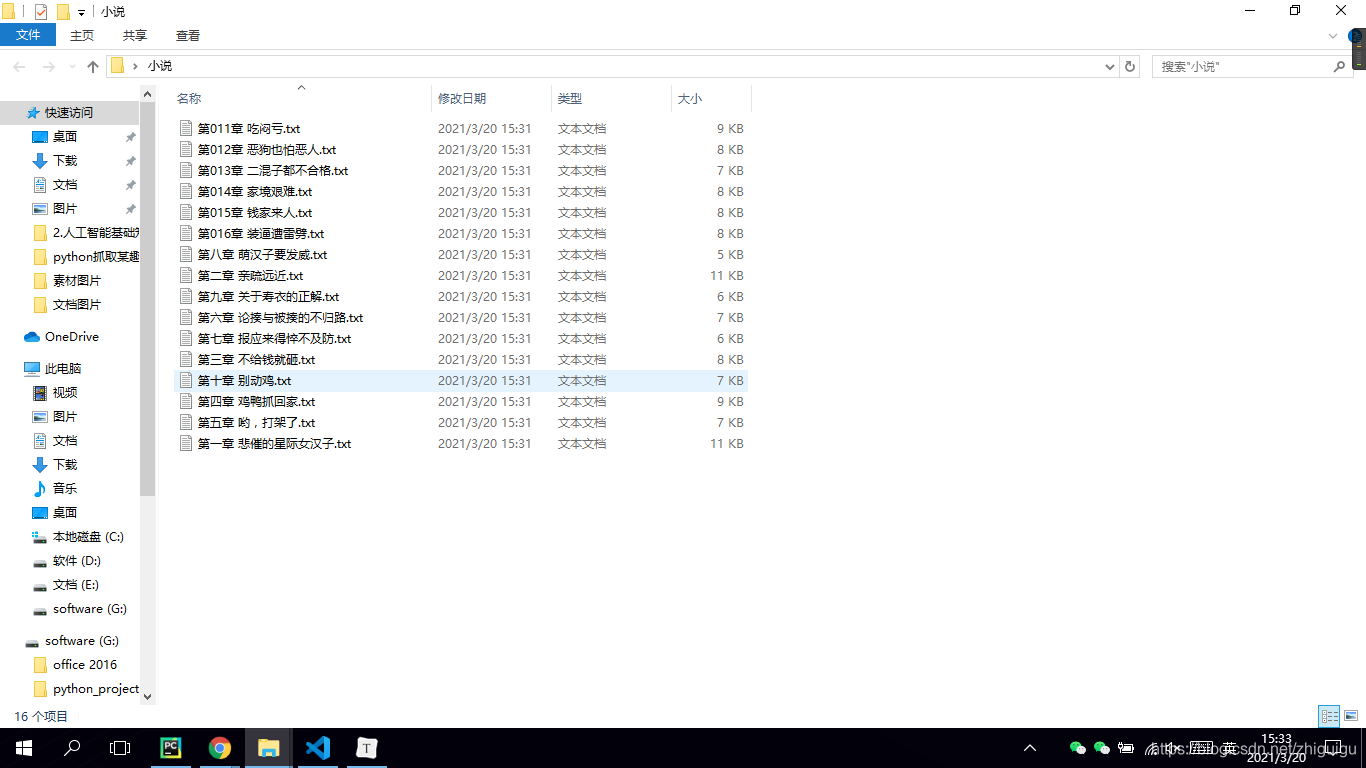
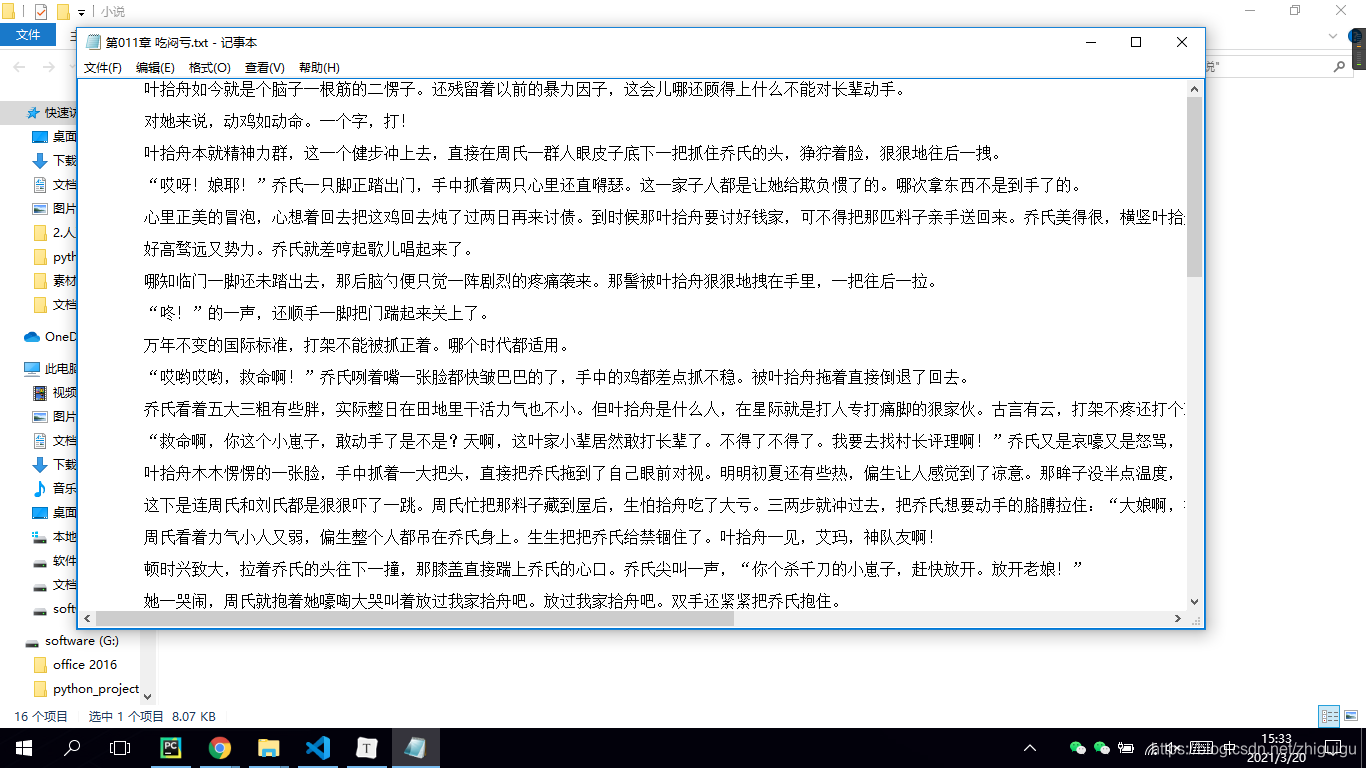
抓取的数据

文章正文到这里已经结束了,只是想感谢一些阅读我文章的人。
我退休后一直在学习如何写文章,说实在的,每次我在后台看到一些读者的回应就会觉得很欣慰,于是我想把我收藏的一些编程干货贡献给大家,回馈每一个读者,希望能帮到你们。
干货主要有:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门视频等等(适合小白学习)
*如果你用得到的话可以直接拿走,在我的QQ技术交流群里(广告勿入)可以自助拿走,群号是980758007。*

Python爬取笔趣阁小说,有趣又实用的更多相关文章
- bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html 模块:requests,bs4,queue,sys,time 步骤:给出URL--> 访问U ...
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言 首先先介绍一下Jsoup:(摘自官网) jsoup is a Java library for working with real-world HTML. It provides a very ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
随机推荐
- 栈的数组模拟(非STL)
#include<bits/stdc++.h> using namespace std; struct zhan{ int s[10000]; int top=0; void zhanpo ...
- 基于CefSharp开发浏览器(八)浏览器收藏夹栏
一.前言 上一篇文章 基于CefSharp开发(七)浏览器收藏夹菜单 简单实现了部分收藏夹功能 如(添加文件夹.添加收藏.删除.右键菜单部分功能) 后续代码中对MTreeViewItem进行了扩展,增 ...
- 大话Spark(7)-源码之Master主备切换
Master作为Spark Standalone模式中的核心,如果Master出现异常,则整个集群的运行情况和资源都无法进行管理,整个集群将处于无法工作的状态. Spark在设计的时候考虑到了这种情况 ...
- FreeBSD 12.2 vmware 虚拟机镜像 bt 种子
安装了 KDE5 火狐浏览器 Fcitx 输入法 并进行了中文设置 替换软件源为国内可用. VirtualBox虚拟机也可以用 magnet:?xt=urn:btih:E88885631B57426 ...
- Spring Boot 启动过程
一切从SpringApplication.run()开始,最终返回一个ConfigurableApplicationContext 构造了一个SpringApplication对象,然后调用它的run ...
- LeetCode 175. Combine Two Tables 【MySQL中连接查询on和where的区别】
一.题目 175. Combine Two Tables 二.分析 连接查询的时候要考虑where和on的区别 where : 查询时,连接的时候是必须严格满足条件的,满足了才会加入到临时表中. on ...
- mysql 统计新增每天数据
#创建基表 CREATE TABLE `table_sum` ( `id` int(11) NOT NULL AUTO_INCREMENT, `table_name` varchar(50) ...
- 2018ICPC南京D. Country Meow
题目: 题意:三维里有n个点,找一个最小的球将所有点覆盖. 题解:退火法模拟的一道板子题. 1 #include <stdio.h> 2 #include <iostream> ...
- JavaScript中函数防抖、节流
码文不易,转载请带上本文链接,感谢~ https://www.cnblogs.com/echoyya/p/14565642.html 目录 码文不易,转载请带上本文链接,感谢~ https://www ...
- springBoot高级:自动配置分析,事件监听,启动流程分析,监控,部署
知识点梳理 课堂讲义 02-SpringBoot自动配置-@Conditional使用 Condition是Spring4.0后引入的条件化配置接口,通过实现Condition接口可以完成有条件的加载 ...