从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用
Json
- 一种轻量级的数据交换格式,通用,跨平台
- 键值对的集合,值的有序列表
- 类似于python中的dict
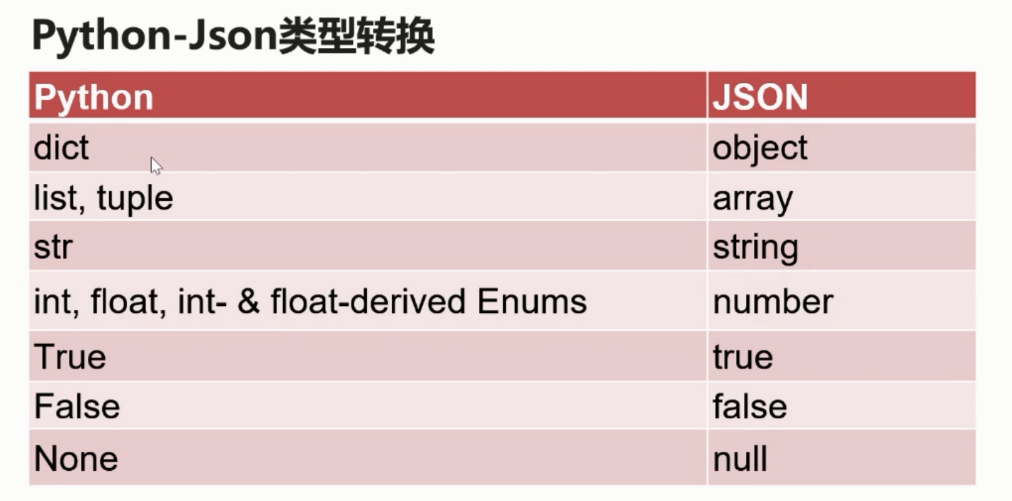
Json中的键值如果是字符串一定要用双引号
json文件static/book.json
{
"name": "Python书籍",
"origin_price": ,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东","淘宝"],
"author": ["张三","李四","Jhone"],
"is_valid":true,
"is_sale": false,
"meta":{
"isbn":"abc-123",
"pages":
},
"desc":null
}
Json的常用方法练习use_json.py
#coding=utf-8 import json def python_to_json():
"""将python对象转换成json"""
d = {
'name': 'python书籍',
'price':62.3,
'is_valid': True
}
# intend是加入缩进效果
rest = json.dumps(d, indent=4)
print(rest) def json_to_python():
""" 将json转换成python """
data = '''
{
"name": "Python书籍",
"origin_price": 66,
"pub_date": "2018-4-14 17:00:00",
"store": ["京东","淘宝"],
"author": ["张三","李四","Jhone"],
"is_valid":true,
"is_sale": false,
"meta":{
"isbn":"abc-123",
"pages":300
},
"desc":null
}
'''
rest = json.loads(data)
print(rest) def json_to_python_from_file():
"""从文件读取内容并转换为python对象"""
f = open('./static/book.json', 'r', encoding='utf-8') s = f.read()
print(s)
rest = json.loads(s)
print(rest["name"]) f.close() if __name__ == '__main__':
python_to_json()
# json_to_python()
# json_to_python_from_file()
从0开始学爬虫2之json的介绍和使用的更多相关文章
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片 # coding=utf-8 import requests def download_imgage(): ''' demo: 下载图片 ''' h ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫10之urllib和requests库与github/api的交互
urllib库的使用 # coding=utf-8 import urllib2 import urllib # htpbin模拟的环境 URL_IP="http://10.11.0.215 ...
- 从0开始学爬虫7之BeautifulSoup模块的简单介绍
参考文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ # 安装 beautifulsoup4 (pytools) D:\pyt ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
随机推荐
- 让 Python 代码更易维护的七种武器——代码风格(pylint、Flake8、Isort、Autopep8、Yapf、Black)测试覆盖率(Coverage)CI(JK)
让 Python 代码更易维护的七种武器 2018/09/29 · 基础知识 · 武器 原文出处: Jeff Triplett 译文出处:linux中国-Hank Chow 检查你的代码的质 ...
- 怎么保证redis集群的高并发和高可用的?
redis不支持高并发的瓶颈在哪里? 单机.单机版的redis支持上万到几万的QPS不等. 主要根据你的业务操作的复杂性,redis提供了很多复杂的操作,lua脚本. 2.如果redis要支撑超过10 ...
- Flume拦截器、监控器
一.拦截器 1.拦截器:拦截器主要作用在source和channel之间,用于给event设置header消息头,如果没有设置拦截器,则event中只有message. 常见的拦截器有: Timest ...
- [React] Write a Custom React Effect Hook
Similar to writing a custom State Hook, we’ll write our own Effect Hook called useStarWarsQuote, whi ...
- 2:tomcat配置优化
一.Tomcat配置优化 1.Tomcat配置调优 主要调优内容 增加最大连接数 调整工作模式 启用gzip压缩 调整JVM内存大小 作为Web时,动静分离 合理选择垃圾回收算法 尽量使用较新JDK版 ...
- MongoDB 查看集合的统计信息
和 RDBMS 一样, MongoDB 同样存储集合的统计信息,通过调用命令 db.collection.stats() 可以方便的查看集合的统计信息. --1 查看集合 things 的统计信息 r ...
- UVA 11468 Substring (记忆化搜索 + AC自动鸡)
传送门 题意: 给你K个模式串, 然后,再给你 n 个字符, 和它们出现的概率 p[ i ], 模式串肯定由给定的字符组成. 且所有字符,要么是数字,要么是大小写字母. 问你生成一个长度为L的串,不包 ...
- 鼠标经过图片会移动(css3过渡,overflow:hidden)
效果图如下: 代码: <body> <div><img src="jd.jpg"></div> </body> img{ ...
- WAMP 403 Forbidden禁止访问,别的电脑访问不了;
直接上图: 1:修改httpd.conf; deny from all 改成------ allow from all 重启服务就好了: 2:如果搜不到deny from all 就按照下面的方法来 ...
- Vim初学
实现G++编译 1,首先下载安装MinGW,下载地址在http://sourceforge.net/projects/mingw/.这个是边下载边安装的,下载完成即安装完成.我的安装目录是G:\Min ...