大数据入门第二十五天——logstash入门
一、概述
1.logstash是什么
根据官网介绍:
Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
//属于elasticsearch旗下产品(JRuby开发,开发者曾说如果他知道有scala,就不会用jruby了。。)
也就是说,它是flume的“后浪”,它解决了“前浪”flume的数据丢失等问题!
2.基础结构
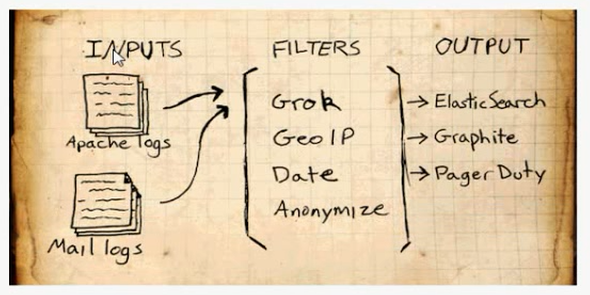
输入:采集各种来源数据
过滤:实时解析转换数据
输出:选择存储库导出数据
补充:Logstash 每读取一次数据的行为叫做事件。
更多详细介绍,包括具体支持的输入输出等,参考:https://www.elastic.co/guide/index.html
用法博文推荐:https://blog.csdn.net/chenleiking/article/details/73563930
二、安装
logstash5.x 6.x需要JDK1.8+,如未安装,请先安装JDK1.8+
1.下载
https://www.elastic.co/downloads/past-releases
选择合适的版本,下载即可
2.解压
[hadoop@mini1 ~]$ tar -zxvf logstash-5.6..tar.gz -C apps/
三、入门使用
1.HelloWorld示例
运行启动命令,并直接给出配置
bin/logstash -e 'input { stdin { } } output { stdout {} }'
常用的启动参数如下:
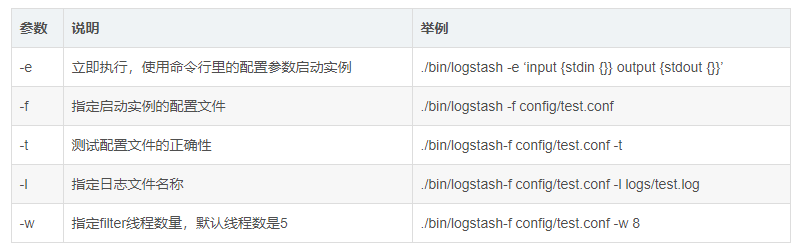
运行结果如下:输入helloworld,给出message消息:
[hadoop@mini1 logstash-5.6.]$ bin/logstash -e 'input { stdin { } } output { stdout {} }'
Sending Logstash's logs to /home/hadoop/apps/logstash-5.6.9/logs which is now configured via log4j2.properties
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/fb_apache/configuration"}
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/netflow/configuration"}
[--18T16::,][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/home/hadoop/apps/logstash-5.6.9/data/queue"}
[--18T16::,][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/home/hadoop/apps/logstash-5.6.9/data/dead_letter_queue"}
[--18T16::,][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"893c481c-85d1-4746-8562-48a74dcbad08", :path=>"/home/hadoop/apps/logstash-5.6.9/data/uuid"}
[--18T16::,][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>, "pipeline.batch.size"=>, "pipeline.batch.delay"=>, "pipeline.max_inflight"=>}
[--18T16::,][INFO ][logstash.pipeline ] Pipeline main started
The stdin plugin is now waiting for input:
[--18T16::,][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>}
HelloWorld
{
"@version" => "",
"host" => "mini1",
"@timestamp" => --18T08::.798Z,
"message" => "HelloWorld"
}
2.使用配置文件
实际中的 -e 后的配置一般相对更复杂,所以一般会通过 -f 使用配置文件来启动
bin/logstash -f logstash.conf
配置文件大概长这样:
# 输入
input {
...
} # 过滤器
filter {
...
} # 输出
output {
...
}
编写一个示例的配置文件:logstash.conf:
input {
# 从文件读取日志信息
file {
path => "/home/hadoop/apps/logstash-5.6.9/logs/1.log"
type => "system"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
stdout { codec => rubydebug }
}
输出结果如下:
[hadoop@mini1 logstash-5.6.]$ bin/logstash -f logstash.conf
Sending Logstash's logs to /home/hadoop/apps/logstash-5.6.9/logs which is now configured via log4j2.properties
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"fb_apache", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/fb_apache/configuration"}
[--18T16::,][INFO ][logstash.modules.scaffold] Initializing module {:module_name=>"netflow", :directory=>"/home/hadoop/apps/logstash-5.6.9/modules/netflow/configuration"}
[--18T16::,][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>, "pipeline.batch.size"=>, "pipeline.batch.delay"=>, "pipeline.max_inflight"=>}
[--18T16::,][INFO ][logstash.pipeline ] Pipeline main started
{
"@version" => "",
"host" => "mini1",
"path" => "/home/hadoop/apps/logstash-5.6.9/logs/1.log",
"@timestamp" => --18T08::.451Z,
"message" => "Apr 16 17:01:01 mini1 systemd: Started Session 5 of user root.",
"type" => "system"
}
四、插件的使用
logstash主要有3个主插件:输入input,输出output,过滤filter,其他还包括编码解码插件等
1.输入插件input
定义的数据源,支持从文件、stdin、kafka、twitter等来源,甚至可以自己写一个input plugin。
输入的file path等是支持通配的,例如:
path => "/data/web/logstash/logFile/*/*.log"
常用输入插件
1.file
file插件的必选参数只有path一项:部分选项如下:

// 原版的完整参数解释参见官网,中文参见上文博文参考处链接
配置示例:
input
file {
path => ["/var/log/*.log", "/var/log/message"]
type => "system"
start_position => "beginning"
}
}
2.过滤插件、输出插件
同输入插件类似,可以参考官网详细配置与参考博文
大数据入门第二十五天——logstash入门的更多相关文章
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- Spring入门第二十五课
使用具名参数 直接看代码: db.properties jdbc.user=root jdbc.password=logan123 jdbc.driverClass=com.mysql.jdbc.Dr ...
- 孤荷凌寒自学python第二十五天初识python的time模块
孤荷凌寒自学python第二十五天python的time模块 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 通过对time模块添加引用,就可以使用python的time模块来进行相关的时间操 ...
- 无废话ExtJs 入门教程十五[员工信息表Demo:AddUser]
无废话ExtJs 入门教程十五[员工信息表Demo:AddUser] extjs技术交流,欢迎加群(201926085) 前面我们共介绍过10种表单组件,这些组件是我们在开发过程中最经常用到的,所以一 ...
- NeHe OpenGL教程 第二十五课:变形
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- javaSE第二十五天
第二十五天 399 1:如何让Netbeans的东西Eclipse能访问. 399 2:GUI(了解) 399 (1)用户图形界面 399 (2)两个包: 399 (3) ...
- Bootstrap入门(十五)组件9:面板组件
Bootstrap入门(十五)组件9:面板组件 虽然不总是必须,但是某些时候你可能需要将某些 DOM 内容放到一个盒子里.对于这种情况,可以试试面板组件. 1.基本实例 2.带标题的面板 3.情景效果 ...
随机推荐
- AngularJS图片上传功能实践
逻辑理清楚了:service提供FileReader函数,directive提供点击事件的绑定和监听,controller用来修改html上的ng-src属性值 1.HTML <input ty ...
- structs2.8创建拦截器
控制层 public class PrintUsername { private String username; public String getUsername() { return usern ...
- 学习笔记(2)——实验室集群LVS配置
查看管理结点mgt的网卡信息,为mgt设置VIP [root@mgt ~]# ifconfig eth0 Link encap:Ethernet HWaddr 5C:F3:FC:E9:: inet a ...
- Android逆向 编写一个Android程序
本节使用的Android Studio版本是3.0.1 首先,我们先编写一个apk,后面用这个apk来进行逆向.用Android Studio创建一个新的Android项目,命名为Jhm,一路Next ...
- Android 经典欧美小游戏 guess who
本来是要做iOS开发的,因为一些世事无常和机缘巧合与测试工作还有安卓系统结下了不解之缘,前不久找到了guess who 源码,又加入了一些自己的元素最终完成了这个简单的小游戏. <?xml ve ...
- 【Java入门提高篇】Day19 Java容器类详解(二)Map接口
上一篇里介绍了容器家族里的大族长——Collection接口,今天来看看容器家族里的二族长——Map接口. Map也是容器家族的一个大分支,但里面的元素都是以键值对(key-value)的形式存放的, ...
- 机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析
机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析 关键字:Apriori.关联规则挖掘.频繁项集作者:米仓山下时间:2018 ...
- 安装SQL sever2008时显示重新启动计算机规则失败,应该怎么解决?
1.删除注册表:在HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Session Manager中找到 PendingFileRenameOpe ...
- [IDEA_6] IDEA 集成 Python
0. 说明 在 IDEA 中集成 Python 1. IDEA 集成 Python 1.1 Ctrl + Alt + S 进入设置 依次选中 Settings --> Plugins -- ...
- RecyclerView使用技巧(item动画及嵌套高度适配解决方案)
原文地址 · Frank-Zhu http://frank-zhu.github.io/android/2015/02/26/android-recyclerview-part-3/?utm_sou ...